哈夫曼树及哈夫曼编码详解【完整版代码】
Huffman Tree简介
赫夫曼树(Huffman Tree),又称最优二叉树,是一类带权路径长度最短的树。假设有n个权值{w1,w2,...,wn},如果构造一棵有n个叶子节点的二叉树,而这n个叶子节点的权值是{w1,w2,...,wn},则所构造出的带权路径长度最小的二叉树就被称为赫夫曼树。
这里补充下树的带权路径长度的概念。树的带权路径长度指树中所有叶子节点到根节点的路径长度与该叶子节点权值的乘积之和,如果在一棵二叉树中共有n个叶子节点,用Wi表示第i个叶子节点的权值,Li表示第i个也叶子节点到根节点的路径长度,则该二叉树的带权路径长度 WPL=W1*L1 + W2*L2 + ... Wn*Ln。
根据节点的个数以及权值的不同,赫夫曼树的形状也各不相同,赫夫曼树具有如下特性:
- 对于同一组权值,所能得到的赫夫曼树不一定是唯一的。
- 赫夫曼树的左右子树可以互换,因为这并不影响树的带权路径长度。
- 带权值的节点都是叶子节点,不带权值的节点都是某棵子二叉树的根节点。
- 权值越大的节点越靠近赫夫曼树的根节点,权值越小的节点越远离赫夫曼树的根节点。
- 赫夫曼树中只有叶子节点和度为2的节点,没有度为1的节点。
- 一棵有n个叶子节点的赫夫曼树共有2n-1个节点。
Huffman Tree的构建
赫夫曼树的构建步骤如下:
1、将给定的n个权值看做n棵只有根节点(无左右孩子)的二叉树,组成一个集合HT,每棵树的权值为该节点的权值。
2、从集合HT中选出2棵权值最小的二叉树,组成一棵新的二叉树,其权值为这2棵二叉树的权值之和。
3、将步骤2中选出的2棵二叉树从集合HT中删去,同时将步骤2中新得到的二叉树加入到集合HT中。
4、重复步骤2和步骤3,直到集合HT中只含一棵树,这棵树便是赫夫曼树。
假如给定如下5个权值:
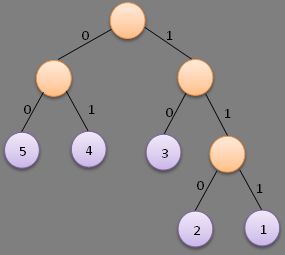
则按照以上步骤,可以构造出如下面左图所示的赫夫曼树,当然也可能构造出如下面右图所示的赫夫曼树,这并不是唯一的。


Huffman编码
赫夫曼树的应用十分广泛,比如众所周知的在通信电文中的应用。在等传送电文时,我们希望电文的总长尽可能短,因此可以对每个字符设计长度不等的编码,让电文中出现较多的字符采用尽可能短的编码。为了保证在译码时不出现歧义,我们可以采取如下图所示的编码方式:
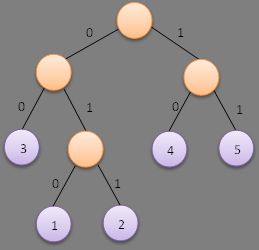
即左分支编码为字符0,右分支编码为字符1,将从根节点到叶子节点的路径上分支字符组成的字符串作为叶子节点字符的编码,这便是赫夫曼编码。我们根据上面左图可以得到各叶子节点的赫夫曼编码如下:
权值为5的节点的赫夫曼编码为:11
权值为4的节点的赫夫曼编码为:10
权值为3的节点的赫夫曼编码为:00
权值为2的节点的赫夫曼编码为:011
权值为1的节点的赫夫曼编码为:010
而对于上面右图,则可以得到各叶子节点的赫夫曼编码如下:
权值为5的节点的赫夫曼编码为:00
权值为4的节点的赫夫曼编码为:01
权值为3的节点的赫夫曼编码为:10
权值为2的节点的赫夫曼编码为:110
权值为1的节点的赫夫曼编码为:111
最小带权路径长度(左图):WPL=2*3+3*1+3*2+2*4+2*5=33
最小带权路径长度(右图):WPL=2*5+2*4+2*3+3*2+3*1=33
由此可见,不管是左子树权值大于右子树权值还是小于右子树权值的哈夫曼树的最小带权路径长度不变。
最小带权路径长度(右图):WPL=2*5+2*4+2*3+3*2+3*1=33
由此可见,不管是左子树权值大于右子树权值还是小于右子树权值的哈夫曼树的最小带权路径长度不变。
Huffman编码的C实现
由于赫夫曼树中没有度为1的节点,则一棵具有n个叶子节点的的赫夫曼树共有2n-1个节点(最后一条特性),因此可以将这些节点存储在大小为2n-1的一维数组中。我们可以用以下数据结构来表示赫夫曼树和赫夫曼编码:
/*
赫夫曼二叉树的存储结构,它也是一种二叉树结构,
这种存储结构既适合表示树,也适合表示森林。
*/
typedef struct Node
{
int weight; //权值
int parent; //父节点的序号,为-1的是根节点
int lchild, rchild; //左右孩子节点的序号,为-1的是叶子节点
}HTNode, *HuffmanTree; //用来存储赫夫曼树中的所有节点
从叶子结点开始遍历二叉树求最小带权路径长度WPL
/*
从叶子结点开始遍历二叉树直到根结点,根结点为HT[2n-1],且HT[2n-1].parent=-1;
各叶子结点为HT[0]、HT[1]...HT[n-1]。
关键步骤是求出各个叶子结点的路径长度,用此路径长度*此结点的权值就是
此结点带权路径长度,最后将各个叶子结点的带权路径长度加起来即可。
*/
int countWPL1(HuffmanTree HT, int n)
{
int i,countRoads,WPL=0;
/*
由creat_huffmanTree()函数可知,HT[0]、HT[1]...HT[n-1]存放的就是各个叶子结点,
所以挨个求叶子结点的带权路径长度即可
*/
for (i = 0; i < n; i++)
{
int father = HT[i].parent; //当前节点的父节点
countRoads = 0;//置当前路径长度为0
//从叶子节点遍历赫夫曼树直到根节点
while (father != -1)
{
countRoads++;
father = HT[father].parent;
}
WPL += countRoads * HT[i].weight;
}
return WPL;
}
从根结点开始遍历二叉树求最小带权路径长度WP:
/*
以下是从根结点开始遍历二叉树,求最小带权路径长度。关键步骤是求出各个叶子
结点的路径长度,用此路径长度*此结点的权值就是此结点带权路径长度,最后将
各个叶子结点的带权路径长度加起来即可。
*/
int countWPL2(HuffmanTree HT, int n)
{
int cur = 2 * n - 2; //当前遍历到的节点的序号,初始时为根节点序号
int countRoads=0, WPL=0;//countRoads保存叶子结点的路径长度
//构建好赫夫曼树后,把visit[]用来当做遍历树时每个节点的状态标志
//visit[cur]=0表明当前节点的左右孩子都还没有被遍历
//visit[cur]=1表示当前节点的左孩子已经被遍历过,右孩子尚未被遍历
//visit[cur]=2表示当前节点的左右孩子均被遍历过
int visit[maxSize] = { 0 };//visit[]是标注数组,初始化为0
//从根节点开始遍历,最后回到根节点结束
//当cur为根节点的parent时,退出循环
while (cur != -1)
{
//左右孩子均未被遍历,先向左遍历
if (visit[cur]==0)
{
visit[cur] = 1; //表明其左孩子已经被遍历过了
if (HT[cur].lchild != -1)
{ //如果当前节点不是叶子节点,则路径长度+1,并继续向左遍历
countRoads++;
cur = HT[cur].lchild;
}
else
{ //如果当前节点是叶子节点,则计算此结点的带权路径长度,并将其保存起来
WPL += countRoads * HT[cur].weight;
}
}
//左孩子已被遍历,开始向右遍历右孩子
else if (visit[cur]==1)
{
visit[cur] = 2;
if (HT[cur].rchild != -1)
{ //如果当前节点不是叶子节点,则记下编码,并继续向右遍历
countRoads++;
cur = HT[cur].rchild;
}
}
//左右孩子均已被遍历,退回到父节点,同时路径长度-1
else
{
visit[cur] = 0;
cur = HT[cur].parent;
--countRoads;
}
}
return WPL;
}
c语言版完整代码(第一种,如上图左图,左孩子权值小于右孩子权值):
#include- 测试结果为:
从叶子结点开始遍历二叉树求最小带权路径长度WPL=33
从根结点开始遍历二叉树求最小带权路径长度WPL=33
从叶子到根结点编码结果为:
11
10
00
011
010
从根结点到叶子结点编码结果为:
11
10
00
011
010
Press any key to continue . . .
c语言版完整代码(第二种,如上图右图,左孩子权值大于右孩子权值):
有读者反应这个是有点问题的,其实只是huffman树的构建不同。树的形态不同是允许的,huffman编码不是唯一的,但WPL一定是唯一的。
因为1+2=3和3节点相等,第一个3应该放在右边,程序里面运行后是左边,所以输出的是那样的,加一个判断就好了。我现在没有时间去更新,等有空了更新一下。原理明白就行了。
其实哈夫曼树被设计出来主要用于压缩文件,不管放在右边还是左边都起到了压缩的目的,结果是一样的。
//对于这种方式构建huffman树,只需将上面的完整版代码更改两句
HuffmanTree create_HuffmanTree(int *wet, int n)
{ ...
...
HT[i].lchild = min1;
HT[i].rchild = min2;
...
...
}
改为:
HT[i].rchild = min1;
HT[i].lchild = min2;
/*把每次选出来权值最小的结点作在右孩子*/
- 测试结果为:
从叶子结点开始遍历二叉树求最小带权路径长度WPL=33
从根结点开始遍历二叉树求最小带权路径长度WPL=33
从叶子到根结点编码结果为:
00
01
11
100
101
从根结点到叶子结点编码结果为:
00
01
11
100
101
Press any key to continue . . .
另外,以上是哈夫曼二叉树的构建及编码,提到哈夫曼树,不仅仅指哈夫曼二叉树,还有哈夫曼n叉树(n>=2)。
下图是哈夫曼三叉树的简单介绍:


以上内容大部分参考于此
