散点图
#导入必要的模块
import numpy as np
import matplotlib.pyplot as plt
#产生测试数据
x = np.arange(1,10)
y = x
fig = plt.figure()
ax1 = fig.add_subplot(111)
#设置标题
ax1.set_title('Scatter Plot')
#设置X轴标签
plt.xlabel('X')
#设置Y轴标签
plt.ylabel('Y')
#画散点图
ax1.scatter(x,y,c = 'r',marker = 'o')
#设置图标
plt.legend('x1')
#显示所画的图
plt.show()

折线图
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 10)
y1, y2 = np.sin(x), np.cos(x)
plt.plot(x, y1, 'ro-')
plt.plot(x, y2, 'g*:', ms=10)
plt.show()

柱状图
import numpy as np
import matplotlib.pyplot as plt
size = 5
a = np.random.random(size)
b = np.random.random(size)
c = np.random.random(size)
d = np.random.random(size)
x = np.arange(size)
total_width, n = 0.8, 3 # 有多少个类型,只需更改n即可
width = total_width / n
x = x - (total_width - width) / 2
plt.bar(x, a, width=width, label='a')
plt.bar(x + width, b, width=width, label='b')
plt.bar(x + 2 * width, c, width=width, label='c')
plt.legend()
plt.show()
饼状图
import numpy as np
import matplotlib.pyplot as plt
labels = 'A', 'B', 'C', 'D'
fracs = [15, 30.55, 44.44, 10]
explode = [0, 0.1, 0, 0] # 0.1 凸出这部分,
plt.axes(aspect=1) # set this , Figure is round, otherwise it is an ellipse
#autopct ,show percet
plt.pie(x=fracs, labels=labels, explode=explode,autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle = 90,pctdistance = 0.6
)
'''
labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
shadow,饼是否有阴影
startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
pctdistance,百分比的text离圆心的距离
patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
'''
plt.show()

气泡图
import pandas as pd
from matplotlib import pyplot as plt
crime=pd.read_csv("crimeRatesByState2005.csv")
fig,ax=plt.subplots(figsize=(10,5))
crime=crime[1:]
population=crime["population"].values
state=crime["state"].values
murder=crime["murder"].values
burglary=crime["burglary"].values
ax.scatter(murder,burglary,s=population/40000,alpha=0.6)
ax.set(xlim=(0,11),ylim=(200,1300),\
xlabel="Murder per 100,000 population",\
ylabel="Burglary per 100,000 population",\
title="Murder & Burglary in USA")
for i,j,z in zip(murder,burglary,state):
ax.text(x=i-0.3,y=j-0.1,s=z,fontsize=7)
ax.spines["top"].set_visible(False)
ax.spines["left"].set_visible(False)
ax.spines["right"].set_visible(False)
plt.show()

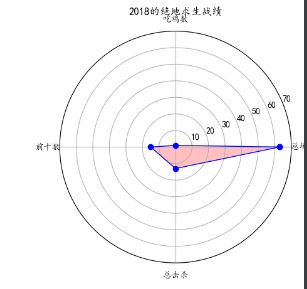
雷达图
# encoding: utf-8
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['KaiTi'] # 显示中文
labels = np.array([u'总场次', u'吃鸡数', u'前十数',u'总击杀']) # 标签
dataLenth = 4 # 数据长度
data_radar = np.array([63, 1, 15, 13]) # 数据
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) # 分割圆周长
data_radar = np.concatenate((data_radar, [data_radar[0]])) # 闭合
angles = np.concatenate((angles, [angles[0]])) # 闭合
plt.polar(angles, data_radar, 'bo-', linewidth=1) # 做极坐标系
plt.thetagrids(angles * 180/np.pi, labels) # 做标签
plt.fill(angles, data_radar, facecolor='r', alpha=0.25)# 填充
plt.ylim(0, 70)
plt.title(u'2018的绝地求生战绩')
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
print(unrate.head())
# pd.to_datetime() 将数据转换成datetime类型
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
print(unrate.head(12))
# plt.plot()画折线图
plt.plot()
# plt.show()显示图形
plt.show()
DATE VALUE
0 1948/1/1 3.4
1 1948/2/1 3.8
2 1948/3/1 4.0
3 1948/4/1 3.9
4 1948/5/1 3.5
DATE VALUE
0 1948-01-01 3.4
1 1948-02-01 3.8
2 1948-03-01 4.0
3 1948-04-01 3.9
4 1948-05-01 3.5
5 1948-06-01 3.6
6 1948-07-01 3.6
7 1948-08-01 3.9
8 1948-09-01 3.8
9 1948-10-01 3.7
10 1948-11-01 3.8
11 1948-12-01 4.0

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
first_twelve = unrate[0:12]
print (first_twelve)
plt.plot(first_twelve['DATE'], first_twelve['VALUE'])
plt.show()
DATE VALUE 0 1948/1/1 3.4 1 1948/2/1 3.8 2 1948/3/1 4.0 3 1948/4/1 3.9 4 1948/5/1 3.5 5 1948/6/1 3.6 6 1948/7/1 3.6 7 1948/8/1 3.9 8 1948/9/1 3.8 9 1948/10/1 3.7 10 1948/11/1 3.8 11 1948/12/1 4.0

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
first_twelve = unrate[0:12]
plt.plot(first_twelve['DATE'], first_twelve['VALUE'])
# plt.xticks设置x轴坐标,rotation设置x刻度旋转角度
plt.xticks(rotation=45)
#print (help(plt.xticks))
plt.show()

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
first_twelve = unrate[0:12]
plt.plot(first_twelve['DATE'], first_twelve['VALUE'])
plt.plot(first_twelve['DATE'], first_twelve['VALUE'])
# plt.xticks设置x轴坐标,rotation设置x刻度旋转角度
plt.xticks(rotation=90)
# plt.xlabel()设置x轴标题
#plt.xlabel('Month')
plt.xlabel('月份')
#plt.ylabel('Unemployment rate')
plt.ylabel('失业率')
# plt.title()设置标题
plt.title('1948年失业率走势')
plt.show()

2.子图
在一张纸上画多张图
import matplotlib.pyplot as plt
# 创建画板
fig = plt.figure()
#.add_subplot添加子图
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
#ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
#ax4 = fig.add_subplot(224)
plt.show()
import matplotlib.pyplot as plt
import numpy as np
# 创建画板
fig = plt.figure()
#fig = plt.figure(figsize=(8, 15))#figsize=(8, 15)设置画板大小
#.add_subplot添加子图
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.plot(np.random.randint(1,5,5), np.arange(5))
# np.random.randint(low,high,size),生成在[low,high)随机整数,low默认是0,size是元素个数,size是元组时,生成矩阵
ax2.plot(np.arange(10)*3, np.arange(10))
plt.show()

# 随机生成 5 个整数的 5 个整数
print(np.random.randint(1,5,5))
# 随机生成 1 到 5 的整数, 3 行 3 列
print(np.random.randint(1,5,(3,3)))
[2 3 2 2 2] [[4 4 2] [1 2 4] [1 3 2]]
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# dt.month获取datetime类型值的月份
unrate['MONTH'] = unrate['DATE'].dt.month
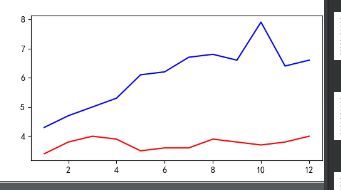
fig = plt.figure(figsize=(6,3))
plt.plot(unrate[0:12]['MONTH'], unrate[0:12]['VALUE'], c='r')
plt.plot(unrate[12:24]['MONTH'], unrate[12:24]['VALUE'], c='blue')
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# dt.month获取datetime类型值的月份
unrate['MONTH'] = unrate['DATE'].dt.month
fig = plt.figure(figsize=(10, 6))
colors = ['red', 'blue', 'green', 'orange', 'black']
for i in range(5):
start_index = i * 12
end_index = (i + 1) * 12
subset = unrate[start_index:end_index]
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i]) # c设置颜色
plt.show()

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# dt.month获取datetime类型值的月份
unrate['MONTH'] = unrate['DATE'].dt.month
fig = plt.figure(figsize=(10,6))
colors = ['red', 'blue', 'green', 'orange', 'black']
for i in range(5):
start_index = i*12
end_index = (i+1)*12
subset = unrate[start_index:end_index]
label = str(1948 + i)
# linewidth设置线宽
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i], label=label,linewidth=10)
plt.legend(loc='upper left')
plt.xticks(size=15)
plt.yticks(size=15)
plt.xlabel('Month, Integer',size=20)
plt.ylabel('Unemployment Rate, Percent')
plt.title('Monthly Unemployment Trends, 1948-1952')
plt.show()

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 读取本地 unrate.csv 文件
unrate = pd.read_csv('unrate.csv')
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# dt.month获取datetime类型值的月份
unrate['MONTH'] = unrate['DATE'].dt.month
plt.figure(figsize=(10,6))
x = np.arange(-2*np.pi,2*np.pi,0.01)
#x = np.arange(-2*np.pi,2*np.pi,0.01)
x1 = np.arange(-2*np.pi,2*np.pi,0.2)
y = np.sin(3*x1)/x1
y2 = np.sin(2*x)/x
y3 = np.sin(x)/x
# linestyle设置线的风格,marker设置点的风格
plt.plot(x1,y,c='b',linestyle='--',marker='^')
plt.plot(x,y2,c='r',linestyle='-.')
plt.plot(x,y3,c='g')
ax = plt.gca() # 获取Axes对象
#plt.gca().spines[]图的边框,set_color()设置边框的颜色
#ax.spines['right'].set_color('none')
#ax.spines['top'].set_color('none')
#ax.xaxis.set_ticks_position('bottom')
# ax.spines['bottom']获取下边框,即x轴,set_position设置轴的位置
#ax.spines['bottom'].set_position(('data',0))
#ax.yaxis.set_ticks_position('left')
# #ax.spines['left']获取左边框,即y轴
#ax.spines['left'].set_position(('data',0))
# 设置要显示的刻度值
#plt.xticks([-2*np.pi,-np.pi,0,np.pi,2*np.pi])
# 设置要显示的刻度值,并将其进行替换成自定义字符串
#plt.xticks([-2*np.pi,-np.pi,0,np.pi,2*np.pi],['-2π','π','0','π','2π'],size=15)
# 设置x轴坐标范围
#plt.xlim((-np.pi,np.pi))
# 设置y轴坐标范围
#plt.ylim((0,3))
plt.show()

3.柱形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from numpy import arange
li = [1.2, 2.2, 1.5, 4.5, 2.5]
bar_positions = arange(5) + 1
print (bar_positions)
print (type(bar_positions))
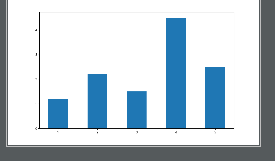
plt.figure(figsize=(10,6))
# plt.bar ()画柱状图
plt.bar(bar_positions, li, 0.5)
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from numpy import arange
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
li = [1.2, 2.2, 1.5, 4.5, 2.5]
bar_positions = arange(5) + 1
print (bar_positions)
plt.figure(figsize=(10,6))
plt.bar(bar_positions, li, 0.5,color=['r','g','b'])
plt.xticks(bar_positions,num_cols,rotation=0, size=10)
plt.xlabel('Rating Source')
plt.ylabel('Average Rating')
plt.title('Average User Rating For Avengers: Age of Ultron (2015)')
for x,y in zip(bar_positions,li):#设置在柱子上显示文字注释
plt.text(x,y,'%.2f'%y,ha="center", va="bottom",size=14)
#plt.text()设置添加图中文本注释,依次传入坐标和字符串内容,size设置字的大小
#ha设置horizontalalignment水平对齐方式,va设置verticalalignment:垂直对齐方式
plt.show()

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from numpy import arange
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
li = [1.2, 2.2, 1.5, 4.5, 2.5]
bar_positions = arange(5) + 1
print (bar_positions)
bar_positions = arange(5) + 1
plt.figure(figsize=(10,6))
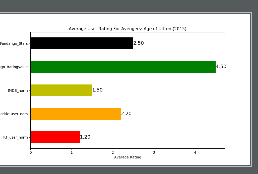
plt.barh(bar_positions,li, 0.5,color=['r','orange','y','g','k'])
plt.yticks(bar_positions,num_cols,rotation=0, size=10)
plt.xlabel('Average Rating')
plt.ylabel('Rating Source')
plt.title('Average User Rating For Avengers: Age of Ultron (2015)')
for x,y in zip(li,bar_positions):#设置在柱子上显示文字注释
plt.text(x,y,'%.2f'%x,ha="left", va="center",size=14)
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from numpy import arange
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
pdData = pd.read_csv('pandas作业.csv')
positive = pdData[pdData['Admitted'] == 1]
negative = pdData[pdData['Admitted'] == 0]
fig = plt.figure(figsize=(10,5))
plt.scatter(positive['Exam1'], positive['Exam2'], s=30, c='b', marker='o', label='通过')
# s设置点的大小,c设置颜色,marker设置点的形状,label设置图例
plt.scatter(negative['Exam1'], negative['Exam2'], s=30, c='r', marker='x', label='淘汰')
plt.legend()#显示图例
plt.xlabel('科目1分数')#设置横坐标标题
plt.ylabel('科目2分数')
