一文读懂如何基于BiLSTM+Attention模型完成实体关系抽取(pytorch)-详细步骤版
知识图谱本体层构建好之后,就需要向本体层内输入相应的数据层。知识图谱数据层一般包含实体、实体属性、实体之间的关系。
上一篇介绍了如何对数据集中的实体进行识别,主要使用的是CRF模型。
关系抽取是在实体抽取的基础上所进行的,也属于知识图谱构建中知识抽取的一部分。
这一篇介绍对数据集中的人物实体关系进行抽取,主要使用的是BiLSTM+Attention模型。文章目录如下:
文章目录
- 一、任务描述
- (一)输入
- 1.预定义人物关系类别(这是我们要抽取的关系)
- 2.数据集文档D(这是模型训练资源和识别的目标)
- (二)输出
- (三)评价标准
- 二、BiLSTM+Attention模型介绍
- (一)BiLSTM
- (二)Attention
- 三、数据预处理
- (一)整体思路
- (二)具体步骤
- 四、模型训练、模型测试、结果评测
- (一)dataloader和model准备
- (二)模型训练、模型测试、结果评测实施
- 五、总结与展望
- (一)体会
- (二)关于代码中阈值的几点思考
- (三)关于模型的思考
- (四)其他问题
一、任务描述
(一)输入
1.预定义人物关系类别(这是我们要抽取的关系)
unknown 0
父母 1
夫妻 2
师生 3
兄弟姐妹 4
合作 5
情侣 6
祖孙 7
好友 8
亲戚 9
同门 10
上下级 11
2.数据集文档D(这是模型训练资源和识别的目标)
名称:自建的人物关系数据集,txt格式,30.8M,共7933行文本。截图如下:

关于训练数据集的三点说明:
- 这个训练数据集,是一份网上公开的数据集,已对所有句子关系进行了标注,人物双方的名字被标注到前两列,以及我们所需要抽取的这两个人物的关系:父母妻子师生等,已经分别被标注为到第三列。
- 若是用自己的数据集需要自己标注。
- 一般实验环境多采用人工标注少量专业领域的方式进行,工业领域一般选择众包和从其他数据源利用规则策略两种方式构造标注数据集。
(二)输出
数据集文档经过模型抽取后,输出被模型所标记过的文档,也就是用模型标记12个关系后的文档。
(三)评价标准
F1值,一般选取F1值作为评价标准
在这里我们用BiLSTM+Attention模型来完成这次任务,具体如下:
二、BiLSTM+Attention模型介绍
(一)BiLSTM
1.BiLSTM概念
(1)RNN的全称是Recurrent Neural Network,循环神经网络RNN。是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
RNN的方法是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。
(2)LSTM的全称是Long Short-Term Memory,长短期记忆网络。长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM对RNN做了改进,使得其能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。
(3)BiLSTM全称是Bi-directional Long Short-Term Memory,双向长短期记忆网络。是由前向LSTM与后向LSTM组合而成。两者在自然语言处理任务中都常被用来建模上下文信息。
2.优势
将词的表示组合成句子的表示,可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法,但是这些方法没有考虑到词语在句子中前后顺序。如句子“我不觉得他好”。“不”字是对后面“好”的否定,即该句子的情感极性是贬义。使用LSTM模型可以更好的捕捉到较长距离的依赖关系。因为LSTM通过训练过程可以学到记忆哪些信息和遗忘哪些信息。
但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
为什么使用LSTM与BiLSTM?
如果我们想要句子的表示,可以在词的表示基础上组合成句子的表示,那么我们可以采用相加的方法,即将所有词的表示进行加和,或者取平均等方法。但是这些方法很大的问题是没有考虑到词语在句子中前后顺序。而使用LSTM模型可以更好的捕捉到较长距离的依赖关系。因为LSTM通过训练过程可以学到记忆哪些信息和遗忘哪些信息。但是利用LSTM对句子进行建模也存在一个问题:无法编码从后到前的信息。而通过BiLSTM可以更好的捕捉双向的语义依赖。
(二)Attention
Attention层:其实就是对双向LSTM的结果使用Attention加权。不同于传统的最后只要hr,而是加权生成结果,模型整体如下:
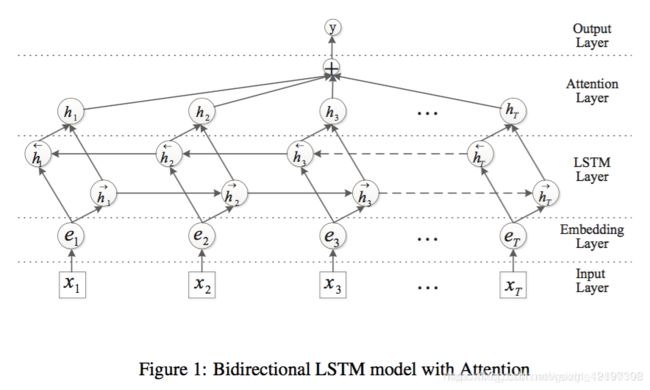
以上是对BiLSTM+Attention模型的简单会回顾,如果你一点也不了解这个模型,或者都不了解深度学习,也没关系,先看懂下面的实例,再看另三篇文章:《一文读懂神经网络》、《一文读懂循环神经网络RNN》、《一文读懂循环神经网络中的BILSTM》即可。
三、数据预处理
(一)整体思路
(1)对文本按行进行处理,处理前XX行
(2)每行得到3个向量(该行所有字的字向量、该行所有字的位置向量1、该行所有字的位置向量2)和1个关系值:
(3)将所有行的3个向量集合和1个关系集合,4样东西,作为模型训练集输入
(4)按上述(1)(2)(3)步,处理文本后XX行,得出模型测试集
(二)具体步骤
第1步,打开relation2id.txt文,将预定义的12种关系,放入字典变量relation2id中,并给每个关系key一个对应的数字value,关键代码如下:
with codecs.open('relation2id.txt','r','utf-8') as input_data:
#循环读取input_data变量,放入字典relation2id{}中
for line in input_data.readlines():
#line.split() ,表示以空格为分隔符进行字符串分割,包含 \n
relation2id[line.split()[0]] = int(line.split()[1])
input_data.close()
查询,得到字典变量relation2id如下:
relation2id[]={'unknown': 0, '父母': 1, '夫妻': 2, '师生': 3, '兄弟姐妹': 4, '合作': 5, '情侣': 6, '祖孙': 7, '好友': 8}
第2步,打开训练文本train.txt,对文本按行全部循环读取,得到每一行文本。这里的处理设置了一个阈值,处理每种关系的次数限制1500次,当这个关系出现1500次以后就不处理了(这部分文本行为了留给后续的测试集用,后面会说到),关键代码如下:
# 将train.txt中的数据以行为单位输入到变量tfc中,每一行是一个列表
with codecs.open('train.txt','r','utf-8') as tfc:
# 对tfc进行按行循环处理,
for lines in tfc: #lines ='朱时茂 陈佩斯 合作 《水与火的缠绵》《低头不见抬头见》《天剑群侠》小品陈佩斯与朱时茂1984年《吃面条》合作者:陈佩斯聽1985年《拍电影》
#对每一行,按空格进行字符串分割
line = lines.split()
以第一行为例,查询,结果如下:
line=<class 'list'>: ['朱时茂', '陈佩斯', '合作', '《水与火的缠绵》《低头不见抬头见》《天剑群侠》小品陈佩斯与朱时茂1984年《吃面条》合作者:陈佩斯聽1985年《拍电影》合']
第3步,对每一行文本处理,得到两个人物名字在该行语句中的位置,代码如下:
#index()方法检测字符串中是否包含子字符串,line[3]是那句话,line[0]是朱时茂
index1 = line[3].index(line[0])
index2 = line[3].index(line[1])
以第一行为例,查询,得到结果如下
index1=29,表示朱时茂的朱是这句话里的29个字
index2=25,表示陈佩斯的陈是这句话里的第25个字
第4步,对每一行文本进行处理,得到该行中每一个字的列表,以及每一个字和两个人物名字之间的距离(向量),共三个列表。
关键代码如下:
sentence = []
position1 = [] # position1=[-29]
position2 = [] #position2=[-25]
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
#当i=1 word=《 当i=2 word=水 依次循环
for i,word in enumerate(line[3]): #i=1 word=《
#.append()在列表末尾添加新的对象
sentence.append(word) #
position1.append(i-index1) #循环一次后
position2.append(i-index2) #循环一次后
i+=1
以第一行为例,查询,得到的三个列表结果如下:
<class 'list'>: ['《', '水', '与', '火', '的', '缠', '绵', '》', '《', '低', '头', '不', '见', '抬', '头', '见', '》', '《', '天', '剑', '群', '侠', '》', '小', '品', '陈', '佩', '斯', '与', '朱', '时', '茂', '1', '9', '8', '4', '年', '《', '吃', '面', '条', '》', '合', '作', '者', ':', '陈', '佩', '斯', '聽', '1', '9', '8', '5', '年', '《', '拍', '电', '影', '》', '合']
<class 'list'>: [-29, -28, -27, -26, -25, -24, -23, -22, -21, -20, -19, -18, -17, -16, -15, -14, -13, -12, -11, -10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31]
<class 'list'>: [-25, -24, -23, -22, -21, -20, -19, -18, -17, -16, -15, -14, -13, -12, -11, -10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]
这三个列表其实就是一个文字向量,一个距人物1的位置向量,一个距人物2的距离向量
第5步,每行循环后,将该行得到的三个列表(向量)、标注的关系,分别放入一个双向队列中,所有行循环完后,最终得到四个双向队列:1个汉字向量集合,2个位置向量集合,1个关系向量集合
datas.append(sentence)#放所有的文字向量
positionE1.append(position1) #放所有的位置向量1
positionE2.append(position2) # 放所有的位置向量2
labels.append(relation2id[line[2]])#
查询datas,部分结果如下:
#data双向队列deque里每个元素就是一行文本的后半部分句子sentence ,总共18000行,1500*12种关系,循环后如下
[['《', '水', '与', '火', '的', '缠', '绵', '》', '《', '低', '头', '不', '见', '抬', '头', '见', '》', '《', '天', '剑', '群',# '侠', '》', '小', '品', '陈', '佩', '斯', '与', '朱', '时', '茂', '1', '9', '8', '4', '年', '《', '吃', '面', '条', '》', '合', '作', '者', ':', '陈', '佩', '斯', '聽', '1', '9', '8', '5', '年', '《', '拍', '电', '影', '》', '合'],
#下面第二行的
['卢', '恬', ..此处省略N行.]...]
第6步,将得到的四个双向队列:1个汉字向量集合,2个位置向量集合,1个关系向量集合,放入一个二维表结构的DataFrame中,索引由0开始。得到二维表DataFrame:第一列列名为positionE1,内容为位置向量集合positionE1,第二列列名为positionE2,内容为位置向量集合positionE2,第三列列名为tags,内容为关系向量集合,第四列列名为words,内容为汉字向量集合。
df_data = pd.DataFrame({'words': datas, 'tags': labels,'positionE1':positionE1,'positionE2':positionE2}, index=range(len(datas)))
查询,部分结果如下:
positionE1 \
0 [-29, -28, -27, -26, -25, -24, -23, -22, -21, ...
1 [-29, -28, -27, -26, -25, -24, -23, -22, -21, ...
2 [-28, -27, -26, -25, -24, -23, -22, -21, -20, ...
3 [0, 1, 2,
tags
0 5
1 0
2 2
3 2
...
17997 7
17998 7
17999 7
words
0 [《, 水, 与, 火, 的, 缠, 绵, 》, 《, 低, 头, 不, 见, 抬, 头, ...
1 [卢, 恬, 儿, 是, 现, 任, 香, 港, 南, 华, 体, 育, 会, 主, 席, ...
2 [场, 照, 片, 事, 后, 将, 发, 给, 媒, 体, ,, 避, 免, 采, 访, ...
3 [李, 敖, 后, 来, 也, 认, 为, ,, “, 任, 何, 当, 过, 王, 尚, ...
4 [改, 写, 2, 3, 年, 历, 史, 2, 0, 1, 0, 年, 1, 0, 月, ...
5 [-, 简, 介, 梁, 左, 与, 丈, 夫, 英, 达, 梁, 欢, ,, 女, ,,
...
这时里面的words列,里面是汉字的向量集合,BiLSTM+Attention模型无法处理,需要转换为数字
第7步,处理datas,得到word2id字典,说白了就是文本里所有字和其对应的使用频率名次,具体如下:
(1)将上述汉字向量集合datas,处理成一个整体的大向量,也就是去除里面的中括号,例如:例如:Given [[‘你’,‘好’],[‘太’,‘阳’]], return [‘你’,‘好’,‘太’,‘阳’],关键代码如下:
def flatten(x):
result = []
for el in x:
if isinstance(x, collections.Iterable) and not isinstance(el, str):
result.extend(flatten(el))
else:
result.append(el)
return result
(2)将上述汉字整体的大向量(在双向队列中),放入pandas的Series数组中,这样则有了索引
sr_allwords = pd.Series(all_words)
查询sr_allwords ,结果如下:
0 《
1 水
2 与
3 火
...
(3)对上述Series数组里面的存的每个汉字进行统计计数并且排序,放入pandas的Series数组中(汉字作为索引,该字统计结果作为值)
sr_allwords = sr_allwords.value_counts()
查询sr_allwords ,结果如下
, 32968
、 21748
的 15069
。 8837
...
(4)将上述Series数组中的索引列,也就是按统计总数排序后的汉字,放入set_words对象中
set_words = sr_allwords.index
查询set_words,结果如下
([',', '、', '的', '。', '1', '年', '人', '是', '0', '一',...
(5)得到一个数组,索引是按按统计总数排序后的汉字,对应的值是从1开始递增,相当于排名
set_ids = range(1, len(set_words)+1)#range(1, 4407)
#生成一个1到4407的列表
word2id = pd.Series(set_ids, index=set_words)
查询,结果如下:
, 1
、 2
的 3
。 4
1 5
(6)把上述数组的序列和值互换,排名变为索引,值变为统计总数排序后的汉字
id2word = pd.Series(set_words, index=set_ids)
查询,结果如下
1 ,
2 、
3 的
4 。
5 1
6 年
7 人
(7)给上述两个数组最后加入两个末尾行 blank、unknow,用于查询不到的情况,因为建立字典最初的数据源datas并不是全部循环,刚才说了有阈值,所以字典里也不是所有的字,避有查不到的情况,或补全的情况等,末端加unknow,作为备用。
word2id["BLANK"]=len(word2id)+1 #len(word2id)+1=4407 在数组最后一行加入 blank 4407,倒数第二行为 摹 4406
word2id["UNKNOW"]=len(word2id)+1 #word2id['UNKNOW']: 4408 在数组最后一行加入 UNKNOW 4408
id2word[len(id2word)+1]="BLANK" #在数组最后一行加入 4407 blank,倒数第二行为 4406 摹
id2word[len(id2word)+1]="UNKNOW" #在数组最后一行加入 4408 unknown
到这里,word2id字典就建立好了。
第8步,将二维表结构的DataFrame中的words列,通过查询上述建立的word2id字典,将每个汉字向量里的每个字转换为出现频率的排序名次数字。 并且,设定阈值50,若这句话里的字多于50个则截断,少于50个则补全为50。(由于神经网络训练中一旦设定参数则必须输入固定长度数据,所以此处进行统一)
关键代码如下:
for i in words:
if i in word2id:
ids.append(word2id[i])
else:
ids.append(word2id["UNKNOW"])
max_len=50
if len(ids) >= max_len:#循环后,若ids长度大于等于50,返回ids的前50个元素
return ids[:max_len] #则返回ids[:50],也就是ids的前50个元素
#循环后,若ids长度小于50
ids.extend([word2id["BLANK"]]*(max_len-len(ids)))
转换前
0 [《, 水, 与, 火, 的, 缠, 绵, 》, 《, 低, 头, 不, 见, 抬, 头, ...
1 [卢, 恬, 儿, 是, 现, 任, 香, 港, 南, 华, 体, 育, 会, 主, 席, ...
2 [场, 照, 片, 事, 后, 将, 发, 给, 媒, 体, ,, 避, 免, 采, 访, ...
3 [李, 敖, 后, 来, 也, 认, 为, ,, “, 任, 何, 当, 过, 王, 尚, ...
4 [改, 写, 2, 3, 年, 历, 史, 2, 0, 1, 0, 年, 1, 0, 月, ...
5 [-, 简, 介, 梁, 左, 与, 丈, 夫, 英, 达, 梁, 欢, ,, 女, ,, ...
6 [演, 义, 中, 诸, 葛, 亮, 先, 用, 反, 间, 计, 使, 魏, 免, 了, ...
7 [张, 竹, 君, 立, 即, 出, 面, 组, 成, 开, 往, 武, 汉, 战, 地, ...
转换后
0 [20, 335, 19, 858, 3, 2590, 2771, 22, 20, 1203...
1 [909, 2104, 63, 8, 265, 79, 155, 339, 256, 76,...
2 [259, 295, 350, 133, 35, 163, 236, 332, 607, 3...
3 [28, 1394, 35, 96, 128, 366, 18, 1, 42, 79, 15...
4 [775, 618, 15, 81, 6, 200, 330, 15, 9, 5, 9, 6...
5 [17, 409, 278, 172, 478, 19, 728, 101, 86, 359...
6 [34, 297, 24, 419, 395, 376, 179, 382, 605, 31...
7 [31, 972, 178, 212, 515, 40, 390, 516, 44, 147...
第9步,将positionE1、positionE2两列中的向量元素里的数字,映射到0-81之间,并且控制每个向量的长度为50,与字向量长度一致。
关键代码如下:
#若num小于-40返回0,大于40返回80,之间加40
def pos(num):
if num < -40:
return 0
if num >= -40 and num <= 40:
return num + 40
if num > 40:
return 80
if len(words) >= max_len: # 如果words长度大于等于50
return words[:max_len] # 返回words的前50个元素
# 如果不大于50
words.extend([81] * (max_len - len(words))) # [81]]*(50-48)=2
查询,结果如下:转换前
positionE1 \
0 [-29, -28, -27, -26, -25, -24, -23, -22, -21, ...
1 [-29, -28, -27, -26, -25, -24, -23, -22, -21, ...
2 [-28, -27, -26, -25, -24, -23, -22, -21, -20, ...
3 [0, 1, 2,
查询,结果如下,转换后
positionE1 \
0 [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 2...
1 [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 2...
2 [12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2...
3 [40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 5...
...
可以看出,只有tag这一列没有转换,也就是标注的关系这一列。
第10步,将处理后得到的这4个向量集(字向量、两个位置向量、关系向量),和word2id字典、id2word字典、relation2id字典,7个变量写入训练PKL文本中
代码如下
with open('../people_relation_train.pkl', 'wb') as outp:
pickle.dump(datas, outp)
pickle.dump(labels, outp)
pickle.dump(positionE1, outp)
pickle.dump(positionE2, outp)
pickle.dump(word2id, outp)#序列化对象,将对象word2id保存到文件outp中去
pickle.dump(id2word, outp)
pickle.dump(relation2id, outp)
print ('** Finished saving the traindata.')
到此为止,我们已经获取了处理好的模型的训练集向量数据了
第11步,按上述方法获取模型的测试集向量数据,保障数据源不同。
具体做法是,将刚才的2、3、4、5、6、8、9、10重新写一遍(第7步建立word2id字典不需要写了直接用上面建好的),只不过调整第2步的阈值,使得处理数据源文本中不同的行。
变化如下:
之前的第2步
行循环开始:
count = [0,0,0,0,0,0,0,0,0,0,0,0]
if count[relation2id[line[2]]] <=1500:
开始处理
每循环一行,将该行关系对应的count[relation2id[line[2]]]加1
这里的第2步
行循环开始:
count = [0,0,0,0,0,0,0,0,0,0,0,0]
if count[relation2id[line[2]]] >1500 and count[relation2id[line[2]]]<=1800:
开始处理
每循环一行,将该行关系对应的count[relation2id[line[2]]]加1
可以看出,每拿到一行提取出关系
- 之前是每种关系处理够1500次后,再进来行是这个关系就不处理
- 这里是每种关系,循环到第1501次时,才开始处理,一直处理到1800次
这样处理到的行就肯定和之前的不同。也保证了测试集和训练集的不同。
按照这种方法,将处理后得到的这4个向量集(少了word2id字典、id2word字典、relation2id字典),写入测试PKL文本中
with open('../people_relation_test.pkl', 'wb') as outp:
pickle.dump(datas, outp)
pickle.dump(labels, outp)
pickle.dump(positionE1, outp)
pickle.dump(positionE2, outp)
print ('** Finished saving the testdata.')
至此,完成了数据的预处理。得到了输入模型的向量。
四、模型训练、模型测试、结果评测
(一)dataloader和model准备
第1步,打开刚才生成的训练集文件people_relation_train.pkl、测试文件people_relation_train.pkl,加载内容到对应的数组变量里
with open('./data/people_relation_train.pkl', 'rb') as inp:
word2id = pickle.load(inp)
id2word = pickle.load(inp)
relation2id = pickle.load(inp)
train = pickle.load(inp)
labels = pickle.load(inp)
position1 = pickle.load(inp)
position2 = pickle.load(inp)
with open('./data/people_relation_test.pkl', 'rb') as inp:
test = pickle.load(inp)
labels_t = pickle.load(inp)
position1_t = pickle.load(inp)
position2_t = pickle.load(inp)
查询test,结果如下
[[ 126 2 293 ... 4407 4407 4407]
[ 805 2748 1 ... 232 76 68]
[ 40 385 20 ... 155 339 440]
...
[ 254 48 80 ... 4407 4407 4407]
[ 5 16 77 ... 168 4 4407]
[ 680 980 1 ... 4407 4407 4407]]
第2步,创建一个字典变量config,放入配置信息:word2id的长度4409,以及其他直接给定的参数值。(其实这个才是模型配置的关键)
查询,结果如下
config:
{
'EMBEDDING_SIZE': 4409, #嵌入字典(字向量)的大小(也就是字典中有多少个字)
'EMBEDDING_DIM': 100, #嵌入向量的维度(也就是每个字用多少维度向量表示)
'POS_SIZE': 82, #嵌入字典(位置向量)的大小(也就是字典中有多少个字)
'POS_DIM': 25,#嵌入向量的维度(也就是每个字用多少维度向量表示)‘
'HIDDEN_DIM': 200, #隐藏层特征维度
'TAG_SIZE': 12, #标签的大小
'BATCH': 128, #批量大小,说白了在这里也是一次训练几个句子
'pretrained': False #是否之前训练过
}
上述只是初步准备工作,下面介绍如果用pytorch实现模型训练,用的也是基于pytorch中的基本流程(主要是数据输入模型的流程):
- 创建一些张量tensor(可以当成一个矩阵,几维的都行)
- 基于这些张量,创建 Dataset 对象
- 基于Dataset 对象,创建 DataLoader 对象(数据进模型关键一步)
- 循环 DataLoader 对象,将输入数据、 label加载到模型中进行训练
第3步,基于第1步中获取的训练向量数组,创建训练张量和测试张量
基于张量,创建了训练和测试的TensorDataset、DataLoader(DataLoader是PyTorch中数据读取的一个重要接口,只要是用PyTorch来训练模型基本都会用到该接口),核心代码如下:
创建4个训练用的长张量LongTensor、TensorDataset和DataLoader
# 以下是将处理过的数据写回到变量中,变量太大读不出来
train = torch.LongTensor(train[:len(train) - len(train) % BATCH])
position1 = torch.LongTensor(position1[:len(train) - len(train) % BATCH])
position2 = torch.LongTensor(position2[:len(train) - len(train) % BATCH])
labels = torch.LongTensor(labels[:len(train) - len(train) % BATCH])
#创建一个 Dataset 对象
train_datasets = D.TensorDataset(train, position1, position2, labels)
# 创建一个 DataLoader 对象
train_dataloader = D.DataLoader(train_datasets, BATCH, True, num_workers=0)
其中DataLoader是数据进模型前的最终形式,非常重要,详细可以参考这篇文章。
里面参数含义如下:
train_datasets:表示传入的数据集
BATCH:批量的意思,上述已经设置batch=128,指每个批量有多少样本,也是后续在模型中一次处理的样本数
num_workers=0:决定有几个进程来处理data loading。0意味着只有一个主进程,所有的数据都会被load进主进程。(默认为0)
ture:这里个人不完全确定,猜测表示shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序。
创建4个测试用的长张量、TensorDataset和DataLoader
test = torch.LongTensor(test[:len(test) - len(test) % BATCH])
position1_t = torch.LongTensor(position1_t[:len(test) - len(test) % BATCH])
position2_t = torch.LongTensor(position2_t[:len(test) - len(test) % BATCH])
labels_t = torch.LongTensor(labels_t[:len(test) - len(test) % BATCH])
#创建一个 Dataset 对象
test_datasets = D.TensorDataset(test, position1_t, position2_t, labels_t)
# 创建一个 DataLoader 对象
test_dataloader = D.DataLoader(test_datasets, BATCH, True, num_workers=0)
第4步,将配置信息字典变量config和embedding_pre传入BiLSTM_ATT.py中,返回BiLSTM_ATT的model,代码如下:
model = BiLSTM_ATT(config, embedding_pre)
这一步其实初始化了模型,具体调用BiLSTM_ATT.py中的类的构造函数创建对象,其实主要是对成员变量赋初始值
#输入:三个参数如下
#self:Unable to get repr for 
可以看出,output保存了最后一层,每个time step的输出h,如果是双向LSTM,每个time step的输出h = [h正向, h逆向] (同一个time step的正向和逆向的h连接起来)。
第5步,指定一个优化器,这里用的是Adam优化器(还有很多别的)
调用pytorch中的optim.Adam接口,对model进行优化,返回一个optmizer,
learning_rate = 0.0005 #学习率
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=1e-5)
#参数含义:要优化什么、学习率是多少
第6步,定义一个损失函数,一般分类任务就是交叉熵,回归任务一般就是mse损失函数,就是算一下预测值和真实值之间的均方误差
调用nn.CrossEntropyLoss()损失函数,返回一个criterion
criterion = nn.CrossEntropyLoss(size_average=True)
(二)模型训练、模型测试、结果评测实施
开始10次大循环(模型训练、模型测试、结果评测)
EPOCHS = 10 # 循环次数,这个参数可以自己设置
for epoch in range(EPOCHS): # 第一次epoch=0
每次大循环,在训练集上模型训练一次,再在测试集上模型测试一次,得出评测结果,方法如下:
(1)在训练集上模型训练一次
对train_dataloader所有行进行循环,对每一行:
- 取出该行的3个向量;
- 将该行的3个向量输入model,得出y值;
- 用损失函数对比,y值和tag,得出损失loss
- 再反向传播修正模型model(重点)
所行循环完后,model进化了很多。代码及注释如下:
for sentence, pos1, pos2, tag in train_dataloader:
# Variable像一个装鸡蛋的篮子,里面的鸡蛋就是torch的Tensor了,鸡蛋数会不断发生变化
sentence = Variable(sentence)
pos1 = Variable(pos1)
pos2 = Variable(pos2)
tags = Variable(tag)
#1.前向传播:将train_dataloader中sentence、pos1、pos2转换为Variable类型后输入model中,得到预测值y
y = model(sentence, pos1, pos2)
#2.将y和标签tags(转换为Variable的),输入到损失函数中,得到损失值loss
loss = criterion(y, tags)#criterion,这是损失函数用于多分类问题
#上述两步为神经网络的前向传播
#3.梯度清零
optimizer.zero_grad()
#由于pytorch的动态计算图,当我们使用后续loss.backward()和opimizer.step()进行梯度下降更新参数的时候,
# 梯度并不会自动清零。并且这两个操作是独立操作。
#如若不清理,下面反向传播backward()的时候就会累加梯度
#4.反向传播
loss.backward()
#反向传播求解梯度
#当通过前向传播得到由任意一组随机参数W和b计算出的网络预测结果后,
# 我们可以利用损失函数相对于每个参数的梯度来对他们进行修正,使得损失越来越小,这就是反向传播
# 事实上神经网络的训练就是这样一个不停的前向 - 反向传播的过程,
# 直到网络的预测能力达到我们的预期。
#5.更新权重参数
optimizer.step()
关于批次:每次循环并不是只取了一行文本中的四个向量和一个关系,而是一次128行文本对应的四个向量和一个关系,首次循环debug时,部分结果展示如下,可以看出y值非常不靠谱
sentence = Variable(sentence)
#tensor
# ([[ 531, 29, 316, ..., 3, 444, 908],
# [ 110, 1053, 460, ..., 4407, 4407, 4407],
# [ 19, 31, 1232, ..., 4407, 4407, 4407],
# ...,
# [ 1579, 2622, 1100, ..., 4407, 4407, 4407],
# [ 113, 48, 87, ..., 4407, 4407, 4407],
# [ 478, 264, 920, ..., 4407, 4407, 4407]])
#torch.Size([128, 50]) 有128个向量,每个长度50
tags = Variable(tag)
#tensor
# ([ 8, 3, 11, 5, 9, 8, 10, 6, 4, 5, 6, 0,
# 7, 8, 4, 7, 10, 6, 10, 8, 2, 7, 9, 10,
# 9, 6, 1, 5, 5, 5, 4, 2, 6, 9, 7, 5,
# 10, 0, 5, 0, 11, 6, 2, 5, 7, 7, 10, 3,
# 10, 11, 1, 3, 0, 1, 3, 10, 11, 2, 11, 4,
# 6, 4, 8, 3, 0, 0, 10, 5, 4, 2, 3, 9,
# 8, 7, 0, 11, 5, 4, 5, 4, 1, 8, 2, 3,
# 3, 2, 1, 0, 10, 6, 3, 8, 6, 0, 3, 11,
# 8, 2, 1, 11, 0, 0, 10, 11, 9, 10, 1, 7,
# 10, 9, 4, 2, 3, 8, 0, 7, 10, 1, 5, 4,
# 7, 7, 3, 3, 9, 8, 4, 11])
#torch.Size([128])
y = model(sentence, pos1, pos2)
#tensor
# ([[ 1.6851e-02, 2.2230e-03, 2.5432e-03, ..., 1.1103e-01,
# 2.5689e-03, 8.3816e-02],
# [ 4.0907e-03, 3.9208e-01, 1.5956e-01, ..., 1.1556e-02,
# 2.2479e-03, 3.0899e-04],
# [ 6.0303e-04, 1.3746e-03, 5.3099e-07, ..., 1.7214e-05,
# 1.2239e-02, 3.5070e-03],
# ...,
# [ 2.5958e-03, 5.1988e-01, 4.6925e-03, ..., 1.2565e-04,
# 6.4943e-02, 3.9626e-01],
# [ 1.0320e-01, 1.7339e-01, 5.6059e-05, ..., 2.5072e-04,
# 7.2548e-04, 1.1548e-02],
# [ 3.9980e-01, 6.8521e-02, 2.0005e-07, ..., 1.7625e-02,
# 4.2092e-02, 5.8418e-03]])
#torch.Size([128, 12])
关于前向传播:
模型前向传播时的调用函数如下( 也就是进行 y = model(sentence, pos1, pos2)时,调用这个函数)
def forward(self,sentence,pos1,pos2):
#计算隐层
self.hidden = torch.randn(2, self.batch, self.hidden_dim // 2),torch.randn(2, self.batch, self.hidden_dim // 2)
#对输入的三个向量进行拼接,拼接成最终输入的矩阵
# 拼接数据,可以根据dim进行调整:
# dim = 0: 代表基于行拼接
# dim = 1: 代表基于列拼接
# dim = 2: 代表基于通道拼接,此处采取2,也就是拼接成:很多行,1列,150通道的输入
embeds = torch.cat((self.word_embeds(sentence),self.pos1_embeds(pos1),self.pos2_embeds(pos2)),2)
#交换embeds中的维度
embeds = torch.transpose(embeds,0,1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = torch.transpose(lstm_out,0,1)
lstm_out = torch.transpose(lstm_out,1,2)
lstm_out = self.dropout_lstm(lstm_out)
att_out = F.tanh(self.attention(lstm_out))
#att_out = self.dropout_att(att_out)
relation = torch.tensor([i for i in range(self.tag_size)],dtype = torch.long).repeat(self.batch, 1)
relation = self.relation_embeds(relation)
res = torch.add(torch.bmm(relation,att_out),self.relation_bias)
res = F.softmax(res,1)
return res.view(self.batch,-1)
上述的数据拼接,具体查看此文章
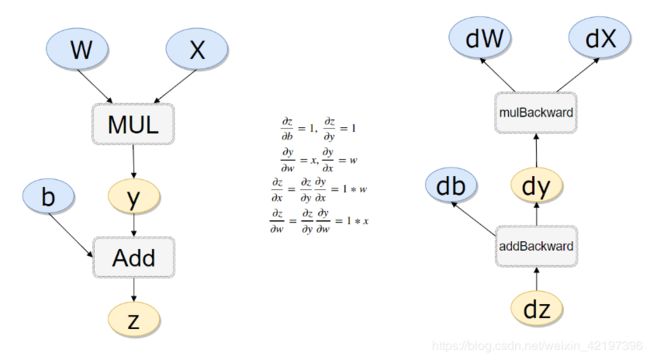
关于梯度清零:第三步中的梯度简单来说是多元函数在某点的偏导,pytorch中不会自动梯度清零,所以要手工清,具体什么是梯度?可以查看这篇文章
关于反向传播:
举个例子如下图,左侧为正向传播,那么右侧求导的过程为反向传播
(2)在测试集上模型测试一次(这时for sentence, pos1, pos2, tag in train_dataloader已经结束了,也就是在训练集上已经小循环一次了)
对test_dataloader所有行进行循环,对每一行:
- 取出该行的3个向量;
- 将该行的3个向量输入刚才训练的model,得出y值;
- 将y值和tag循环、比对,得出每一个关系:预测了多少次,实际多数次,预测对了多少次。
for sentence, pos1, pos2, tag in test_dataloader:
sentence = Variable(sentence)
pos1 = Variable(pos1)
pos2 = Variable(pos2)
y = model(sentence, pos1, pos2)#测试集三个向量Variable输入model得到y,不在进行反向传播等步骤
y = np.argmax(y.data.numpy(), axis=1)#得到标注值y
for y1, y2 in zip(y, tag):#开始评测
主要计算该关系预测了多少次,实际多数次,预测对了多少次。
count_predict[y1] += 1#预测列表中,该关系数量加一
count_total[y2] += 1 #实际列表中,该关系数量加一
if y1 == y2: #如果判断对了,正确次数列表中,该关系数量加一
count_right[y1] += 1
这时的小循环中,每次也是处理128行,debug该小循环第一次时的部分结果如下,可以看出,经过上述训练集训练,y值已经比较靠谱了
sentence = Variable(sentence)
#tensor
# ([[ 2057, 661, 1, ..., 4407, 4407, 4407],
# [ 755, 805, 2282, ..., 4407, 4407, 4407],
# [ 131, 632, 17, ..., 4407, 4407, 4407],
# ...,
# [ 51, 60, 381, ..., 4407, 4407, 4407],
# [ 12, 1261, 635, ..., 4407, 4407, 4407],
# [ 2, 28, 155, ..., 30, 5, 16]])
#torch.Size([128, 50])
y = model(sentence, pos1, pos2)#测试集三个向量Variable输入model得到y,不在进行反向传播等步骤
#[ 0 9 2 1 10 0 5 8 4 0 6 10 2 4 2 11 7 3 2 10 10 1 0 10
# 10 1 9 0 10 5 10 7 11 0 0 0 11 10 7 9 1 1 1 11 4 3 3 8
# 8 2 3 0 3 3 10 11 3 3 11 10 7 11 10 9 11 7 11 11 7 1 11 4
# 0 3 1 5 9 7 11 6 6 1 5 7
# size=128
(3)计算评测指标
评测指标计算原理如下:
单个关系精确率Precision=该关系预测正确的次数/该关系预测总次数
单个关系召回率recall=该关系预测正确的次数/该关系实际的总数量
平均精确率precision = sum(precision) / len(relation2id)
平均召回率recall = sum(recall) / len(relation2id)
平均F1=(2 * precision * recall) / (precision + recall)
F1是一个综合指标,是Precision和Recall的调和平均数,一般情况下,Precision和Recall是两个互斥指标,即Recall越大,Precision往往越小,所以需要通过F1测度来综合进行评估,F1越大,分类器效果越好。
代码如下
for i in range(len(count_predict)):#预测关系列表长度循环,其实就是十二次
if count_predict[i] != 0:#如果第i种关系的预测的次数不为零
precision[i] = float(count_right[i]) / count_predict[i]
#精确率Precision=该关系预测正确的次数/该关系预测总次数
if count_total[i] != 0:#如果第i种关系的实际标注次数不为零
recall[i] = float(count_right[i]) / count_total[i]
#召回率=该关系预测正确的次数/该关系该关系实际的数量
precision = sum(precision) / len(relation2id)
recall = sum(recall) / len(relation2id)
print("准确率:", precision)
print("召回率:", recall)
print("f:", (2 * precision * recall) / (precision + recall))
运行结果如下:
可以看到,每一次循环f1就会提高,10次后达到0.33170570738290694,若是继续再来10次肯定还会提高。
这是第1次运行
准确率: 0.09732348095086467
召回率: 0.10572769953051642
f1: 0.10135166638127953
./model/model_epoch0.pkl has been saved
epoch: 1
这是第2次运行
准确率: 0.12754717366473256
召回率: 0.1339397496087637
f1: 0.13066532192198033
epoch: 2
这是第3次运行
准确率: 0.14299586874126904
召回率: 0.15960485133020344
f1: 0.1508445476659336
epoch: 3
这是第4次运行
准确率: 0.1781159290898783
召回率: 0.19576291079812205
f1: 0.18652295352468587
epoch: 4
这是第5次运行
准确率: 0.19483159165835137
召回率: 0.20969483568075117
f1: 0.20199015855134486
epoch: 5
这是第6次运行
准确率: 0.2279694419920687
召回率: 0.25456181533646327
f1: 0.24053287372938081
epoch: 6
这是第7次运行
准确率: 0.2648314485387588
召回率: 0.28221048513302033
f1: 0.27324490855374156
epoch: 7
这是第8次运行
准确率: 0.29647680625393114
召回率: 0.3174687010954616
f1: 0.30661387846202454
epoch: 8
这是第9次运行
准确率: 0.32590673571822565
召回率: 0.3437284820031299
f1: 0.3345804538901519
epoch: 9
这是第10次运行
准确率: 0.3193007855587718
召回率: 0.3451134585289515
f1: 0.33170570738290694
model has been saved
五、总结与展望
(一)体会
上述的模型数学原理和代码中模型内部原理,你也许还不太理解,但你只要知道这几步,也可以在关系抽取时中先使用它。
但后续有时间,还是要搞懂原理。
(二)关于代码中阈值的几点思考
数据预处理时:
1.第2步阈值的控制是为了防止数据量太大,训练集设置处理1500行,测试集设置处理了300行,这两个数值肯定是越大越好。
2.第8、9步处理字向量和两个位置向量时,向量长度都设置为了50,这个数值到底是不是最佳的,还有大家一起待研究。
3.第9步处理两个位置向量时,将每个向量里的每个数字映射到了0-80,这个选择不知道是不是最佳的,还有待大家一起研究。
4.第11步生成测试集的过程中,直接用的生成训练集时的word2id字典,这个字典是通过处理训练集的那1500行得到的,测试集拿来用效果怎么样,还有待研究。
(三)关于模型的思考
1.模型的输入是不是有这三个向量刚好是最佳的
2.为什么这条语句,三个向量就可以得出y值
y = model(sentence, pos1, pos2)
3.从预处理到模型训练时,很多时候代码中向量名字都变了,比如输入时是datas,拿出来用的train,是一样的吗?要debug看一下
(四)其他问题
关于pki文件的概念还有待研究
扫码或搜索关注公众号:知识图谱与机器学习
带你快速入门知识图谱
