摩拜单车用户行为数据分析报告
出于报告呈现的整洁度和美观度考虑,本篇仅展现分析背景、分析结论和分析过程,前期数据集清洗整理和信息提取,以及探索性分析和可视化过程可移步:《摩拜单车数据探索与可视化》
分析背景
分析目的
- 分析摩拜单车订单的相关数据对骑行时长的影响情况,以此作为业务运营优化的参考和依据(由于原数据集中无订单金额的数据,又因摩拜单车是以骑行时长作为计费标准的,骑行时长是影响订单金额大小的最重要因素,故本分析针对骑行时长展开)。
- 主要集中在分析骑行时间(包括工作日/双休日、高峰时段/非高峰时段两个维度)、骑行位置、用户价值这些变量对骑行时长的影响上。
数据集概要
- 原数据集来自Udacity提供的摩拜单车上海城区2016年8月随机抽样百万条用户使用数据,共有102361条订单记录,包含起点、目的地、租赁时间、还车时间、用户ID、车辆ID、交易编号和路线轨迹信息。
- 经过清洗整理和信息提取后,新数据集增加了22个新变量,主要用于分析的变量为:ttl_min(骑行时长(min))、distance(骑行始末点的直线距离(km))、daytype(工作日/双休日)、hourtype(高峰时段/非高峰时段)、ring_stage(内环内/中环内/外环内/外环外)、rate(高价值用户/中等价值用户/低价值用户)这六个变量。
- 新数据集在使用过程中亦去除了少量骑行速度、距离、时长的异常记录,最终的订单记录数量为102338条。
分析结论
用户行为总结
在数据探索过程中,发现骑行时间(包括工作日/双休日、高峰时段/非高峰时段)、骑行区域和用户价值这四个变量均会对骑行时长产生影响。当依次限定四个变量条件后,可以发现:
- 在骑行地理位置或用户价值条件相同的情况下,骑行时间对于平均骑行时长的规律明显,高峰时段和双休日的平均骑行时长高于非高峰时段和工作日;
- 总体上,用户价值越高、骑行时长越长,骑行区域越远离市中心、骑行时长越长,但前者对于骑行时长的影响远小于后者。
在关注类型变量对于骑行时长的影响之外,又有以下发现:
- 比较不同骑行地理位置和用户价值类型下,工作日和高峰时段的数据点分布特征高度类似,说明工作日和高峰时段的用车行为特征相似;
- 高价值用户更多地分布在内环范围内。
优化建议总结
针对上述用户行为数据分析结论,提出以下优化建议:
- 鉴于骑行时间(工作日/双休日、高峰时段/非高峰时段)高度影响骑行时长的特征,可以不同的骑行时间为划分标准,针对性地推出骑行套餐、营销活动,以提升订单频次和订单金额(如不同时段的骑行徽章奖励、限时免费骑、遇见高峰车等方式)
- 鉴于远离市区用户单次消费高(骑行时长长)、消费频次低(高价值用户少)的行为特征,可按骑行地理位置推出相应骑行套餐,以提升该类地区用户的消费频次、提高他们对于使用摩拜单车的依赖度
- 鉴于工作日和高峰时段的用户行为特征相似,因此在设计运营活动方案时,可合并考虑
其他说明
因原始数据集中的信息量过少,可供分析的内容有限,扩大数据集信息和范围后,可用于分析的内容包括但不限于:
- 根据用户在APP内的点击数据来分析关键路径转化率,以此判断某一地区的单车供需是否平衡,以供单车投放量和调度效率的优化
- 以月度、季度为单位的单车使用情况的周期性规律,以此作为营销方案设计和优化的参考和依据
- 骑行券、骑行套餐、充值返现等优惠活动对用户骑行行为的影响,以此作为用户精细化运营或营销方案设计的参考和依据
分析过程
主要关注四个类型变量对于骑行时长的影响。首先介绍骑行时长、骑行距离的数据分布情况。然后通过绘制小提琴图,观察到两者随类型变量的变化而高度相似的数据特征,进而判定只需关注骑行时长这一关键指标和四个类型变量之间的关系即可。最后通过点图绘制在控制不同条件的类型变量的情况下,其他变量对于骑行时长的影响。
# 导入所有需要用到的库,并将图表设置为直接显示
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
# 清除输出中的警告
import warnings
warnings.simplefilter("ignore")
# 导入清洗整理后的数据集
df_e = pd.read_csv('mobike_master.csv')
# 将对应列转换成类别变量
order_dict = {'ring_stage': ['inside inner ring', 'inside middle ring', 'inside outer ring', 'outside outer ring'],
'rate': ['high-value user', 'middle-value user', 'low-value user'],
'daytype': ['weekdays', 'weekends'],
'hourtype': ['rush hours', 'non-rush hours']}
for var in order_dict:
order = pd.api.types.CategoricalDtype(ordered = True, categories = order_dict[var])
df_e[var] = df_e[var].astype(order)
# 数据清理,去除少量在骑行速度、骑行时长和骑行距离上明显异常的数据
df_e['speed'] = df_e['distance'] / (df_e['ttl_min'] / 60)
df_e = df_e[-(((df_e['speed'] < 12) | (df_e['speed'] > 20)) & ((df_e['ttl_min'] > 720) | (df_e['distance'] > 50)))]
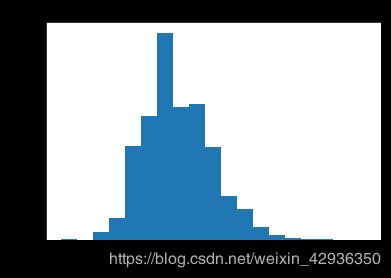
骑行时长分布
骑行时长的数据范围非常大,最小值为1分钟,最大值为666分钟,且呈现长尾分布,绝大多数骑行时长较短,使用log转换x轴绘图可以发现,骑行时长呈现右偏态分布,峰值出现在7-10分钟之间。
bins = 10 ** np.arange(0, np.log10(df_e.ttl_min.max()) + 0.15, 0.15)
plt.hist(data = df_e, x = 'ttl_min', bins = bins);
plt.xscale('log')
xticks = (1, 2, 5, 10, 20, 50, 100, 200, 500)
plt.xticks(xticks, xticks);
plt.xlabel('Riding Duration (min)');
plt.title('Distribution of Riding Duration');
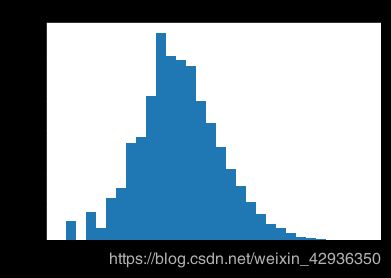
骑行距离分布
数据集中的骑行距离用的是骑行始末点之间的直线距离作为估算的,该数据的范围同样非常大,最小值为0.146km,最大值为32.497km,且同样呈现长尾分布,绝大多数骑行距离较短,极少数骑行距离较长,使用log转换x轴绘图可以发现,骑行距离呈现右偏态分布,峰值出现在0.7-1.3公里之间。
bins = 10 ** np.arange(np.log10(df_e.distance.min()), np.log10(df_e.distance.max()) + 0.08, 0.08)
plt.hist(data = df_e, x = 'distance', bins = bins);
plt.xscale('log')
xticks = (0.1, 0.2, 0.5, 1, 2, 5, 10, 20)
plt.xticks(xticks, xticks);
plt.xlabel('Riding Distance (km)');
plt.title('Distribution of Riding Distance');
骑行时长和骑行距离与其他变量的关系
- 在骑行时间方面,发现双休日和高峰时段的骑行时长和骑行距离的中位数相较工作日和非高峰时段都要更高(除双休日的骑行距离略微低于工作日);
- 在骑行区域方面,一旦用户骑行区域在内环之外,骑行时长和骑行距离的中位数均随着离市中心越远而变得越高,可能是由于越靠近郊区,用户出发点和目的地之间的距离越来越大;
- 在用户价值方面,骑行时长和骑行距离的中位数均随着用户价值变低而变低。
通过比较,发现骑行时长和骑行距离这两个数值变量的数据分布特征和分类情况下的变化特征几乎完全一样,后续可以不再对骑行距离做分析,原因如下:一方面骑行时长是原始数据中的真实数据(骑行距离是通过骑行始末点估算的直线距离),另一方面摩拜单车是根据骑行时长作为付费依据的,故此,在数据特征高度相似的情况下,选择数据质量和价值更高的骑行时长作为后续分析指标。
# 由于骑行时长和骑行距离的数据均呈现非常长的长尾,所以先对两个数据进行log转化,以便更清晰地观察数据特征
df_e['log_ttl_min'] = np.log10(df_e['ttl_min'])
df_e['log_distance'] = np.log10(df_e['distance'])
cat_vars = ['daytype', 'hourtype', 'ring_stage', 'rate']
fig, ax = plt.subplots(ncols = 4, nrows = 2, figsize = [20,10])
color = sb.color_palette()[0]
for i in range(len(cat_vars)):
var = cat_vars[i]
# 画第一行的图
sb.violinplot(data = df_e, x = var, y = 'log_ttl_min', ax = ax[0, i], color = color);
ttl_min_ticks = [1, 2, 5, 10, 20, 50, 100, 200, 500]
ax[0, i].set_yticks(np.log10(ttl_min_ticks));
ax[0, i].set_yticklabels(ttl_min_ticks);
ax[0, i].set_ylabel('Riding Duration (min)');
if i == 2:
xlabels = ax[0, i].get_xticklabels()
ax[0, i].set_xticklabels(xlabels, rotation = 10);
# 画第二行的图
sb.violinplot(data = df_e, x = var, y = 'log_distance', ax = ax[1, i], color = color);
distance_ticks = [0.1, 0.2, 0.5, 1, 2, 5, 10, 20]
ax[1, i].set_yticks(np.log10(distance_ticks));
ax[1, i].set_yticklabels(distance_ticks);
ax[1, i].set_ylabel('Riding Distance (km)');
if i == 2:
xlabels = ax[1, i].get_xticklabels()
ax[1, i].set_xticklabels(xlabels, rotation = 10);
plt.suptitle('riding duration and distance by other features', fontsize = 'xx-large');

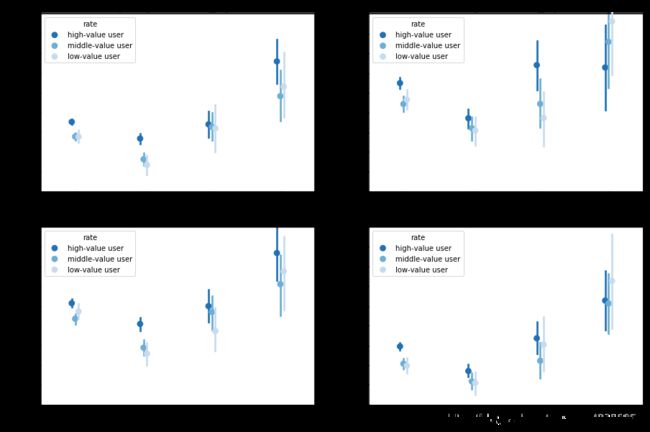
在给定骑行时间的条件下,骑行时长随骑行区域和用户价值的变化规律
- 总体上,除了内环以内的数据外,其他区域的平均骑行时长均随着骑行起点离市中心越远而变得越高
- 除在外环以外的双休日和非高峰时段外,高价值用户的平均骑行时长均是最高的
- 总体上,高峰时段和双休日的平均骑行时长要高于非高峰时段和工作日
- 从第一列的上下两张图中大致可以看出,工作日和高峰时段中,平均骑行时长随着用户价值变量和骑行区域变量的改变而发生的变化特征是非常相似的,这可能是因为工作日和高峰时段的用户中,上班族占了大多数,而这些上班族拥有相似的用车行为特征
# 自定义函数,绘制控制变量条件下的pointplot图
def ppltgrid(row_dict):
for var in row_dict:
firstplot = list(row_dict.keys())[0] # 设置第一个绘图的编号,以便后续获取第一个绘图y轴的操作
a0,b0,c0 = var.split(',')
a,b,c = int(a0), int(b0), int(c0)
plt.subplot(a,b,c)
flagid, flag, hue, x = row_dict[var]['flagid'], row_dict[var]['flag'], row_dict[var]['hue'], row_dict[var]['x']
ax = sb.pointplot(data = df_e[df_e[flagid] == flag], x = x, y = 'log_ttl_min', hue = hue,
palette = 'Blues_r', linestyles = '', dodge = 0.1);
ax.set_title("{}'s riding duration across {} and {}".format(flag, x, hue), fontsize = 'small');
ylocs = np.arange(1, 1.25, 0.025)
ylabels = np.round(np.power(10, ylocs), 2)
ax.set_yticks(ylocs);
ax.set_yticklabels(ylabels);
ax.set_yticklabels([],minor = True); # 不显示默认的主要刻度
if c % b == 1: # 为每行的第一个图设置y轴标签,其他图则不显示,以防遮盖图表内容
ax.set_ylabel('Mean Riding Duration (min)');
else:
ax.set_ylabel('');
if x == 'ring_stage' or x == 'rate': # ring_stage和rate的类别名称过长,将字体变小
xlabels = ax.get_xticklabels()
ax.set_xticklabels(xlabels, fontsize = 'small');
if var == firstplot:
ylim = ax.get_ylim() # 获取第一个绘图的y轴
else:
plt.ylim(ylim); # 使第二个开始的所有绘图保持和第一个绘图一致的y轴范围
plt.figure(figsize = [15, 10])
row_dict = {'2,2,1': {'flagid': 'daytype', 'flag': 'weekdays', 'hue': 'rate', 'x': 'ring_stage'},
'2,2,2': {'flagid': 'daytype', 'flag': 'weekends', 'hue': 'rate', 'x': 'ring_stage'},
'2,2,3': {'flagid': 'hourtype', 'flag': 'rush hours', 'hue': 'rate', 'x': 'ring_stage'},
'2,2,4': {'flagid': 'hourtype', 'flag': 'non-rush hours', 'hue': 'rate', 'x': 'ring_stage'}}
ppltgrid(row_dict)
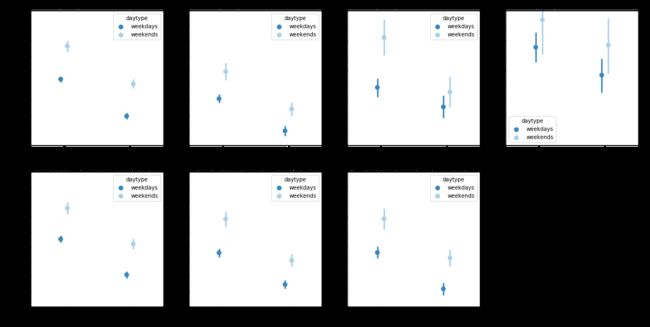
在给定骑行区域和用户价值的条件下,骑行时长随骑行时间的变化规律
- 分别限定骑行地理位置变量和用户价值变量,观察骑行时间对平均骑行时长的影响,可以发现数据点分布的相对位置高度相似,说明骑行时间对于平均骑行时长的规律明显,即在骑行地理位置或用户价值条件相同的情况下,高峰时段和双休日的平均骑行时长高于非高峰时段和工作日。
- 比较第一行和第二行的数据点分布特征,可以发现在用户价值变量视角下的数据点,随着用户价值由高到低,纵向变化幅度远低于第一行骑行位置视角下的纵向变化幅度,说明用户价值对平均骑行时长的作用较小,远小于骑行位置对其的影响。
plt.figure(figsize = [20,10])
row_dict = {'2,4,1': {'flagid':'ring_stage', 'flag': 'inside inner ring', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,2': {'flagid':'ring_stage', 'flag': 'inside middle ring', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,3': {'flagid':'ring_stage', 'flag': 'inside outer ring', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,4': {'flagid':'ring_stage', 'flag': 'outside outer ring', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,5': {'flagid':'rate', 'flag': 'high-value user', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,6': {'flagid':'rate', 'flag': 'middle-value user', 'hue': 'daytype', 'x': 'hourtype'},
'2,4,7': {'flagid':'rate', 'flag': 'low-value user', 'hue': 'daytype', 'x': 'hourtype'}}
ppltgrid(row_dict)
参考资料
- 查询上海地理中心点——国际饭店的经纬度坐标(高德开放平台):https://lbs.amap.com/console/show/picker
- 上海内环中环外环大致范围:https://zhidao.baidu.com/question/368519816811874924.html
- 摩拜单车2016年8月收费标准:http://www.33lc.com/article/76472.html