MPEG音频编码实验
文章目录
- MPEG音频编码实验
- MPEG-1 Audio LayerII编码器原理
- 多相滤波器组
- 心理声学模型(Psychoacoustic Model)
- 计算步骤
- Layer I编码
- 码率分配
- 装帧(Frame Creation)
- 帧头格式
- Layer II编码
- 关键变量说明
- 实验内容
- 理解程序设计的整体框架
- 理解感知音频编码的设计思想
- 理解心理声学模型的实现过程
- 比例因子计算
- 心理声学模型的计算
- 比特分配
- 输出音频的采样率和目标码率
- 输出某个数据帧的信息
MPEG音频编码实验
MPEG-1 Audio LayerII编码器原理
基本流程框图如下:

多相滤波器组
作用:将PCM样本变换到32个子带的频域信号。

首先,对窗口中的512个样本 X [ i ] , i = 1 , 2 , ⋯ , 511 X[i],i = 1,2,\cdots,511 X[i],i=1,2,⋯,511进行计算
Z [ i ] = C [ i ] ⋅ X [ i ] , i = 1 , 2 , ⋯ , 511 Z[i] = C[i] \cdot X[i] ,i=1,2,\cdots,511 Z[i]=C[i]⋅X[i],i=1,2,⋯,511
将样本分成64个分组,并计算64个 Y k Y_k Yk值。
Y [ k ] = ∑ j = 0 7 Z [ k + 64 j ] Y[k]=\sum^7_{j=0}Z[k+64j] Y[k]=j=0∑7Z[k+64j]
计算32个子带样本:
S [ i ] = ∑ k = 0 63 Y [ k ] ⋅ M [ i ] [ k ] S[i]=\sum^{63}_{k =0}Y[k]\cdot M[i][k] S[i]=k=0∑63Y[k]⋅M[i][k]
- 其中,分析矩阵 M [ i ] [ k ] = c o s ( ( 2 i + 1 ) ( k − 16 ) π 64 ) M[i][k]=cos(\frac{(2i+1)(k-16)\pi}{64}) M[i][k]=cos(64(2i+1)(k−16)π)
- 共需要 512 + 32 × 64 512+32\times{64} 512+32×64次乘法
- 每个子带的带宽为 π 32 T \frac{\pi}{32T} 32Tπ,中心位 π 64 T \frac{\pi}{64T} 64Tπ的奇数倍。
多项滤波器组的公式 S [ i ] S[i] S[i]可以由卷积公式代替:
S t [ i ] = ∑ n = 0 511 X [ n − t ] h i [ n ] S_t[i]=\sum^{511}_{n=0}X[n-t]h_i[n] St[i]=n=0∑511X[n−t]hi[n]
其中 h i [ n ] = h [ n ] × c o s ( ( 2 i + 1 ) ( k − 16 ) π 64 ) h_i[n]=h[n]\times cos(\frac{(2i+1)(k-16)\pi}{64}) hi[n]=h[n]×cos(64(2i+1)(k−16)π),当 n 64 \frac{n}{64} 64n的整数部分(也就是所在组的组号)为奇数时, h [ n ] = − C [ n ] h[n]=-C[n] h[n]=−C[n],饭之 h [ n ] = C [ n ] h[n]=C[n] h[n]=C[n]
缺点
- 等带宽的滤波器组与人类听觉系统的临界频带不对应。在低频区域,单个子带会覆盖多个临界频带。

- 在这种情况下,量化比特数不能兼每个临界频带
- 滤波器组与其逆过程不是无失真的。
- 但滤波器组引入的误差差很小,且听不到
- 子带间频率有混叠

心理声学模型(Psychoacoustic Model)
通过子带分析滤波器组使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量。同时,令信号通过多点FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。在低频子带中,为了保护音调和共振峰的结构,就要求用较小的量化阶、较多的量化级数,即分配较多的位数来表示样本值。而话音中的摩擦音和类似噪声的声音,通常出现在高频子带中,对它分配较少的位数。而具体如何分配,则是要参考码率和心理声学模型。
作用:计算信号中不可听觉感知的部分
MPEG-1标准定义了两个心里声学模型。
心理声学模型1
特点:
- 计算复杂度低
- 对假设用户听不到的部分压缩太严重
心理声学模型2
特点:
- 提供了适合Layer III编码的更多特征
但实际实现的模型复杂度取决所需要的压缩因子。如大的压缩因子不重要,则可以完全不用心理声学模型。此时位分配算法不使用SMR( Signal Mask Ratio ),而是使用SNR。
计算步骤
- 将样本变换到频域
32个等分的子带信号并不能精确地反映人耳的听觉特性。于是引入FFT补偿频率分辨率不足的问题。- 采用Hann加权和DFT
- Hann加权减少频域中的边界效应
- 此变换不同于多相滤波器组,因为模型需要更精细的频率分辨率,而且计算掩蔽阈值也需要每个频率的幅值
- 模型1:采用512 (Layer I) 或1024 (Layers II and III)样本窗口
- Layer I:每帧384个样本点,512个样本点足够覆盖
- Layer II 和Layer III:每帧1152个样本点,每帧两次计算,模型1选择两个信号掩蔽比(SMR)中较小的一个
- 采用Hann加权和DFT
- 确定声压级别
- 子带n的声压级 L s b ( n ) = m a x ( X ( k ) , 20 × s c f m a x n ( n ) × 32768 − 10 ) d B L_{sb}(n)=max(X(k),20\times{scf_{maxn}(n)\times{32768}}-10)dB Lsb(n)=max(X(k),20×scfmaxn(n)×32768−10)dB
- 其中 X ( k ) X(k) X(k)是在子带n中的频谱线的生涯级别, s c f m a x ( n ) 是 在 一 帧 中 子 带 n 的 三 个 缩 放 因 子 最 大 的 一 个 scf_{max}(n)是在一帧中子带n的三个缩放因子最大的一个 scfmax(n)是在一帧中子带n的三个缩放因子最大的一个
- 考虑安静时阈值,也即绝对阈值
- 在标准中有根据输入PCM信号的采
样率编制的“频率、临界频带率和绝对阈值”表。此表为多位科学家经多次心理声学实验所得。
- 在标准中有根据输入PCM信号的采
- 将音频信号分解成“乐音(tones)” 和“非乐音/噪声”部分:因为两种信号的掩蔽能力不同
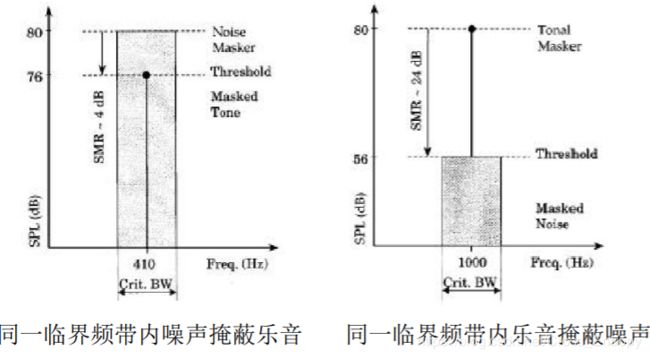
- 模型1:根据音频频谱的局部功率最大值确定乐音成分
- 局部峰值为乐音
- 将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)
- 区分有调和无调的方法
- 标明局部最大。如果x(k)比相邻的两个谱线都大,则x(k)为局部最大值;
- 列出有调成份,计算声压级。如果x(k)-x(k+j)>=7dB,则x(k)列为有调成份。j随谱线的位置不同而不同。
- 列出无调成分,计算功率。在每个临界频带内将所有余留谱线的功率加起来形成临界频带内无调成分的声压级。并列出以下参数:最接近临界频带几何平均值的谱线标记k,声压级以及无调指示。
- 音调和非音调掩蔽成分的消除
- 利用标准中给出的绝对阈值消除被掩蔽成分;考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分
- 单个掩蔽阈值的计算
- 音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
- 全局掩蔽阈值的计算
- 某一频率点i的总掩蔽阈值可以通过该店的屏蔽与之与单独掩蔽阈值想加来获得,即
- L T g ( i ) = 10 l g ( 1 0 L T q ( i ) 10 + ∑ j = 1 m 1 0 L T t m ( z ( j ) , z ( i ) 10 + ∑ j = 1 n 1 0 L T n m ( z ( j ) , z ( i ) ) 10 ) LTg(i)=10lg(10^{\frac{LTq(i)}{10}}+\sum_{j=1}^m10^{\frac{LTtm(z(j),z(i)}{10}}+\sum^{n}_{j=1}10^{\frac{LTnm(z(j),z(i))}{10}}) LTg(i)=10lg(1010LTq(i)+∑j=1m1010LTtm(z(j),z(i)+∑j=1n1010LTnm(z(j),z(i)))
- L T q ( i ) LTq(i) LTq(i)是频率点i的绝对掩蔽阈值
- L T t m ( z ( j ) , z ( i ) ) LTtm(z(j),z(i)) LTtm(z(j),z(i))是第j个音调掩蔽成分对频率点i的掩蔽阈值,对频率点i有掩蔽效应的音调成分共m个
- L T n m ( z ( j ) , z ( i ) ) LTnm(z(j),z(i)) LTnm(z(j),z(i))第j个非音调掩蔽成分对频率点i的掩蔽阈值,对频率点i有掩蔽效应的非音调掩蔽成分共n个。
- 还要考虑别的临界频带的影响。一个掩蔽信号会对其它频带上的信号产生掩蔽效应。这种掩蔽效应称为掩蔽扩散。
- S F d B ( x ) = 15.81 + 7.5 ( x + 0.474 ) − 17.5 1 + ( x + 0.474 ) 2 d B S F_{d B}(x)=15.81+7.5(x+0.474)-17.5 \sqrt{1+(x+0.474)^{2}} d B SFdB(x)=15.81+7.5(x+0.474)−17.51+(x+0.474)2dB
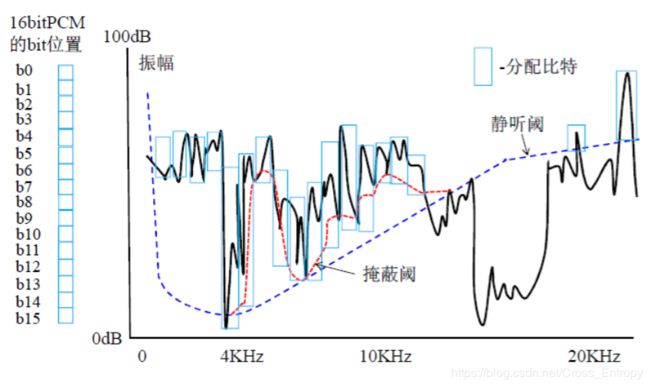
- 每个子带的掩蔽阈值
选择出本子带中最小的阈值作为子带阈值 - 计算每个子带信号掩蔽比(signal-to-mask ratio, SMR),将SMR传递给编码单元
- SMR = 信号能量 / 掩蔽阈值
Layer I编码
码率分配
作用:根据心理声学模型的计算结果,为每个子带信号分配比特数。
在调整到固定的码率之前要先确定可用于样值编码的有效比特数。这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特。
码率分配的过程
- 对每个子带计算掩蔽-噪声比MNR,是信噪比SNR–信掩比SMR,即:MNR = SNR–SMR
算法:循环,直到没有比特可用
- 计算noise-to-mask ratio, NMR
- 其中SNR由MPEG-I标准给定 (为量化水平的函数)。NMR表示波形误差与感知测量之间的误差
- 对最高NMR的子带分配比特,使获益最大的子带的量化级别增加一级
- 重新计算分配了更多比特子带的NMR

最终使整帧和每个子带的总噪声—掩蔽比最小。
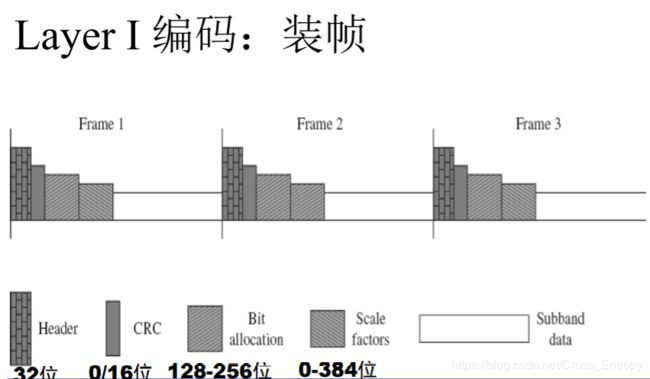
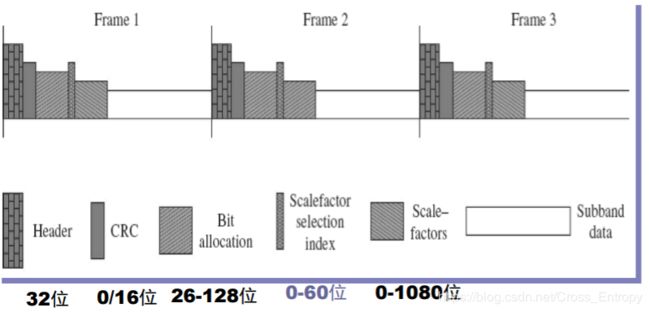
装帧(Frame Creation)
作用:产生MPEG-I兼容的比特流
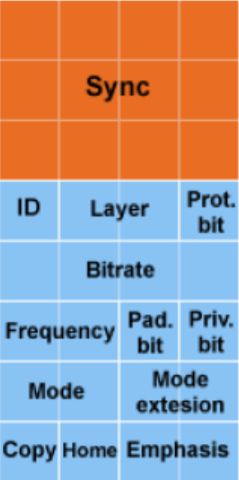
帧头格式
Layer II编码
与Layer I类似,但对Layer I有增强
- 帧结构
- 3 组/帧 x 12个样本/子带 x 32个子带/帧 = 1152个样本/帧
- 每个样本的overhead更少
- 缩放因子(比例因子)一般从低频子带到高频子带出现连续下降,每个子带的3个组尽可能共用缩放因子
- Layer I: 1个/12个样本
- 1个/(24/36)个样本
- 1/2/3个缩放因子和缩放因子选择信息(scale factor selection information, SCFSI) (每子带2比特)一起传送。
- 如果缩放因子和下一个只有很小的差别,就只传送大的一个,这种情况对于稳态信号经常出现
- 如果要给瞬态信号编码,则要在瞬态的前、后沿传送两个或所有三个比例因子
- 量化
- Layer I:每个子带从相同的量化集合中选择,每个子带取共14个量化器中的一个
- Layer II:根据采样和码率量化,不同子带可以从不同的量化器集合中选择,某些(高频)子带的比特数可能为0。
- 对量化级别在3、5、9级时,采用“颗粒” 优化。颗粒= 3 个样本,根据颗粒选择量化水平。
- 装帧
关键变量说明
| 变量 | 含义 |
|---|---|
| window_subband | 某个子带的滑动窗口 |
| filter_subband | 某个子带的滤波器 |
| combine_LR | 结合左右声道 |
| _scale_factor_calc | 缩放因子计算 |
| psycho_i, psycho_ii | 心理声学模型I或II |
| _main_bit_allocation | 比特分配 |
| _CRC_calc | 冗余校验计算 |
| _encode_bit_alloc | 编码比特分配 |
| _encode_scale | 编码比例因子 |
| transmission_pattern | 传送图样 |
| _subband_quantization | 子带量化 |
| _sample_encoding | 对采样进行编码 |
实验内容
理解程序设计的整体框架
程序大体上可以分为八个主要部分:
- 对滑动窗口中的数据进行滤波,以获得每个通道的32个子带。
- 如果选择了立体声模式,就加入左右声道。
- 计算这一真的比例因子。同时计算比例因子选择信息。
- 使用选定的心理声学模型计算频域掩蔽电平。
- 使用上一步计算出的掩蔽值进行比特分配。
- 如果设定了error protection flag,就田间冗余校验。
- 将比特分配,比例因子以及相关信息打包至比特流。
- 对子带进行量化,并把他们加入至比特流。
理解感知音频编码的设计思想
感知音频编码主要分为两条线。

第一条线为红色部分,实际上是比较常规的想法。即将一个信号按照人耳的听力特点,分成32个子带,并对每个子带中的频率成分进行量化。最后进一步通过颗粒形成来进一步减小数据量流。
第二条线则是继续深挖人耳的听力特点。由于人耳有听力掩蔽效应,所以对于人耳听不到的频率干脆不进行编码,同时对于人耳敏感的区域分配较多bit,以保证每个bit都能起到最大的效果。通过这种方式来使量化更加高效,进而使得总数据量减小。
此外,频域分辨力与时域分辨力有着矛盾,当增大时域分辨力时,会对频域分辨力造成不利影响。于是就需要选择一个较为折中的方案。
理解心理声学模型的实现过程
详细原理在原理部分已经说明,流程可以参考流程图。这里主要结合代码进行分析。
比例因子计算
k为通道数,t选择三个比例因子中的一个,i为需要参与比较的子带数。在所有子带中找到最大值,并通过二分法,在表格中找到大于等于最大值的量化值。
void scale_factor_calc(double sb_sample[][3][SCALE_BLOCK][SBLIMIT],
unsigned int scalar[][3][SBLIMIT], int nch,
int sblimit)
{
/* Optimized to use binary search instead of linear scan through the
scalefactor table; guarantees to find scalefactor in only 5
jumps/comparisons and not in {0 (lin. best) to 63 (lin. worst)}.
Scalefactors for subbands > sblimit are no longer computed.
Uses a single sblimit-loop.
Patrick De Smet Oct 1999.
*/
int k, t;
/* Using '--' loops to avoid possible "cmp value + bne/beq" compiler */
/* inefficiencies. Below loops should compile to "bne/beq" only code */
for (k = nch; k--;)
for (t = 3; t--;) {
int i;
for (i = sblimit; i--;) {
int j;
unsigned int l;
register double temp;
unsigned int scale_fac;
/* Determination of max. over each set of 12 subband samples: */
/* PDS TODO: maybe this could/should ??!! be integrated into */
/* the subband filtering routines? */
register double cur_max = fabs(sb_sample[k][t][SCALE_BLOCK - 1][i]);
for (j = SCALE_BLOCK - 1; j--;) {
if ((temp = fabs(sb_sample[k][t][j][i])) > cur_max)
cur_max = temp;
}
//在所有采样值寻找最大的一个。
/* PDS: binary search in the scalefactor table: */
/* This is the real speed up: */
for (l = 16, scale_fac = 32; l; l >>= 1) {
if (cur_max <= multiple[scale_fac])
scale_fac += l;
else
scale_fac -= l;
}
if (cur_max > multiple[scale_fac])
scale_fac--;
scalar[k][t][i] = scale_fac;
}
}
}
心理声学模型的计算
以一个较简单的心理声学模型为例,首先找到每个子带中最小的ATH。随后,对于每个子带或通道找到最小的缩放因子。最后按照公式进行计算。
void psycho_0(double SMR[2][SBLIMIT], int nch, unsigned int scalar[2][3][SBLIMIT], FLOAT sfreq) {
int ch, sb, gr;
int minscaleindex[2][SBLIMIT]; /* Smaller scale indexes mean bigger scalefactors */
static FLOAT ath_min[SBLIMIT];
int i;
static int init = 0;
if (!init) {
FLOAT freqperline = sfreq / 1024.0;
for (sb = 0; sb < SBLIMIT; sb++) {
ath_min[sb] = 1000; /* set it huge */
}
/* Find the minimum ATH in each subband */
for (i = 0; i < 512; i++) {
FLOAT thisfreq = i * freqperline;
FLOAT ath_val = ATH_dB(thisfreq, 0);
if (ath_val < ath_min[i >> 4])
ath_min[i >> 4] = ath_val;
}
init++;
}
/* Find the minimum scalefactor index for each ch/sb */
for (ch = 0; ch < nch; ch++)
for (sb = 0; sb < SBLIMIT; sb++)
minscaleindex[ch][sb] = scalar[ch][0][sb];
for (ch = 0; ch < nch; ch++)
for (gr = 1; gr < 3; gr++)
for (sb = 0; sb < SBLIMIT; sb++)
if (minscaleindex[ch][sb] > scalar[ch][gr][sb])
minscaleindex[ch][sb] = scalar[ch][gr][sb];
/* Oh yeah. Fudge the hell out of the SMR calculations
by combining the scalefactor table index and the min ATH in that subband
There are probably more elegant/correct ways of combining these values,
but who cares? It works pretty well
MFC Mar 03 */
for (ch = 0; ch < nch; ch++)
for (sb = 0; sb < SBLIMIT; sb++)
SMR[ch][sb] = 2.0 * (30.0 - minscaleindex[ch][sb]) - ath_min[sb];
}
比特分配
首先找到具有最大MNR的子带。如果找到了,就开始对他分配bit。
int a_bit_allocation(double perm_smr[2][SBLIMIT],
unsigned int scfsi[2][SBLIMIT],
unsigned int bit_alloc[2][SBLIMIT], int* adb,
frame_info* frame)
{
int i, min_ch, min_sb, oth_ch, k, increment, scale, seli, ba;
int bspl, bscf, bsel, ad, bbal = 0;
double mnr[2][SBLIMIT];
char used[2][SBLIMIT];
int nch = frame->nch;
int sblimit = frame->sblimit;
int jsbound = frame->jsbound;
al_table* alloc = frame->alloc;
static char init = 0;
static int banc = 32, berr = 0;
static int sfsPerScfsi[] = { 3, 2, 1, 2 }; /* lookup # sfs per scfsi */
if (!init) {
init = 1;
if (frame->header->error_protection)
berr = 16; /* added 92-08-11 shn */
}
for (i = 0; i < jsbound; ++i)
bbal += nch * (*alloc)[i][0].bits;
for (i = jsbound; i < sblimit; ++i)
bbal += (*alloc)[i][0].bits;
*adb -= bbal + berr + banc;
ad = *adb;
for (i = 0; i < sblimit; i++)
for (k = 0; k < nch; k++) {
mnr[k][i] = snr[0] - perm_smr[k][i];
bit_alloc[k][i] = 0;
used[k][i] = 0;
}
bspl = bscf = bsel = 0;
do {
/* locate the subband with minimum SMR */
maxmnr(mnr, used, sblimit, nch, &min_sb, &min_ch);
if (min_sb > -1) { /* there was something to find */
/* find increase in bit allocation in subband [min] */
increment =
SCALE_BLOCK * ((*alloc)[min_sb][bit_alloc[min_ch][min_sb] + 1].group *
(*alloc)[min_sb][bit_alloc[min_ch][min_sb] + 1].bits);
if (used[min_ch][min_sb])
increment -=
SCALE_BLOCK * ((*alloc)[min_sb][bit_alloc[min_ch][min_sb]].group *
(*alloc)[min_sb][bit_alloc[min_ch][min_sb]].bits);
/* scale factor bits required for subband [min] */
oth_ch = 1 - min_ch; /* above js bound, need both chans */
if (used[min_ch][min_sb])
scale = seli = 0;
else { /* this channel had no bits or scfs before */
seli = 2;
scale = 6 * sfsPerScfsi[scfsi[min_ch][min_sb]];
if (nch == 2 && min_sb >= jsbound) {
/* each new js sb has L+R scfsis */
seli += 2;
scale += 6 * sfsPerScfsi[scfsi[oth_ch][min_sb]];
}
}
/* check to see enough bits were available for */
/* increasing resolution in the minimum band */
if (ad >= bspl + bscf + bsel + seli + scale + increment) {
ba = ++bit_alloc[min_ch][min_sb]; /* next up alloc */
bspl += increment; /* bits for subband sample */
bscf += scale; /* bits for scale factor */
bsel += seli; /* bits for scfsi code */
used[min_ch][min_sb] = 1; /* subband has bits */
mnr[min_ch][min_sb] =
-perm_smr[min_ch][min_sb] + snr[(*alloc)[min_sb][ba].quant + 1];
/* Check if subband has been fully allocated max bits */
if (ba >= (1 << (*alloc)[min_sb][0].bits) - 1)
used[min_ch][min_sb] = 2; /* don't let this sb get any more bits */
}
else
used[min_ch][min_sb] = 2; /* can't increase this alloc */
if (min_sb >= jsbound && nch == 2) {
/* above jsbound, alloc applies L+R */
ba = bit_alloc[oth_ch][min_sb] = bit_alloc[min_ch][min_sb];
used[oth_ch][min_sb] = used[min_ch][min_sb];
mnr[oth_ch][min_sb] =
-perm_smr[oth_ch][min_sb] + snr[(*alloc)[min_sb][ba].quant + 1];
}
}
} while (min_sb > -1); /* until could find no channel */
/* Calculate the number of bits left */
ad -= bspl + bscf + bsel;
*adb = ad;
for (k = 0; k < nch; k++)
for (i = sblimit; i < SBLIMIT; i++)
bit_alloc[k][i] = 0;
return 0;
}
输出音频的采样率和目标码率
fprintf(trace_file, "采样率=%.1f kHz ", s_freq[header.version][header.sampling_frequency]);
fprintf(trace_file, "目标码率=%d kbps\n", bitrate[header.version][header.bitrate_index]);
使用上述语句可以获得采样率以及目标码率。
![]()
输出某个数据帧的信息
- 该帧所分配的比特数该帧的比例因子
- 该帧的比特分配结果
在处理过程中添加:
fprintf(trace_file, "帧[%d]被分配了%d比特\n", frameNum - 1, adb);
fflush(trace_file);
for (int i = 0; i < 2; ++i)
{
fprintf(trace_file, "通道%d信息\n", i);
for (int j = 0; j < 32; ++j)
{
fprintf(trace_file, "子带[%d]:\t分配%d比特\t ", j, bit_alloc[i][j]);
fprintf(trace_file, "比例因子%d %d %d\n", scalar[i][0][j], scalar[i][1][j], scalar[i][2][j]);
}
fflush(trace_file);
}
即可获得所需信息。结果如下:
