4
每周写一个 ARTS:Algorithm 是一道算法题,Review 是读一篇英文文章,Technique/Tips 是分享一个小技术,Share 是分享一个观点。
Algorithm - 三数之和
题目链接:https://leetcode-cn.com/problems/3sum/
代码仓库:https://github.com/fhx1998/LeetCode
List<Integer> list = Arrays.asList(nums[i], exist, nums[j]);
list.sort(Comparator.naturalOrder()); // 去重的必要条件
Review - Redis 官网的 FQA 部分
https://redis.io/topics/faq
FQA
Redis 为什么有别于其他 key-value 的存储?
有两个主要原因
- Redis 在与众多 key-value DBs 演进路径不同,它的 value 支持多样的数据类型,且可在众多类型中进行原子操作。Redis 的提供的数据类型是非常接近底层基础的数据结构,且中间没有额外的抽象层,对 programmer 暴露了足够多的底层信息。
- Redis 是基于内存运行的,但可以进行硬盘持久化的数据库。so it represents a different trade off where very high write and read speed is achieved with the limitation of data sets that can’t be larger than memory. 所以,Redis 的策略是一种在空间与速度上的权衡,利用了内存可以进行高速读写的特性,但舍弃了数据集合的存储空间,因为内存的空间相比于硬盘是非常小的。另一个优点是对于复制数据结构的在内存中的表示比在硬盘中的表示要简单许多,so Redis 内部简单又能干很多事。Redis 的两种持久化方式在硬盘存储的文件也不用支持随机访问,so 文件紧凑(compact)且总是以追加的方式生成(且 AOF 的日志恢复(就是从硬盘恢复数据到内存也是追加的方式))。但这种持久化设计也面临一些挑战。但主要的数据均在内存中表示,在操作这部分的数据时,就要保证和硬盘文件的数据一致性。
What happens if Redis runs out of memory?
Redis 会被 Linux 内核的 OOM 检测进程杀死,发生错误崩溃,或者性能开始降低。因为现代操作系统的 molloc() 方法返回 NULL 值不是一个寻常的行为,这时候通常服务器会开始交换(如果配置了交换空间),且 Redis 的性能会降级,so 你可以明显感知到有错误发生。
Redis 允许用户设置内存使用的最大值,通过配置文件的 *maxmemory *配置项限制 Redis 可以使用的内存。如果Redis 到达了使用限制,Redis 会拒绝 write 操作,返回 error(仍提供 Read 命令)。or 你可以配置缓存淘汰策略来应对空间满的情况(当使用 Redis 作为缓存服务时)。
- LRU,最近最少使用
- FIFO,先进先出策略
- LFU,最近最不经常使用
INFO 命令可以显示 Redis 使用内存情况 so 你的编写脚本来监控 Redis 服务器,在内存到达限制量之前检查必要的条件。
Redis is single threaded. How can I exploit multiple CPU / cores?
在使用 Redis 的时候,CPU 一般不会成为 Redis 的性能瓶颈(bottleneck),通常的瓶颈是内存或者网络情况。比如,Redis 使用管道技术(pipelining),在一个硬件配置均衡的 Linux 系统上 一 秒可以发送 100 万个请求,如果你的应用常用的命令时间复杂度是 O(N) 或者 O(log(N)),那占用的 CPU 资源通常很小。
但是,你可以在一个系统上跑多个不同 Redis 实例来最大化利用 CPU 资源。At some point a single box may not be enough anyway, so if you want to use multiple CPUs you can start thinking of some way to shard earlier.
若在某个时间点单个 box 仍不够,且你想要利用多个 CPU(多核?)可以考虑使用多个 Redis 实例。
You can find more information about using multiple Redis instances in the Partitioning page.
However ,在 Redis 4.0 中,我们开始让 Redis 具有更多线程的特性。目前为止该特性还限制在后台删除对象以及通过 Redis 模块实现的阻塞命令(and to blocking commands implemented via Redis modules. )
在未来的发布的新版本计划是让 Redis 更加的多线程化。
My slave claims to have a different number of keys compared to its master, why?
如果你使用的键的过期功能,那这是种正常现象。发生这种现象的原因:
- 主节点会在第一次与从节点同步的时候生成并传输 RDB 文件。
- RDB 文件不包含主节点中已过期的 keys,但这些过期的 keys 可能还在内存中。
- 尽管这些 key 已经过期,当他们仍会在主节点服务器的内存上。They’ll not be considered as existing, but the memory will be reclaimed later, both incrementally and explicitly on access.只是“认为”他们不存在,且稍后会在访问时以增量或显示方式回收内存。
尽管他们已逻辑不存在,但仍会是 info 或 dbsize 命令输出的一部分。
- 当 从节点 读取 RDB 文件时,这部分可能过期的数据不会别加载显示。
因此,用户普遍发现从节点 key 数据比主节点少,because of this artifact,but 实例内容没有逻辑上的差异。
生词
- compact
- rotation
- reclaim
- footprint
- bottleneck
- synchronization
- artifact
Technology - IDEA 调试技巧,Linux 最近常用的命令
断点

以下链接官网详解:
https://www.jetbrains.com/help/idea/stepping-through-the-program.html
具体来看一下 Drop Frame 是什么用

其字面意思就是丢弃当前的栈帧,我们知道 JVM 在调用方法时和结束方法对应着一个栈帧在虚拟机栈的入栈和出栈。
比方说, methodA 中调用了 methodB,对应虚拟机栈就是 B 的栈帧在 A 上面,当代码执行到 methodB 时,你点击 Drop Frame,就把当前栈顶元素,即把 B 的栈帧丢了,就把 methodB 的操作都丢弃了,那代码就会回到 methodA 中去,就相当于 debug 到上一步的操作。
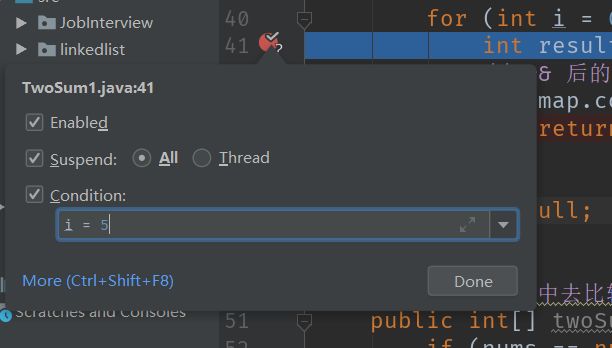
右击断点处,输入 Condition,调试的时候只有满足了这个条件才会在该断点停下来。比如在一个循环里,我们想直接到第 5 轮的循环,可以添加条件 i = 5 .
其中还有一个 Thread 的选择框,勾选了 Thread 就不阻塞其他线程的调试多线程程序。
Linux 部分
记录最近使用云服务器,配置服务用到的命令和学习到的知识
- top,ps。查看系统运行状态,进程运行情况。
- lsof -i,lsof -i:6380,查看端口占用信息。
 得知道这些都是什么意思。主要要看懂文件属主,文件属组及对应的执行权限。
得知道这些都是什么意思。主要要看懂文件属主,文件属组及对应的执行权限。- chmod 761 conf,r - 2,w - 4,x - 1,修改文件权限
- 绝对路径,相对路径