「Python爬虫系列讲解」四、BeautifulSoup 技术
本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
目录
1 安装及导入 BeautifulSoup
2 快速开始 BeautifulSoup 解析
2.1 BeautifulSoup 解析 HTML
2.2 简单获取网页标签信息
2.3 定位标签并获取内容
3 深入了解 BeautifulSoup
3.1 BeautifulSoup 对象
3.1.1 Tag
3.1.3 BeautifulSoup
3.1.4 Comment
3.2 遍历文档树
3.2.1 子节点
3.2.2 节点内容
3.2.3 父节点
3.2.4 兄弟节点
3.2.5 前后节点
3.3 搜索文档树
4 本文总结
1 安装及导入 BeautifulSoup
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 扩展库,是一个分析 HTML 或 XML 文件的解析器。它通过核实的转换器实现文档导航、查找、修改文档等功能;可以很好地处理不规范标记并生成剖析树(Parse Tree);提供的导航功能(Navigation)可以简单、快速地搜索剖析树以及修改剖析树。
BeautifulSoup 技术通常用于分析网页结构,爬取相应的 Web 文档,对于不规则的 HTML 文档提供一定的补全功能,从而节省开发者的时间和精力。
在 Python 3.x 中安装 BeautifulSoup 主要利用 pip 命令。
pip install BeautifulSoup4注:BeautifulSoup 有两个常用版本:BeautifulSoup 3(已停止开发)和 BeautifulSoup 4(简称bs4)
BeautifulSoup支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器:
其中一个是 lxml
pip install lxml另一个可供选择的解析器是纯 Python 实现的 html5lib
pip install html5lib BeautifulSoup 官方文档中主要的解析器及其优缺点
BeautifulSoup 官方文档中主要的解析器及其优缺点
安装成功后,在程序中导入 BeautifulSoup 库方法如下
from bs4 import BeautifulSoup2 快速开始 BeautifulSoup 解析
首先引入一个 html 文件作为例子介绍 BeautifulSoup 的使用
BeautifulSoup 技术
静夜思
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
杜甫
并称为“李杜”,为了与另两位诗人
李商隐
与杜牧
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
通过浏览器打开网页,如下图所示:

2.1 BeautifulSoup 解析 HTML
# 通过解析HTML代码,创建一个 BeautifulSoup 对象,然后调用 prettify() 函数格式化输出网页
from bs4 import BeautifulSoup
html = '''
BeautifulSoup 技术
静夜思
床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
杜甫
并称为“李杜”,为了与另两位诗人
李商隐
与杜牧
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
'''
# 按照标准的所进行时的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())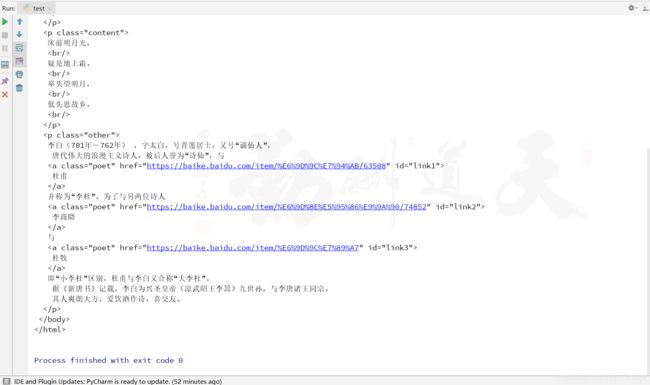
值得指出的是,前面定义的 HTML 代码源码标签中是缺少结束标签的,具体而言,缺少 和 标签,但是使用 prettify() 函数输出的结果已经自动补齐了结束标签,这是 BeautifulSoup 的一个优点。
BeautifulSoup 即使得到了一个损坏的标签,也会产生一个 DOM 树,并尽可能与原文档内容的含义一致,这种措施通常能够帮助用户更正确地搜集数据。
另外,还可以用本地 HTML 文件来创建 BeautifulSoup 对象
soup = BeautifulSoup(open('t.html'))2.2 简单获取网页标签信息
当使用 BeautifulSoup 解析网页时,有时会想获取某个标签之间的信息,具体代码如下
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 获取标题
title = soup.title
print('标题:', title)
# 获取头部
head = soup.head
print('头部:', head)
# 获取 a 标签
a = soup.a
print('超链接内容:', a)
# 获取 p 标签
p = soup.p
print('超链接内容:', p)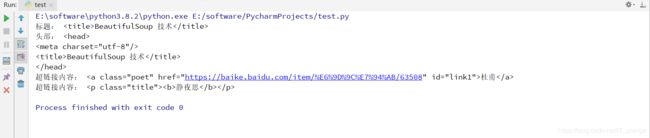
2.3 定位标签并获取内容
下述代码将实现获取网页所有的超链接标签及对应的 URL 内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 从文档中找到 的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取 的超链接
for link in soup.find_all('a'):
print(link.get('href'))
# 获取文字内容
for poeter in soup.find_all('a'):
print(poeter.get_text())
3 深入了解 BeautifulSoup
3.1 BeautifulSoup 对象
BeautifulSoup 将复杂的 HTML 文档个转换成一个树形结构,每个节点都是 Python 对象,BeautifulSoup 官方文档将所有对象总结为 4 种:
- Tag;
- NavigableString;
- BeautifulSoup;
- Comment。
3.1.1 Tag
Tag 对象表示 XML 或 HTML 文档中的标签,通俗地将就是 HTML 中的一个标签,该对象与 HTML 或 XML 原生文档中的标签相同。 Tag 有很多方法和属性,BeautifulSoup 中定义为 Soup.Tag,其中 Tag 为 HTML 中的标签,比如 head、title 等,其返回结果完整的标签内容,包括标签的属性和内容等。
BeautifulSoup 技术
静夜思
杜牧例如上述代码中,title、p、a 等都是标签,起始标签(
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.title)
print(soup.head)
print(soup.p)
print(soup.a)
值得注意的是,它返回的内容是多有标签中第一个符合要求的标签
很显然,通过 BeautifulSoup 对象即可轻松获取标签和标签内容,这比第三讲中的正则表达式要方便得多。
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(type(soup.html))
Tag 属性和方法众多,其中最重要的两个属性:name 和 attrs。
(1)name
name 属性用于获取文档树的标签名字。如果想获取 head 标签名字,则使用 soup.head.name 代码即可。对于内部标签,输出的值便为标签本身的名字。BeautifulSoup 对象本是比较特殊,它的 name 为 document。
print(soup.name)
print(soup.head.name)
print(soup.title.name)
(2)attrs
一个标签(Tag)可能有多个属性,例如
杜甫它存在两个属性:一个是 class 属性,对应的值为“poet”;另一个是 id 属性,对应的值为“link1”。Tag 属性的操作方法与 Python 字典相同,获取 p 标签的所有属性代码如下,得到一个字典类型的值。它获取的是第一个段落 p 的属性及属性值。
print(soup.p.attrs)
如果要单独获取某个属性,则可以使用如下两种方法来获取超链接的 class 属性值。
print(soup.a['class'])
print(soup.a.get('class'))
BeautifulSoup 的每个标签 Tag 可能有多个属性,可以通过 “.attrs” 获取其属性。Tag 的属性可以被修改、删除、添加。
下面举个简单的例子进行介绍:
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup('荣仔', "html.parser")
tag = soup.b
print(tag)
print(type(tag))
# NAME
print(tag.name)
print(tag.string)
# Attributes
print(tag.attrs)
print(tag['class'])
print(tag.get('id'))
# 修改属性,增加属性name
tag['class'] = 'abc'
tag['id'] = '1'
tag['name'] = '2'
print(tag)
# 删除属性
del tag['class']
del tag['name']
print(tag)
# print(tag['class']) # 此语句会报错
3.1.2 NavigableString
前面介绍了如何获取标签的 name 和 attrs,如果想获取标签对应的内容,可以使用 string 属性获取。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.a['class'])
print(soup.a.string)
由上述代码可以看出,利用 string 属性获取标签 <> 和 之间的内容要比利用正则表达式方便得多。
BeautifulSoup 用 NavigableString 类来包装 Tag 中的字符串,其中,NavigableString 表示可遍历的字符串。一个 NavigableString 字符串与 Python 中的 Unicode 字符串相同,并且支持包含在遍历文档树和搜索文档树中的一些特性。
# 该段代码用来查看 NavigableString 的类型
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
print(type(tag.string))
当然,通过 unicode() 方法可以直接将 NavigableString 对象转化成 Unicode 字符串。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)最后再说明一点,标签中包含的字符串不能编辑,但是可以被替换成其他的字符串,用 replace_with() 方法即可实现
tag.string.replace("替换前的内容", " 替换后的内容 ")
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)
a = tag.string.replace("BeautifulSoup 技术", " NavigableString ")
print(a)
3.1.3 BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容,通常情况下把它当做 Tag 对象。 BeautifulSoup 对象支持遍历文档树和搜索文档树中描述的大部分方法。
type(soup)
# 上述代码为调用 type() 函数查看 soup 变量的数据类型,即为 BeautifulSoup 对象类型。因为 BeautifulSoup 对象并不是真正的 HTML 和 XML 标签 Tag,所以它没有 name 和 attrs 属性。
但有时候查看 BeautifulSoup 对象的 “.name ” 属性是很方便的,因为其包含了一个值为“[ document ]”的特殊属性——soup.name。
soup.name
# [document]3.1.4 Comment
Comment 对象是一个特殊类型的 NavigableString 对象,用于处理注释对象。
# 本段代码用于读取注释内容
from bs4 import BeautifulSoup
markup = ""
soup = BeautifulSoup(markup, "html.parser")
comment = soup.b.string
print(type(comment))
print(comment)
3.2 遍历文档树
在 BeautifulSoup 中,一个标签可能包含多个字符串或其他的标签,这些称为该标签的子标签。
3.2.1 子节点
在 BeautifulSoup 中通过 contents 值获取标签的子节点内容,并以列表的形式输出。
# 本段代码用于获取 标签子节点内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.contents) 由于
由于
print(soup.head.contents[3])
当然,也可以使用 children 关键字获取,但它返回的不是一个列表,而是可以通过遍历的方法获取所有子节点的内容
print(soup.head.children)
for child in soup.head.children:
print(child)
前面介绍的 contents 和 children 属性仅包含标签的直接子节点,如果需要获取 Tag 的所有子节点,甚至是子孙节点,则需要使用 descendants 属性。
for child in soup.descendants:
print(child) 很显然,所有的 HTML 标签都打印出来了。
很显然,所有的 HTML 标签都打印出来了。
3.2.2 节点内容
如果标签只有一个子节点,且需要获取该子节点的内容,则使用 string 属性输出子节点的内容,通常返回嘴里层的标签内容。
# 本段代码用于获取标题内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.string)
print(soup.title.string) 从上述代码可以看出,当标签含有多个子节点时(
从上述代码可以看出,当标签含有多个子节点时(
若需要获取多个节点内容,则使用 strings 属性
for content in soup.strings:
print(content) 这时我们发现一个问题,就是包含过多的空格或者换行,此时就需要使用 stripped_strings 方法去除多余的空白内容
这时我们发现一个问题,就是包含过多的空格或者换行,此时就需要使用 stripped_strings 方法去除多余的空白内容
for content in soup.stripped_strings:
print(content)
3.2.3 父节点
调用 parent 属性定位父节点,如果需要获取节点的标签名则使用 parent,name 。
p = soup.p
print(p.parent)
print(p.parent.name)
content = soup.head.title.string
print(content.parent)
print(content.parent.name)
如果需要获取所有的父节点,则使用 parents 属性循环获取
content = soup.head.title.string
for parent in content.parents:
print(parent.name)
3.2.4 兄弟节点
兄弟节点是指和本节点位于同一级的节点,其中,next_sibling 属性是获取该节点的下一个兄弟节点,precious_sibling 则与之相反,取该节点的上一个兄弟节点,如果节点不存在,则返回 None。
print(soup.p.next_sibling)
print(soup.p.precious_sinling)
值得注意的是,实际文档中 Tag 的 next_sibling 和 previous_sibling 属性通常都是字符串或者空白,因为空白或者韩航也可以被视作一个节点,所以可到的结果可能是空白或换行。
3.2.5 前后节点
调用属性 next_element 可以获取下一个节点,调用属性 precious_element 可以获取上一个节点。
print(soup.p.next_element)
print(soup.p.precious_element)
3.3 搜索文档树
对于搜索文档树,最常用的方法是 find_all() 方法。
如果行从网页中得到所有的 标签,则使用 find_all() 方法的代码如下
urls = soup.find_all('a')
for url in urls:
print(url)
同样,该函数支持传入正则表达式作为参数,BeautifulSoup 会通过正则表达式的 match() 来匹配内容。
下面代码示例是找出所有以 b 开头的标签:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
同样,如果想过去标签 a 和标签 b 的值,则可以使用下面的函数
soup.find_all(["a", "b"])注意:fina_all() 函数是可以接收参数进行指定节点查询的
soup.find_all(id="link1")同样,也可以接受多个参数,比如:
soup.find_all("a", class_="poet") # 得到一个列表
至此,整个 BeautifulSoup 技术已经讲完,可以看出其比前面的正则表达式方便很多,而其爬取的函数也只能很多。
4 本文总结
BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取所需数据的 Python 库,这里把它看作是一种技术。一方面,BeautifuSoup 具有智能化爬取网页信息的强大功能,对比前面的正则表达式爬虫,其具有较好的便捷性和适用性,通过在途整个网页文档并调用相关函数定位所需信息的节点,再爬取相关内容;另一方面,BeautifulSoup 适用起来比较简单,API 非常人性化,采用类似于 XPath 的分析技术定位标签,并且支持 CSS 选择器,开发效率相对较高,被广泛应用于 Python 数据爬取领域。
欢迎留言,一起学习交流~
感谢阅读