关于《后浪》的B站弹幕分析总结(五)——Python实现情感分析、情绪分析以及可视化
目录
- 一、利用百度ai做情感分析
- 二、使用pyechats可视化实现动态图表
- 三、情绪分析的方法
相关内容:
- B站视频《[数说弹幕]我不小心看了后浪弹幕》
- 关于《后浪》的B站弹幕分析总结(一)——爬取B站视频的上万条弹幕的方法
- 关于《后浪》的B站弹幕分析总结(二)——分词常用的词典、颜文字处理以及格式统一
- 关于《后浪》的B站弹幕分析总结(三)——怎么制作好看的交互式词云
- 关于《后浪》的B站弹幕分析总结(四)——Python实现LDA内容主题挖掘及主题可视化
情感分析常见的研究中都按照三分类(正向、中性、负向)的方式进行,也有7分类甚至更多维度的分类,本文为了区别开将三分类称为情感分析,7分类的称为情绪分析。
按照处理文本的颗粒度的性质情感分析可以分为文档级情感分析、句子级情感分析、属性级请按分析等。
无论哪种分析方法对于个人都是长期且巨大的工程,所以这里推荐使用情感分析的工具。
一、利用百度ai做情感分析
百度ai的这个功能只能够区分正向、中性、负向,多分类还不可以。
https://ai.baidu.com/?track=cp:aipinzhuan|pf:pc|pp:AIpingtai|pu:title|ci:|kw:10005792

在自然语言处理下创建应用,选择情感倾向分析,你会得到你的三个码。后面程序中需要用到。
| AppID | API Key | Secret Key |
|---|
使用python连接你的应用,百度的这个功能是可以免费调用500000次的,不知道什么时候他就会不免费了,所以趁现在可以多用用。
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = '你的AppID'
API_KEY = '你的APIKey'
SECRET_KEY = '你的Secret Key'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
def get_sentiments(text,i):
try:
sitems=client.sentimentClassify(text)['items'][0]#情感分析
positive=sitems['positive_prob']#积极概率
confidence=sitems['confidence']#置信度
sentiment=sitems['sentiment']#0表示消极,1表示中性,2表示积极 output='{}\t{}\t{}\t{}\n'.format(i,positive,confidence,sentiment)
f=codecs.open('sentiment.xls','a+','utf-8')
f.write(output)
f.close()
print('Done')
except Exception as e:
print(e)
for i in range(len(data_code)):
print('正在处理第{}条,还剩{}条'.format(i,data_df.shape[0]-i))
view= data_code[i]
print(view)
get_sentiments(view,i)
这个程序运行后,就可以看到界面上在一条一条处理语句,我的是1万8千条数据,大概需要处理1个小时。
正在处理第1条,还剩18499条
君子美美与共,和而不同
Done
正在处理第2条,还剩18498条
后浪
Done
正在处理第3条,还剩18497条
啊是青青!!
Done
正在处理第4条,还剩18496条
复旦之光!!
但是百度ai也不是非常好用,比如‘’奔涌吧,后浪‘’这句话就处理成了负向,需要做一下调整。其实这里做的有点粗糙了,在文本上还可以做些处理。
二、使用pyechats可视化实现动态图表
因为我想要看到一个每天都在变化的情感正负向情况,所以借助到pyechats的timeline。
from pyecharts import options as opts
from pyecharts.charts import Pie, Timeline
from pyecharts.faker import Faker
attr = list(data_sen1.index)
tl = Timeline()
for i in list(data_sen1.columns):
pie = (
Pie()
.add(
"弹幕",
[list(z) for z in zip(attr, list(data_sen1[i]))],
rosetype="radius",
radius=["30%", "55%"],
)
.set_global_opts(title_opts=opts.TitleOpts("情感分析".format(i)))
)
tl.add(pie, "{}".format(i))
tl.render("timeline_pie.html")
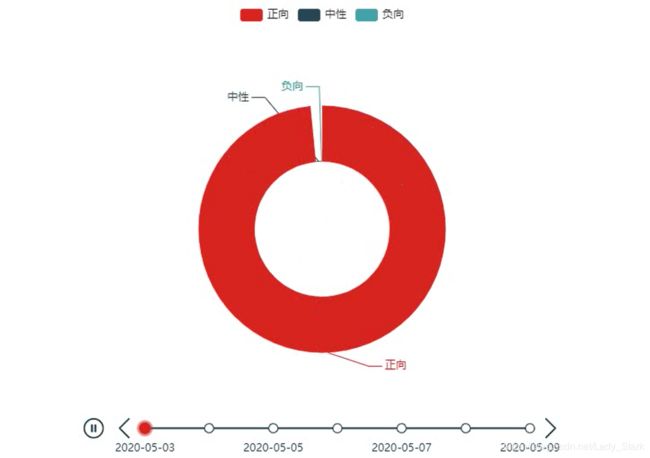
这个图会根据时间轴每天发生变化,具体可以看我的视频。
三、情绪分析的方法
这个其实内容很大,简单介绍一下,感兴趣的可以自己查资料,以后有时间我会详细写一下这部分内容。本文的思路是参考《情感分析及可视化方法在网络视频弹幕数据分析中的应用》这篇论文。
这里介绍一种基于词典的方法。首先你需要建立自己的情绪分析词典,将情绪划分为7种,如同我在总结(二)中介绍的喜、怒、忧、思、悲、恐、惊,当然网上也有很多类似的词典可以下载,一定要是针对这种网络评论用语的词典才好,因为网络文化还是和日常用语不太一样。然后将你的文档做分词,分词完根据词典做分类,同时要注意去停用词,根据极性副词做一个增加情感强度或弱化情感强度的处理,一般思路为如果增强情感的则乘以一个大于1的数,如果弱化情感的则乘以一个小于1的数。取情感值最大的作为句子的情绪。还有否定词怎么处理的问题等等。
当然这样的思路也有一些问题,因为你只是做了句子级的情绪分类,还需要做属性级的情绪分类才能判断真实意图。
工具有吗,当然有,可以看看微博舆情网站的情绪分析,其他工具可以评论交流。