Chromium硬件加速渲染的OpenGL上下文调度过程分析
Chromium的每一个WebGL端、Render端和Browser端实例在GPU进程中都有一个OpenGL上下文。这些OpenGL上下文运行在相同线程中,因此同一时刻只有一个OpenGL上下文处于运行状态。这就引发出一个OpenGL上下文调度问题。此外,事情有轻重缓急,OpenGL上下文也有优先级高低之分,优先级高的要保证它的运行时间。本文接下来就分析GPU进程调度运行OpenGL上下文的过程。
老罗的新浪微博:http://weibo.com/shengyangluo,欢迎关注!
《Android系统源代码情景分析》一书正在进击的程序员网(http://0xcc0xcd.com)中连载,点击进入!
在前面Chromium硬件加速渲染机制基础知识简要介绍和学习计划一文中提到,GPU进程中的所有OpenGL上下文不仅运行在相同线程中,即运行在GPU进程的GPU线程中,它们还处于同一个共享组中,如图1所示:

图1 OpenGL上下文
在Chromium中,每一个OpenGL上下文使用一个GLContextEGL对象描述。每一个OpenGL上下文都关联有一个绘图表面。对于WebGL端和Render端的OpenGL上下文来说,它关联的绘图表面是一个离屏表面。这个离屏表面一般就是用一个Pbuffer描述。在Android平台上,Browser端的OpenGL上下文关联的绘图表面是一个SurfaceView。
当一个OpenGL上下文被调度时,它以及它关联的绘图表面就会通过调用EGL函数eglMakeCurrent设置为GPU线程当前使用的OpenGL上下文和绘图表面。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文又可以知道,Chromium为WebGL端、Render端和Browser端创建的OpenGL上下文可能是虚拟的,如图2所示:
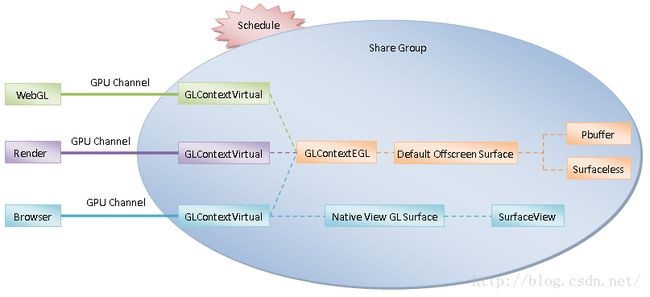
图2 虚拟OpenGL上下文
在Chromium中,每一个虚拟OpenGL上下文都使用一个GLContextVirtual对象描述。每一个虚拟OpenGL上下文都对应有一个真实OpenGL上下文,即一个GLContextEGL对象,并且所有的虚拟OpenGL上下文对应的真实OpenGL上下文都是相同的。虚拟OpenGL上下文也像真实OpenGL上下文一样,关联有绘图表面。对于WebGL端和Render端的虚拟OpenGL上下文来说,它关联的绘图表面也是一个使用Pbuffer描述的离屏表面。在Android平台上,Browser端的OpenGL上下文关联的绘图表面同样也是一个SurfaceView。
当一个虚拟OpenGL上下文被调度时,它对应的真实OpenGL上下文以及它关联的绘图表面就会通过调用EGL函数eglMakeCurrent设置为GPU线程当前使用的OpenGL上下文和绘图表面。由于所有的虚拟OpenGL上下文对应的真实OpenGL上下文都是相同的,因此当一个虚拟OpenGL上下文被调度时,只需要通过调用EGL函数eglMakeCurrent将其关联的绘图表面设置为GPU线程当前使用的绘图表面即可。
前面提到,OpenGL上下文有优先级高低之分,具体表现为Browser端的OpenGL上下文优先级比WebGL端和Render端的高。这是因为前者负责合成后者的UI显示在屏幕中,因此就要保证它的运行时间。在Browser端的OpenGL上下文需要调度运行而GPU线程又被其它OpenGL上下文占有时,Browser端的OpenGL上下文就可以抢占GPU线程。为达到这一目的,Chromium给Browser端与GPU进程建立的GPU通道设置IDLE、WAITING、CHECKING、WOULD_PREEMPT_DESCHEDULED和PREEMPTING五个状态。这五个状态的变迁关系如图3所示:

图3 GPU通道状态变迁图
当Browser端的GPU通道处于PREEMPTING状态时,Browser端的OpenGL上下文就可以要求其它OpenGL上下文停止执行手头上的任务,以便将GPU线程交出来运行Browser端的OpenGL上下文。
Browser端的GPU通道开始时处于IDLE状态。当有未处理IPC消息时,就从IDLE状态进入WAITING状态。进入WAITING状态kPreemptWaitTimeMs毫秒之后,就自动进入CHECKING状态。kPreemptWaitTimeMs毫秒等于2个kVsyncIntervalMs毫秒,kVsyncIntervalMs定义为17。假设屏幕的刷新速度是60fps,那么kVsyncIntervalMs毫秒刚好就是一个Vsync时间,即一次屏幕刷新时间间隔。
处于CHECKING状态期间时,Browser端的GPU通道会不断检查最早接收到的未处理IPC消息流逝的时间是否小于2次屏幕刷新时间间隔。如果小于,那么就继续停留在CHECKING状态。否则的话,就进入WOULD_PREEMPT_DESCHEDULED状态或者PREEMPTING状态。图1所示的stub指的是一个GpuCommandBufferStub对象。从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,在GPU进程中,一个GpuCommandBufferStub对象描述的就是一个OpenGL上下文。因此,图1所示的stub指的是一个Browser端OpenGL上下文。
处于CHECKING状态期间时,如果最早接收到的未处理IPC消息流逝的时间大于等于2次屏幕刷新时间间隔,并且没有任何的Browser端OpenGL上下文自行放弃调度,那么Browser端的GPU通道就会进入PREEMPTING状态,表示它要抢占GPU线程,也表示要求当前正在调度的OpenGL上下文放弃占有GPU线程。另一方面,如果这时候至少有一个Browser端OpenGL上下文自行放弃调度,那么Browser端的GPU通道就会进入WOULD_PREEMPT_DESCHEDULED状态,表示它现在不急于抢占GPU线程,因为这时候有OpenGL上下文自行放弃了调度,从而使得最早接收到的未处理消息所属的OpenGL上下文得到调度处理。
处于WOULD_PREEMPT_DESCHEDULED状态时,Browser端的GPU通道会继续检查是否有Browser端OpenGL上下文自行放弃调度。如果没有,那么就进入PREEMPTING状态,表示要抢占GPU线程。如果有,并且这时候Browser端的GPU通道接收到的IPC消息均已被处理,或者最早接收到的未处理IPC消息的流逝时间小于kStopPreemptThresholdMs毫秒,那么就进入IDLE状态。否则的话,就继续维持WOULD_PREEMPT_DESCHEDULED状态。kStopPreemptThresholdMs也定义为17,意思是Browser端的GPU通道处于WOULD_PREEMPT_DESCHEDULED状态时,允许最早接收到的未处理IPC消息延迟一次屏幕刷新时间间隔再进行处理。
Browser端的GPU通道处于PREEMPTING状态的最长时间为kMaxPreemptTimeMs毫秒。kMaxPreemptTimeMs也定义为17,意思是Browser端的GPU通道抢占GPU线程的时间不能超过一个屏幕刷新时间间隔。如果超过了一个屏幕刷新时间间隔,那么就会进入IDLE状态。
在处于PREEMPTING状态期间,如果Browser端的GPU通道接收到的IPC消息均已被处理,或者最早接收到的未处理IPC消息的流逝时间小于kStopPreemptThresholdMs毫秒,那么Browser端的GPU通道也会进入IDLE状态。此外,在处于PREEMPTING状态期间,如果至少有一个Browser端OpenGL上下文自行放弃调度,那么Browser端的GPU通道就会进入WOULD_PREEMPT_DESCHEDULED状态。
注意,在图3所示的状态变迁图中,只有处于PREEMPTING状态时,Browser端的GPU通道才会强行抢占GPU线程。这是为了保证Browser端的OpenGL上下文,至少应该需要在两个屏幕刷新时间间隔之内,得到一次调度,从而保证网页UI得到刷新和及时显示。WebGL端和Render端的OpenGL上下文就没有这种待遇,毕竟它们的优先级没有Browser端的OpenGL上下文高。
Browser端GPU通道是以什么方式强行抢占GPU线程的呢?我们通过图4说明,如下所示:

图4 抢占GPU线程
Browser端GPU通道有一个Preemption Flag。当它处于PREEMPTING状态时,就会将Preemption Flag设置为True。WebGL端和Render端GPU通道可以访问Browser端GPU通道的Preemption Flag。属于WebGL端和Render端GPU通道的OpenGL上下文在调度期间,会不断地检查Browser端GPU通道的Preemption Flag是否被设置为True。如果被设置为True,那么它就会中止执行,提前释放GPU线程。
WebGL端和Render端GPU通道和Browser端GPU通道是父子关系。其中, WebGL端和Render端GPU通道是儿子,Browser端GPU通道是父亲。Chromium规定,儿子GPU通道可以访问父亲GPU通道的Preemption Flag。有了前面这些背景知识之后,接下来我们就结合源码分析OpenGL上下文的调度过程。
从前面Chromium的GPU进程启动过程分析一文可以知道,GPU进程通过调用GpuChannel类的成员函数Init创建GPU通道,如下所示:
void GpuChannel::Init(base::MessageLoopProxy* io_message_loop,
base::WaitableEvent* shutdown_event) {
......
channel_ = IPC::SyncChannel::Create(channel_id_,
IPC::Channel::MODE_SERVER,
this,
io_message_loop,
false,
shutdown_event);
filter_ =
new GpuChannelMessageFilter(weak_factory_.GetWeakPtr(),
gpu_channel_manager_->sync_point_manager(),
base::MessageLoopProxy::current());
......
channel_->AddFilter(filter_.get());
......
} 结合前面Chromium的IPC消息发送、接收和分发机制分析一文可以知道,WebGL端、Render端和Browser端发送过来的GPU消息由GpuChannel类的成员函数OnMessageReceived负责接收。在接收之前,这些GPU消息首先会被GpuChannel类的成员变量filter_指向的一个GpuChannelMessageFilter对象的成员函数OnMessageReceived过滤。
注意,GpuChannel类的成员函数Init是在GPU线程中执行的,这意味着GpuChannel类的成员函数OnMessageReceived也将会在GPU线程中执行,但是它的成员变量filter_指向的GpuChannelMessageFilter对象的成员函数OnMessageReceived不是在GPU线程执行的,而是在负责接收IPC消息的IO线程中执行的。
接下来我们先分析GpuChannel类的成员函数OnMessageReceived的实现,后面分析Browser端GPU通道抢占GPU线程的过程时,再分析GpuChannelMessageFilter类的成员函数OnMessageReceived的实现。
GpuChannel类的成员函数OnMessageReceived的实现如下所示:
bool GpuChannel::OnMessageReceived(const IPC::Message& message) {
......
if (message.type() == GpuCommandBufferMsg_WaitForTokenInRange::ID ||
message.type() == GpuCommandBufferMsg_WaitForGetOffsetInRange::ID) {
// Move Wait commands to the head of the queue, so the renderer
// doesn't have to wait any longer than necessary.
deferred_messages_.push_front(new IPC::Message(message));
} else {
deferred_messages_.push_back(new IPC::Message(message));
}
OnScheduled();
return true;
}GpuChannel类将接收到的IPC消息保存在成员变量deferred_messages_描述的一个std::deque中。其中,类型为GpuCommandBufferMsg_WaitForTokenInRange和GpuCommandBufferMsg_WaitForGetOffsetInRange的GPU消息将会保存在上述std::deque的头部,而其它GPU消息则保存在上述std::deque的末部。
从前面Chromium硬件加速渲染的OpenGL命令执行过程分析和Chromium硬件加速渲染的GPU数据上传机制分析这篇文章可以知道,当GPU进程接收到类型为GpuCommandBufferMsg_WaitForTokenInRange和GpuCommandBufferMsg_WaitForGetOffsetInRange的IPC消息时,就表示它的Client端,即WebGL端、Render端和Browser端,正在检查其GPU命令缓冲区的执行情况,需要尽快得到结果,因此就需要将它们放在上述std::deque的头部,以便尽快得到处理。
GpuChannel类的成员函数OnMessageReceived将接收到的GPU消息保存在成员变量deferred_messages_描述的std::deque之后,接下来调用另外一个成员函数OnScheduled对它们进行调度处理,如下所示:
void GpuChannel::OnScheduled() {
if (handle_messages_scheduled_)
return;
// Post a task to handle any deferred messages. The deferred message queue is
// not emptied here, which ensures that OnMessageReceived will continue to
// defer newly received messages until the ones in the queue have all been
// handled by HandleMessage. HandleMessage is invoked as a
// task to prevent reentrancy.
base::MessageLoop::current()->PostTask(
FROM_HERE,
base::Bind(&GpuChannel::HandleMessage, weak_factory_.GetWeakPtr()));
handle_messages_scheduled_ = true;
}GpuChannel类的成员函数OnScheduled通过向GPU线程的消息队列发送一个Task请求为当前接收到GPU消息的GPU通道执行一次调度。该Task绑定的函数为GpuChannel类的成员函数HandleMessage。
GpuChannel类的成员变量handle_messages_scheduled_的值等于true时,表示当前接收到GPU消息的GPU通道已经请求过调度了,并且请求的调度还没有被执行。在这种情况下,就不必再向GPU线程的消息队列发送Task。
GpuChannel类的成员函数HandleMessage的实现如下所示:
void GpuChannel::HandleMessage() {
handle_messages_scheduled_ = false;
if (deferred_messages_.empty())
return;
bool should_fast_track_ack = false;
IPC::Message* m = deferred_messages_.front();
GpuCommandBufferStub* stub = stubs_.Lookup(m->routing_id());
do {
if (stub) {
if (!stub->IsScheduled())
return;
if (stub->IsPreempted()) {
OnScheduled();
return;
}
}
scoped_ptr message(m);
deferred_messages_.pop_front();
bool message_processed = true;
currently_processing_message_ = message.get();
bool result;
if (message->routing_id() == MSG_ROUTING_CONTROL)
result = OnControlMessageReceived(*message);
else
result = router_.RouteMessage(*message);
currently_processing_message_ = NULL;
if (!result) {
// Respond to sync messages even if router failed to route.
if (message->is_sync()) {
IPC::Message* reply = IPC::SyncMessage::GenerateReply(&*message);
reply->set_reply_error();
Send(reply);
}
} else {
// If the command buffer becomes unscheduled as a result of handling the
// message but still has more commands to process, synthesize an IPC
// message to flush that command buffer.
if (stub) {
if (stub->HasUnprocessedCommands()) {
deferred_messages_.push_front(new GpuCommandBufferMsg_Rescheduled(
stub->route_id()));
message_processed = false;
}
}
}
if (message_processed)
MessageProcessed();
// We want the EchoACK following the SwapBuffers to be sent as close as
// possible, avoiding scheduling other channels in the meantime.
should_fast_track_ack = false;
if (!deferred_messages_.empty()) {
m = deferred_messages_.front();
stub = stubs_.Lookup(m->routing_id());
should_fast_track_ack =
(m->type() == GpuCommandBufferMsg_Echo::ID) &&
stub && stub->IsScheduled();
}
} while (should_fast_track_ack);
if (!deferred_messages_.empty()) {
OnScheduled();
}
} GpuChannel类的成员函数HandleMessage首先检查成员变量deferred_messages_描述的一个std::deque是否为空。如果为空,那么就说明没有未处理的GPU消息,因此就直接返回。否则的话,就取出头部的GPU消息m,并且根据这个GPU消息的Routing ID找到负责接收的一个GpuCommandBufferStub对象stub。
GpuChannel类的成员函数HandleMessage将GPU消息m分发给GpuCommandBufferStub对象stub处理之前,首先检查GpuCommandBufferStub对象stub是否自行放弃了调度,以及是否被抢占调度。如果GpuCommandBufferStub对象stub自行放弃了调度,那么调用它的成员函数IsScheduled获得的返回值就为false。如果GpuCommandBufferStub对象stub被抢占了调度,那么调用它的成员函数IsPreempted获得的返回值就为true。在前一种情况下,GpuChannel类的成员函数HandleMessage什么也不做就返回。在后一种情况下,GpuChannel类的成员函数HandleMessage调用前面分析过的成员函数OnScheduled向GPU线程的消息队列的末尾发送一个调度用的Task,也就是先将GPU线程让出来,以便GPU线程执行排在GPU线程消息队列头部的Task。根据前面的分析,这时候排在GPU线程消息队列头部的Task可能就是用来调度Browser端OpenGL上下文的。
如果GpuCommandBufferStub对象stub既没有自行放弃调度,也没有被抢占调度,那么接下来GpuChannel类的成员函数HandleMessage就会对GPU消息m进行处理。如果GPU消息m的Routing ID等于MSG_ROUTING_CONTROL,那么就说明它是一个控制类型的GPU消息,这时候就将它分发给GpuChannel类的成员函数OnControlMessageReceived处理。否则的话,就调用成员变量router_描述的一个MessageRouter对象的成员函数RouteMessage将GPU消息m分发给GpuCommandBufferStub对象stub的成员函数OnMessageReceived处理。
如果GPU消息m描述的是一个认识的GPU操作,那么前面调用GpuChannel类的成员函数OnControlMessageReceived或者调用GpuChannel类的成员变量router_描述的MessageRouter对象的成员函数RouteMessage得到的返回值就为true。这时候GpuChannel类的成员函数HandleMessage会继续调用GpuCommandBufferStub对象stub的成员函数HasUnprocessedCommands判断它的GPU命令缓冲区是否还有命令未被处理。如果是的话,就向成员变量deferred_messages_描述的一个std::deque的头部插入一个类型为GpuCommandBufferMsg_Rescheduled的GPU消息,并且将本地变量message_processed的值设置为false。当上述GpuCommandBufferMsg_Rescheduled消息被处理时,GPU线程就会继续执行GpuCommandBufferStub对象stub的GPU命令缓冲区中的未处理命令。将本地变量message_processed设置为false,表示后面不要调用GpuChannel类的成员函数MessageProcessed。
另一方面,如果GPU消息m描述的是一个不认识的GPU操作,那么前面调用GpuChannel类的成员函数OnControlMessageReceived或者调用GpuChannel类的成员变量router_描述的MessageRouter对象的成员函数RouteMessage得到的返回值就为false。这时候GpuChannel类的成员函数HandleMessage就会继续检查GPU消息m是否是一个同步类型的GPU消息。如果是的话,那么就向发送该GPU消息的Client端发送一个回复消息,以便该Client端可以结束等待。如果GPU消息m描述的是一个认识的GPU操作,那么该回复消息就是由负责处理GPU消息m的函数发出的。现在既然没有函数处理GPU消息m,因此GpuChannel类的成员函数HandleMessage就要负责回复该GPU消息,以便不让发送该GPU消息的Client端一直等待下去。
GpuChannel类的成员函数HandleMessage接下来判断本地变量message_processed的值是否等于true。如果等于true,那么就代表前面完整地处理完成了一个GPU消息,这时候就调用另外一个成员函数MessageProcessed告知前面提到的成员变量filter_描述的一个GpuChannelMessageFilter对象,当前正在被调度的GPU通道处理完成了一个GPU消息,以便该GpuChannelMessageFilter对象可以更新当前正在被调度的GPU通道的状态。后面我们分析Browser端OpenGL上下文抢占GPU线程时,再分析GpuChannel类的成员函数MessageProcessed的实现。
从前面的分析可以知道,本地变量message_processed的值只有一种情况等于false,那就是GpuCommandBufferStub对象stub的GPU命令缓冲区还有未处理命令。这种情况出现在GpuCommandBufferStub对象stub接收到了一个类型为GpuCommandBufferMsg_AsyncFlush的GPU消息。从前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文可以知道,当一个GpuCommandBufferStub对象接收到一个类型为GpuCommandBufferMsg_AsyncFlush的GPU消息时,就会调用GpuScheduler类的成员函数PutChanged处理该GpuCommandBufferStub对象的GPU命令缓冲区新提交的命令,如下所示:
void GpuScheduler::PutChanged() {
......
if (!IsScheduled())
return;
while (!parser_->IsEmpty()) {
if (IsPreempted())
break;
......
error = parser_->ProcessCommand();
......
}
......
} 然而,有可能接收到类型为GpuCommandBufferMsg_AsyncFlush的GPU消息的GpuCommandBufferStub对象自行放弃了调度,或者被抢占了调度。前者表现为调用GpuScheduler类的成员函数IsScheduled获得的返回值为false,而后者表现为调用GpuScheduler类的成员函数IsPreempted获得的返回值为true。在这两种情况下,上述GpuCommandBufferStub对象的GPU命令缓冲区新提交的命令没有全部得到处理。这相当于是说接收到的GpuCommandBufferMsg_AsyncFlush消息并没有得到完整处理。因此,GpuChannel类的成员函数HandleMessage就不会调用成员函数MessageProcessed告知前面提到的成员变量filter_描述的一个GpuChannelMessageFilter对象,当前正在被调度的GPU通道处理完成了一个GPU消息。
回到GpuChannel类的成员函数HandleMessage中,它接下来检查成员变量deferred_messages_描述的std::deque是否还有待处理GPU消息。如果有,并且下一个待处理的GPU消息是一个类型为GpuCommandBufferMsg_Echo的GPU消息,并且负责处理该GpuCommandBufferMsg_Echo消息的GpuCommandBufferStub对象没有自行放弃调度,那么就需要继续处理该GpuCommandBufferMsg_Echo消息后才返回。
当一个GPU进程的Client端,例如一个Render端,完成自已的网页UI的绘制后,就会向GPU进程发送一个GPU消息,请求对Browser端OpenGL上下文合成该网页UI,并且显示在屏幕中。紧跟在该GPU消息后面的是一个GpuCommandBufferMsg_Echo消息。一个GpuCommandBufferStub对象接收到一个GpuCommandBufferMsg_Echo消息之后,要马上对该消息进行回复。Client端接收到这个回复消息之后,就可以知道前面已经绘制完成的网页UI已经被合成显示在屏幕中了,于是就可以执行一些清理工作,例如回收资源。这些清理操作越快进行越好,因此就要求类型为GpuCommandBufferMsg_Echo的GPU消息要尽快处理。
如果GpuChannel类的成员函数HandleMessage处理完成GPU消息m后,如果还有待处理的GPU消息,并且这个待处理的GPU消息不是一个类型为GpuCommandBufferMsg_Echo的GPU消息,那么这个待处理的GPU消息将会在负责处理它的GpuCommandBufferStub对象下一次被调度时才会处理。由此可见,GpuChannel类的成员函数HandleMessage一般情况下只会处理一个GPU消息。这就是为了让其它GpuCommandBufferStub对象也有机会处理自己的GPU消息的。
前面提到,如果当前处理的GPU消息不是一个控制类型为的GPU消息,那么GpuChannel类的成员函数HandleMessage会将它分发给对应的GpuCommandBufferStub对象的成员函数OnMessageReceived处理,处理过程如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
if (decoder_.get() && message.type() != GpuCommandBufferMsg_Echo::ID &&
message.type() != GpuCommandBufferMsg_WaitForTokenInRange::ID &&
message.type() != GpuCommandBufferMsg_WaitForGetOffsetInRange::ID &&
message.type() != GpuCommandBufferMsg_RetireSyncPoint::ID &&
message.type() != GpuCommandBufferMsg_SetLatencyInfo::ID) {
if (!MakeCurrent())
return false;
......
}
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER(GpuCommandBufferMsg_AsyncFlush, OnAsyncFlush);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
......
return handled;
}除了以下五个GPU消息,其余的GPU消息均要求调用成员GpuCommandBufferStub类的成员函数MakeCurrent将当前正在处理的GpuCommandBufferStub对象描述的OpenGL上下文设置为GPU线程当前激活的OpenGL上下文之后再处理:
1. GpuCommandBufferMsg_Echo
2. GpuCommandBufferMsg_WaitForTokenInRange
3. GpuCommandBufferMsg_WaitForGetOffsetInRange
4. GpuCommandBufferMsg_RetireSyncPoint
5. GpuCommandBufferMsg_SetLatencyInfo
第1个GPU消息的作用可以参考前面的分析。第2个GPU消息是GPU进程的Client端回收共享缓冲区时发送过来的,具体可以参考前面Chromium硬件加速渲染的GPU数据上传机制分析一文。第3个GPU消息是GPU进程的Client端等待GPU命令缓冲区的命令被处理时发送过来的,具体可以参考前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文。第4个GPU消息与我们后面要分析的Sync Point机制相关。第5个GPU消息是GPU进程的Client端用来告诉GPU进程它的UI绘制完成后多长时间可以用来合成到浏览器窗口中显示出来。
以GpuCommandBufferMsg_AsyncFlush消息为例,GPU线程对它的处理就是执行GPU命令缓冲区新提交的GPU命令,也就是调用相应的OpenGL函数,而调用这些OpenGL函数就必须要在发送GpuCommandBufferMsg_AsyncFlush消息的Client端的OpenGL上下文中进行。因此,GpuCommandBufferStub类的成员函数OnMessageReceived就需要调用成员函数MakeCurrent将发送GpuCommandBufferMsg_AsyncFlush消息的Client端的OpenGL上下文设置为GPU线程当前激活的OpenGL上下文,即切换GPU线程的OpenGL上下文。
切换GPU线程的OpenGL上下文是OpenGL上下文调度过程的重要一环,因此接下来我们继续分析GpuCommandBufferStub类的成员函数MakeCurrent的实现,如下所示:
bool GpuCommandBufferStub::MakeCurrent() {
if (decoder_->MakeCurrent())
return true;
......
return false;
}从前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文可以知道,GpuCommandBufferStub类的成员变量decoder_描述的是一个GLES2CmdDecoderImpl对象,这里调用这个GLES2CmdDecoderImpl对象的成员函数MakeCurrent切换GPU线程的OpenGL上下文,切换过程如下所示:
bool GLES2DecoderImpl::MakeCurrent() {
......
if (!context_->MakeCurrent(surface_.get()) || WasContextLost()) {
......
return false;
}
ProcessFinishedAsyncTransfers();
// Rebind the FBO if it was unbound by the context.
if (workarounds().unbind_fbo_on_context_switch)
RestoreFramebufferBindings();
......
return true;
}GLES2CmdDecoderImpl类的成员函数MakeCurrent主要做了以下三件事情:
1. 调用成员变量context_描述的一个gfx::GLContext对象的成员函数MakeCurrent切换GPU线程的OpenGL上下文,也就是将当前正在处理的GLES2CmdDecoderImpl对象对应的OpenGL上下文设置为GPU线程当前激活的OpenGL上下文。
2. 调用成员函数ProcessFinishedAsyncTransfers处理那些已经异步上传完成了数据的纹理,这个过程可以参考前面Chromium硬件加速渲染的GPU数据上传机制分析一文。
3. 有些GPU,例如Vivante和Imagination的GPU,如果一个OpenGL上下文调用OpenGL函数glBindFramebuffer绑定过FBO,那么当该OpenGL上下文被切换出去后又被切换回来时,之前绑定过的FBO不会自动被绑定,这时候就需要调用成员函数RestoreFramebufferBindings重新绑定之前被绑定的FBO。
我们主要关注上述的第一件事情。从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,GLES2CmdDecoderImpl类的成员context_实际描述的要么是一个GLContextEGL对象,要么是一个GLContextVirtual对象,分别表示当前正在处理的GLES2CmdDecoderImpl对象对应的OpenGL上下文使用的是真实OpenGL上下文和虚拟OpenGL上下文。
接下来我们就先分析真实OpenGL上下文的切换过程,即GLContextEGL类的成员函数MakeCurrent的实现,接着再分析虚拟OpenGL上下文的切换过程,即GLContextVirtual类的成员函数MakeCurrent的实现。
GLContextEGL类的成员函数MakeCurrent的实现如下所示:
bool GLContextEGL::MakeCurrent(GLSurface* surface) {
.....
if (!eglMakeCurrent(display_,
surface->GetHandle(),
surface->GetHandle(),
context_)) {
......
return false;
}
......
return true;
}参数surface描述的是一个要切换至的OpenGL上下文的绘图表面,而GLContextEGL类的成员变量context_描述的就是要切换至的OpenGL上下文。GLContextEGL类的成员函数MakeCurrent通过调用EGL函数eglMakeCurrent即可将context_描述的OpenGL上下文设置为GPU线程当前使用OpenGL上下文,以及将参数surface描述的绘图表面设置为要切换至的OpenGL上下文的绘图表面。
以上就是真实OpenGL上下文的切换过程。这个切换过程主要是通过EGL函数eglMakeCurrent。接下来我们继续分析虚拟OpenGL上下文的切换过程,即GLContextVirtual类的成员函数MakeCurrent的实现,如下所示:
bool GLContextVirtual::MakeCurrent(gfx::GLSurface* surface) {
if (decoder_.get())
return shared_context_->MakeVirtuallyCurrent(this, surface);
......
return false;
}从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,每一个虚拟OpenGL上下文都对应有一个真实OpenGL上下文。这个真实OpenGL上下文就是通过GLContextVirtual类的成员变量shared_context_指向的一个GLContextEGL对象描述的。GLContextVirtual类的成员函数MakeCurrent调用这个GLContextEGL对象的成员函数MakeVirtuallyCurrent切换虚拟OpenGL上下文。
GLContextEGL类的成员函数MakeVirtuallyCurrent是从父类GLContext继承下来的,因此接下来我们就分析GLContext类的成员函数MakeVirtuallyCurrent的实现。不过在GLContext类的成员函数MakeVirtuallyCurrent的实现之前,我们先分析虚拟OpenGL上下文的初始化过程。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,虚拟OpenGL上下文的初始化是通过调用GLContextVirtual类的成员函数Initialize实现的,如下所示:
bool GLContextVirtual::Initialize(
gfx::GLSurface* compatible_surface, gfx::GpuPreference gpu_preference) {
SetGLStateRestorer(new GLStateRestorerImpl(decoder_));
......
shared_context_->SetupForVirtualization();
......
return true;
}GLContextVirtual类的成员函数Initialize首先创建一个GLStateRestorerImpl对象,并且通过调用另外一个成员函数SetGLStateRestorer将该GLStateRestorerImpl对象保存在内部。这个GLStateRestorerImpl对象以后用来保存当前正在初始化的虚拟OpenGL上下文的状态。
GLContextVirtual类的成员变量shared_context_指向的是一个GLContextEGL对象,这个GLContextEGL对象描述当前正在初始化的虚拟OpenGL上下文对应的真实OpenGL上下文,GLContextVirtual类的成员函数Initialize接下来调用GLContextEGL类的成员函数SetupForVirtualization对该真实OpenGL上下文进行初始化,如下所示:
void GLContext::SetupForVirtualization() {
if (!virtual_gl_api_) {
virtual_gl_api_.reset(new VirtualGLApi());
virtual_gl_api_->Initialize(&g_driver_gl, this);
}
}GLContextEGL类的成员函数SetupForVirtualization主要是检查成员变量virtual_gl_api_的值是否等于NULL。如果等于NULL,那么就创建一个VirtualGLApi对象,并且保存在成员变量virtual_gl_api_中。这个VirtualGLApi对象以后负责切换虚拟OpenGL上下文。
有了上面的基础知识之后,接下来我们就分析GLContext类的成员函数MakeVirtuallyCurrent的实现,如下所示:
bool GLContext::MakeVirtuallyCurrent(
GLContext* virtual_context, GLSurface* surface) {
......
return virtual_gl_api_->MakeCurrent(virtual_context, surface);
}GLContext类的成员变量virtual_gl_api_描述的是一个VirtualGLApi对象。前面提到,这个VirtualGLApi对象负责切换虚拟OpenGL上下文。这里调用它的成员函数MakeCurrent切换虚拟OpenGL上下文。
VirtualGLApi类的成员函数MakeCurrent的实现如下所示:
bool VirtualGLApi::MakeCurrent(GLContext* virtual_context, GLSurface* surface) {
bool switched_contexts = g_current_gl_context_tls->Get() != this;
GLSurface* current_surface = GLSurface::GetCurrent();
if (switched_contexts || surface != current_surface) {
......
if (switched_contexts || !current_surface ||
!virtual_context->IsCurrent(surface)) {
if (!real_context_->MakeCurrent(surface)) {
return false;
}
}
}
......
if (switched_contexts || virtual_context != current_context_) {
......
if (virtual_context->GetGLStateRestorer()->IsInitialized()) {
virtual_context->GetGLStateRestorer()->RestoreState(
(current_context_ && !switched_contexts)
? current_context_->GetGLStateRestorer()
: NULL);
}
......
current_context_ = virtual_context;
}
......
return true;
}从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,虚拟OpenGL上下文是按组进行管理的。在同一个组中的虚拟OpenGL上下文对应的真实OpenGL上下文都是相同的。我们将一个虚拟OpenGL上下文切换为GPU线程当前使用的虚拟OpenGL上下文之前,要先将要切换的虚拟OpenGL上下文对应的真实OpenGL上下文切换为GPU线程当前使有的真实OpenGL上下文。
一个虚拟OpenGL上下文被切换为GPU线程当前使用的虚拟OpenGL上下文之后,它对应的真实OpenGL上下文内部使用的一个VirtualGLApi对象会记录在全局变量g_current_gl_context_tls中。如果记录在全局变量g_current_gl_context_tls中的VirtualGLApi对象与当前正在处理的VirtualGLApi对象不一样,本地变量switched_contexts的值就会等于true。这种情况说明要切换至的虚拟OpenGL上下文对应的真实OpenGL上下文不是GPU线程当前使用的真实OpenGL上下文,因此就需要先将该真实OpenGL上下文切换为GPU线程当前使用的真实OpenGL上下文。这个真实OpenGL上下文就保存在VirtualGLApi类的成员变量real_context_中,通过调用它的成员函数MakeCurrent,也就是前面分析过的GLContextEGL类的成员函数MakeCurrent,就可以将其设置为GPU线程当前使用的真实OpenGL上下文。
此外,当要切换至的虚拟OpenGL上下文关联的绘图表面不是GPU线程当前使用的绘图表面时,即使要切换至的虚拟OpenGL上下文对应的真实OpenGL上下文就是GPU线程当前使有的真实OpenGL上下文,也需要调用该真实OpenGL上下文的成员函数MakeCurrent重新设置GPU线程当前使用的绘图表面。GPU线程当前使用的绘图表面可以通过调用GLSurface类的静态成员函数GetCurrent获得,而要设置的绘图表面由参数surface指定。
对切换至的虚拟OpenGL上下文对应的真实OpenGL上下文进行必要的处理后,VirtualGLApi类的成员函数MakeCurrent再检查GPU线程当前使用的虚拟OpenGL上下文是否发生变化。GPU线程当前使用的虚拟OpenGL上下文记录在VirtualGLApi类的成员变量current_context_中,参数virtual_context描述的是要切换至的虚拟OpenGL上下文。当这两者的值不相等时,就说明GPU线程当前使用的虚拟OpenGL上下文发生了变化。在这种情况下,以及在GPU线程当前使用的真实OpenGL上下文发生变化的情况下,都需要执行切换虚拟OpenGL上下文的操作。
切换虚拟OpenGL上下文实际上就是将要切换至的虚拟OpenGL上下文的状态设置为GPU线程的当前状态。前面提到,虚拟OpenGL上下文的状态记录在一个GLStateRestorerImpl对象。VirtualGLApi类的成员函数MakeCurrent通过调用参数virtual_context描述的一个GLContextVirtual对象的成员函数GetGLStateRestorer就可以获得要切换至的虚拟OpenGL上下文的状态,即一个GLStateRestorerImpl对象。有了这个GLStateRestorerImpl对象之后,就可以调用它的成员函数RestoreState将其描述的状态设置为GPU线程的当前状态了。
GLStateRestorerImpl类的成员函数RestoreState的实现如下所示:
void GLStateRestorerImpl::RestoreState(const gfx::GLStateRestorer* prev_state) {
DCHECK(decoder_.get());
const GLStateRestorerImpl* restorer_impl =
static_cast(prev_state);
decoder_->RestoreState(
restorer_impl ? restorer_impl->GetContextState() : NULL);
} 参数prev_state描述的是切换前的GPU线程的状态,通过调用它的成员函数GetContextState可以获得这个状态。有了这个前状态之后,GLStateRestorerImpl类的成员函数RestoreState就可以调用成员变量decoder_描述的一个GLES2CmdDecoderImpl对象的成员函数RestoreState切换GPU线程的当前状态。
GLES2CmdDecoderImpl类的成员函数RestoreState的实现如下所示:
void GLES2DecoderImpl::RestoreState(const ContextState* prev_state) const {
......
RestoreFramebufferBindings();
state_.RestoreState(prev_state);
}如果要切换至的虚拟OpenGL上下文以前调用过OpenGL函数glBindFramebuffer绑定过FBO,那么GLES2CmdDecoderImpl类的成员函数RestoreState就会调用另外一个成员函数RestoreFramebufferBindings重新恢复绑定它们。
GLES2CmdDecoderImpl类的成员变量state_描述的是一个ContextState对象,GLES2CmdDecoderImpl类的成员函数RestoreState接下来调用这个ContextState对象的成员函数RestoreState切换GPU线程的当前状态,如下所示:
void ContextState::RestoreState(const ContextState* prev_state) const {
RestoreAllTextureUnitBindings(prev_state);
RestoreVertexAttribs();
RestoreBufferBindings();
RestoreRenderbufferBindings();
RestoreProgramBindings();
RestoreGlobalState(prev_state);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/service/context_state.cc中。
从ContextState类的成员函数RestoreState的实现可以知道,需要切换的GPU线程状态包括:
1. 纹理(Texture)——通过成员函数RestoreAllTextureUnitBindings切换。
2. 顶点数组(VAO)——通过成员函数RestoreVertexAttribs切换。
3. 顶点缓冲区(VBO、IBO)——通过成员函数RestoreBufferBindings切换。
4. 渲染缓冲区(RBO)——通过成员函数RestoreRenderbufferBindings切换。
5. 着色器(Shader)——通过成员函数RestoreProgramBindings切换。
6. 其他的全局状态(GL_BLEND、GL_DITHER等ENABLE/DISABLE开关以及Clear Color、Blend Color等参数设置)——通过成员函数RestoreGlobalState切换。
上述状态是与真实OpenGL上下文绑定在一起的,并且由GPU驱动进行维护。 在使用真实OpenGL上下文的情况下,上述状态随着真实OpenGL上下文的切换而得以切换,也就是上述状态由GPU驱动自动进行切换。虚拟OpenGL上下文是GPU的使用者定义的概念,GPU驱动并不认识,因此在使用虚拟OpenGL上下文的情况下,GPU的使用者必须要自己去维护它们的状态,实现方式就是自己去调用相关的OpenGL函数去切换相应的状态。
接下来我们就以纹理状态的切换为例,说明在使用虚拟OpenGL上下文的情况下,GPU线程状态的切换过程,如下所示:
void ContextState::RestoreAllTextureUnitBindings(
const ContextState* prev_state) const {
// Restore Texture state.
for (size_t ii = 0; ii < texture_units.size(); ++ii) {
RestoreTextureUnitBindings(ii, prev_state);
}
RestoreActiveTexture();
}ContextState类的成员变量texture_units保存了一个虚拟OpenGL上下文可以使用的所有纹理单元,每一个纹理单元都通过调用成员函数RestoreTextureUnitBindings进行状态切换,如下所示:
void ContextState::RestoreTextureUnitBindings(
GLuint unit, const ContextState* prev_state) const {
DCHECK_LT(unit, texture_units.size());
const TextureUnit& texture_unit = texture_units[unit];
GLuint service_id_2d = Get2dServiceId(texture_unit);
GLuint service_id_cube = GetCubeServiceId(texture_unit);
GLuint service_id_oes = GetOesServiceId(texture_unit);
GLuint service_id_arb = GetArbServiceId(texture_unit);
bool bind_texture_2d = true;
bool bind_texture_cube = true;
bool bind_texture_oes = feature_info_->feature_flags().oes_egl_image_external;
bool bind_texture_arb = feature_info_->feature_flags().arb_texture_rectangle;
if (prev_state) {
const TextureUnit& prev_unit = prev_state->texture_units[unit];
bind_texture_2d = service_id_2d != Get2dServiceId(prev_unit);
bind_texture_cube = service_id_cube != GetCubeServiceId(prev_unit);
bind_texture_oes =
bind_texture_oes && service_id_oes != GetOesServiceId(prev_unit);
bind_texture_arb =
bind_texture_arb && service_id_arb != GetArbServiceId(prev_unit);
}
// Early-out if nothing has changed from the previous state.
if (!bind_texture_2d && !bind_texture_cube
&& !bind_texture_oes && !bind_texture_arb) {
return;
}
glActiveTexture(GL_TEXTURE0 + unit);
if (bind_texture_2d) {
glBindTexture(GL_TEXTURE_2D, service_id_2d);
}
if (bind_texture_cube) {
glBindTexture(GL_TEXTURE_CUBE_MAP, service_id_cube);
}
if (bind_texture_oes) {
glBindTexture(GL_TEXTURE_EXTERNAL_OES, service_id_oes);
}
if (bind_texture_arb) {
glBindTexture(GL_TEXTURE_RECTANGLE_ARB, service_id_arb);
}
}一个纹理单元对应有GL_TEXTURE_2D、GL_TEXTURE_CUBE_MAP、GL_TEXTURE_EXTERNAL_OES和GL_TEXTURE_RECTANGLE_ARB四个纹理目标,因此切换一个纹理单元的状态,所要做的事情有两件:
1. 调用OpenGL函数glActiveTexture选择要切换状态的纹理单元。
2. 调用OpenGL函数glBindTexture恢复选择的纹理单元的上述四个纹理目标。
每一个纹理目标都通过一个纹理ID描述,这些纹理ID保存在一个TextureUnit对象中,这个TextureUnit对象可以通过参数unit获得。
对一个纹理单元来说,它有可能在切换前的虚拟OpenGL上下文和切换后的虚拟OpenGL上下文中使用了相同的纹理目标。在这种情况下,实际上是不需要调用OpenGL函数glBindTexture来恢复它的纹理目标的,这样可以降低纹理单元状态切换带来的开销。因此,ContextState类的成员函数RestoreTextureUnitBindings在恢复一个纹理单元的某一个纹理目标之前,首先判断这个纹理目标在前后两个虚拟OpenGL上下文中是否发生了变化。只有发生了变化的纹理目标,才会调用OpenGL函数glBindTexture进行恢复。
关于纹理单元和纹理目标的关系,以及它们的状态切换机制,可以参考这篇文章:Differences and relationship between glActiveTexture and glBindTexture。
回到ContextState类的RestoreAllTextureUnitBindings中,切换了每一个纹理单元的纹理目标之后,接下来它调用成员函数RestoreActiveTexture设置切换后的虚拟OpenGL上下文当前激活的纹理单元,如下所示:
void ContextState::RestoreActiveTexture() const {
glActiveTexture(GL_TEXTURE0 + active_texture_unit);
}一个虚拟OpenGL上下文当前激活的纹理单元记录在成员变量active_texture_unit中,通过调用OpenGL函数glActiveTexture即可激活它。
这样,我们就分析完成了OpenGL上下文的切换过程,包括真实OpenGL上下文和虚拟OpenGL上下文的切换过程。回到前面分析的GpuChannel类的成员函数HandleMessage中,我们继续分析OpenGL上下文调度过程中涉及到的其它两个问题:
1. 一个OpenGL上下文在什么情况下会自行放弃度调度。
2. 一个OpenGL上下文在什么情况下会被抢占调度。
我们首先分析一个OpenGL上下文在什么情况下会自行放弃度调度。从前面分析的GpuChannel类的成员函数HandleMessage的实现可以知道,当一个OpenGL上下文自行放弃调度时,调用对应的GpuCommandBufferStub对象的成员函数IsScheduled得到的返回值等于false。
GpuCommandBufferStub类的成员函数IsScheduled的实现如下所示:
bool GpuCommandBufferStub::IsScheduled() {
return (!scheduler_.get() || scheduler_->IsScheduled());
}GpuCommandBufferStub类的成员函数IsScheduled首先判断成员变量scheduler_是否指向了一个GpuScheduler对象。如果指向了一个GpuScheduler对象,那么就调用该GpuScheduler对象的成员函数IsScheduled判断一个OpenGL上下文是否自行放弃了调度。否则的话,就是认为一个OpenGL上下文没有自行放弃调度,即GpuCommandBufferStub类的成员函数IsScheduled的返回值为true。
GpuScheduler类的成员函数IsScheduled的实现如下所示:
bool GpuScheduler::IsScheduled() {
return unscheduled_count_ == 0;
}GpuScheduler类的成员变量unscheduled_count_描述的是一个OpenGL上下文请求放弃调度的计数,当它的值不等于0的时候,就表示一个OpenGL上下文自行放弃了调度。那么GpuScheduler类的成员变量unscheduled_count_的值是什么时候被设置的呢?
GpuScheduler类的成员变量unscheduled_count_的值在构造函数中初始化为0,如下所示:
GpuScheduler::GpuScheduler(CommandBufferServiceBase* command_buffer,
AsyncAPIInterface* handler,
gles2::GLES2Decoder* decoder)
: ......,
unscheduled_count_(0),
rescheduled_count_(0),
...... {}与OpenGL上下文自行放弃调度相关的参数还包括GpuScheduler类的另外一个成员变量rescheduled_count_,它的值也是初始化为0。
我们可以通过调用GpuScheduler类的成员函数SetScheduled来设置GpuScheduler类的成员变量unscheduled_count_和rescheduled_count_的值,如下所示:
void GpuScheduler::SetScheduled(bool scheduled) {
......
if (scheduled) {
// If the scheduler was rescheduled after a timeout, ignore the subsequent
// calls to SetScheduled when they eventually arrive until they are all
// accounted for.
if (rescheduled_count_ > 0) {
--rescheduled_count_;
return;
} else {
--unscheduled_count_;
}
......
if (unscheduled_count_ == 0) {
......
if (!scheduling_changed_callback_.is_null())
scheduling_changed_callback_.Run(true);
}
} else {
++unscheduled_count_;
if (unscheduled_count_ == 1) {
......
#if defined(OS_WIN)
if (base::win::GetVersion() < base::win::VERSION_VISTA) {
// When the scheduler transitions from scheduled to unscheduled, post a
// delayed task that it will force it back into a scheduled state after
// a timeout. This should only be necessary on pre-Vista.
base::MessageLoop::current()->PostDelayedTask(
FROM_HERE,
base::Bind(&GpuScheduler::RescheduleTimeOut,
reschedule_task_factory_.GetWeakPtr()),
base::TimeDelta::FromMilliseconds(kRescheduleTimeOutDelay));
}
#endif
if (!scheduling_changed_callback_.is_null())
scheduling_changed_callback_.Run(false);
}
}
} GpuScheduler类的成员变量rescheduled_count_主要是用在Vista版本之前的Windows系统上。为了简单起见,我们首先忽略GpuScheduler类的成员函数SetScheduled对这个成员变量的处理,即假设它的值维持为初始值0。
GpuScheduler类的成员函数SetScheduled根据参数scheduled的值相应地调整成员变量unscheduled_count_的值:
1. 当参数scheduled的值等于true时,就将成员变量unscheduled_count_的值减少1。若减少后的值等于0,就说明一个OpenGL上下文从放弃调度状态进入到了请求调度状态。这时候如果成员变量scheduling_changed_callback_指向了一个Callback对象,那么就调用该Callback对象的成员函数Run,并且传递一个true参数给它。
2. 当参数scheduled的值等于false时,就将成员变量unscheduled_count_的值增加1。若增加后的值等于1,就说明一个OpenGL上下文从放弃调度状态进入到了请求调度状态。这时候如果成员变量scheduling_changed_callback_指向了一个Callback对象,那么就调用该Callback对象的成员函数Run,并且传递一个false参数给它。
关于GpuScheduler类的成员变量scheduling_changed_callback_的作用,接下来我们分析OpenGL上下文的抢占调度过程时再分析。
现在我们再考虑GpuScheduler类的成员变量rescheduled_count_。一个OpenGL上下文进入到了放弃调度状态后,以后在某个时刻应该恢复为请求调度状态。为了防止一个OpenGL上下文进入到放弃调度状态后,很长时间都没有恢复为请求调度状态,Chromium会给该OpenGL上下文设置一个恢复为请求调度状态的超时时间。当发生超时时,GpuScheduler类的成员函数RescheduleTimeOut会被调用,如下所示:
void GpuScheduler::RescheduleTimeOut() {
int new_count = unscheduled_count_ + rescheduled_count_;
rescheduled_count_ = 0;
while (unscheduled_count_)
SetScheduled(true);
rescheduled_count_ = new_count;
}GpuScheduler类的成员函数RescheduleTimeOut先将成员变量unscheduled_count_和rescheduled_count_相加后的值记录在变量new_count中,然后将成员变量rescheduled_count_的值设置为0,目的是为了后面通过不断调用前面分析过的成员函数SetScheduled将成员变量unscheduled_count_的值设置为0,从而将一个OpenGL上下文从放弃调度状态切换为请求调度状态。
最后,GpuScheduler类的成员函数RescheduleTimeOut又将前面计算出来的new_count值保存在成员变量rescheduled_count_中,这样会使得GpuScheduler类的成员函数SetScheduled在恢复请求调度状态超时后参数为true的前若干次调用,仅仅是减少成员变量rescheduled_count_的值,而不会影响成员变量unscheduled_count_的值,因为对成员变量unscheduled_count_的影响已经提前在GpuScheduler类的成员函数RescheduleTimeOut中实施过了。
上面要表达的意思就是,如果一个OpenGL上下文调用GpuScheduler类的成员函数SetScheduled进入放弃调度状态,并且在超时之前,没有再次调用GpuScheduler类的成员函数SetScheduled进入请求调度状态,那么在超时之后再调用GpuScheduler类的成员函数SetScheduled进入请求调度状态,那么该次调用不会导致该OpenGL上下文的调度状态发生变化,因为该变化已经在GpuScheduler类的成员函数RescheduleTimeOut实现过了。
现在,关于OpenGL上下文什么情况下会自行放弃调度的问题,就变成了GpuScheduler类的成员函数SetScheduled什么时候会以参数false被调用。这涉及到Chromium硬件加速渲染中的同步点(Sync Point)机制。
同步点用来在不同的OpenGL上下文中同步资源访问。例如,WebGL端将自己的UI绘制在一个纹理中,然后会将这个纹理以邮箱(Mailbox)的形式交给Browser端OpenGL上下文合成到浏览器窗口中显示。Browser端OpenGL上下文在合成WebGL端交给它的纹理之前,必须要保证这个纹理是已经绘制完成了的。实际上就是要保证两个不同OpenGL上下文的GPU命令缓冲区的命令的执行顺序,如图5所示:
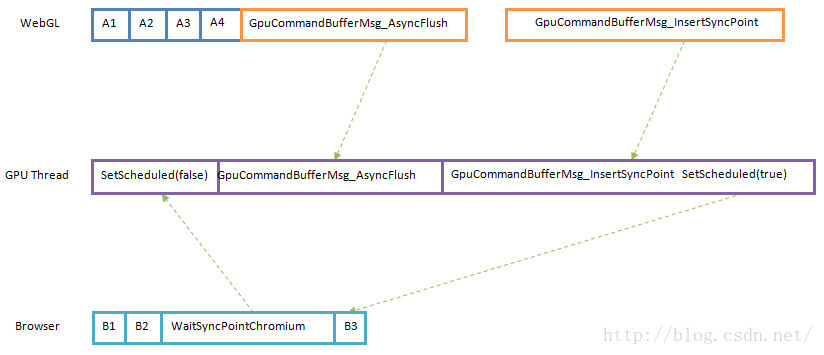
图5 Sync Point
假设WebGL端通过A1、A2、A3和A4命令将UI绘制在一个纹理上,Browser端通过B3命令合成WebGL端生成的纹理,这时候Browser端在GPU命令缓冲区中写入B3命令之前,先写入一个WaitSyncPointCHROMIUM命令。
WebGL端向GPU命令缓冲区写入A1、A2、A3和A4命令之后,先后向GPU进程中的GPU线程发送一个GpuCommandBufferMsg_AsyncFlush消息和一个GpuCommandBufferMsg_InsertSyncPoint消息。其中,GpuCommandBufferMsg_AsyncFlush消息用来通知GPU线程执行A1、A2、A3和A4命令,GpuCommandBufferMsg_InsertSyncPoint消息用来插入一个Sync Point。这两个消息被GPU进程中的GPU线程依次处理,这样可以保证当GpuCommandBufferMsg_InsertSyncPoint消息被处理时,WebGL端已经将UI绘制好在纹理上了。
假设GPU线程在处理Browser端的GPU命令缓冲区的B3命令时,WebGL端发送给GPU线程的GpuCommandBufferMsg_AsyncFlush消息还没有被处理,这时候Browser端OpenGL上下文就会自动放弃调度。等到WebGL端发送给GPU线程的GpuCommandBufferMsg_InsertSyncPoint消息被处理之后,Browser端OpenGL上下文就会重新请求调度,从而保证它的B3命令执行时,可以访问到WebGL端已经绘制好了UI的纹理。
接下来,我们就分析WebGL端向GPU线程请求插入Sync Point和Browser端等待WebGL端插入的Sync Point的过程。
WebGL端是通过调用GLES2Implementation类的成员函数InsertSyncPointCHROMIUM向GPU线程请求插入Sync Point的,如下所示:
GLuint GLES2Implementation::InsertSyncPointCHROMIUM() {
......
helper_->CommandBufferHelper::Flush();
return gpu_control_->InsertSyncPoint();
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/gles2_implementation.cc中。
GLES2Implementation类的成员函数InsertSyncPointCHROMIUM首先调用成员变量helper_描述的一个GLES2CmdHelper对象从父类CommandBufferHelper继承下来的成员函数Flush请求GPU进程执行其GPU命令缓冲区的命令,相当于就是执行图5所示的A1~A4命令。
在前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文中,我们已经分析过CommandBufferHelper类的成员函数Flush的实现了,它主要就是向GPU进程发送一个GpuCommandBufferMsg_AsyncFlush消息。这个GpuCommandBufferMsg_AsyncFlush消息被封装一个Task,发送到GPU线程的消息队列去等待处理,最终被GpuChannel类的成员函数HandleMessage分发给GpuCommandBufferStub类的成员函数OnMessageReceived处理,后者又将该消息分发给另外一个成员函数OnAsyncFlush进一步处理。
GLES2Implementation类的成员函数InsertSyncPointCHROMIUM接下来又调用成员变量gpu_control_指向的一个CommandBufferProxyImpl对象的成员函数InsertSyncPoint请求GPU进程在当前正在处理的OpenGL上下文中插入一个Sync Point。
CommandBufferProxyImpl类的成员函数InsertSyncPoint的实现如下所示:
uint32 CommandBufferProxyImpl::InsertSyncPoint() {
......
uint32 sync_point = 0;
Send(new GpuCommandBufferMsg_InsertSyncPoint(route_id_, &sync_point));
return sync_point;
}CommandBufferProxyImpl类的成员函数InsertSyncPoint向GPU进程发送一个类型为GpuCommandBufferMsg_InsertSyncPoint的GPU消息。GPU进程在处理这个GPU消息的时候,会生成一个类型为uint32的Sync Point,并且将该Sync Point返回给调用者。
从前面分析的GpuChannel类的成员函数Init可以知道,发送给GPU进程的GPU消息首先由注册在GPU通道中的一个类型为GpuChannelMessageFilter的Message Filter处理,也就是由GpuChannelMessageFilter类的成员函数OnMessageReceived先处理。
GpuChannelMessageFilter类的成员函数OnMessageReceived会处理类型为GpuCommandBufferMsg_InsertSyncPoint的GPU消息,如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
virtual bool OnMessageReceived(const IPC::Message& message) OVERRIDE {
......
bool handled = false;
......
if (message.type() == GpuCommandBufferMsg_InsertSyncPoint::ID) {
uint32 sync_point = sync_point_manager_->GenerateSyncPoint();
IPC::Message* reply = IPC::SyncMessage::GenerateReply(&message);
GpuCommandBufferMsg_InsertSyncPoint::WriteReplyParams(reply, sync_point);
Send(reply);
message_loop_->PostTask(FROM_HERE, base::Bind(
&GpuChannelMessageFilter::InsertSyncPointOnMainThread,
gpu_channel_,
sync_point_manager_,
message.routing_id(),
sync_point));
handled = true;
}
return handled;
}
......
};GpuChannelMessageFilter类的成员函数OnMessageReceived首先调用成员变量sync_point_manager_描述的一个SyncPointManager对象的成员函数GenerateSyncPoint生成一个Sync Point,如下所示:
uint32 SyncPointManager::GenerateSyncPoint() {
base::AutoLock lock(lock_);
uint32 sync_point = next_sync_point_++;
// When an integer overflow occurs, don't return 0.
if (!sync_point)
sync_point = next_sync_point_++;
// Note: wrapping would take days for a buggy/compromized renderer that would
// insert sync points in a loop, but if that were to happen, better explicitly
// crash the GPU process than risk worse.
// For normal operation (at most a few per frame), it would take ~a year to
// wrap.
CHECK(sync_point_map_.find(sync_point) == sync_point_map_.end());
sync_point_map_.insert(std::make_pair(sync_point, ClosureList()));
return sync_point;
}SyncPointManager类的成员函数GenerateSyncPoint主要就是通过递增成员变量next_sync_point_的值来生成Sync Point,并且在将生成的Sync Point返回给调用者之前,将其保存在成员变量sync_point_map_描述的一个Hash Map中。这个Hash Map以Sync Point为Key,保存了一个Closure List。后面我们会看到这个Closure List的作用。
回到GpuChannelMessageFilter类的成员函数OnMessageReceived中,调用SyncPointManager类的成员函数GenerateSyncPoint生成了一个Sync Point之后,就向发送GpuCommandBufferMsg_InsertSyncPoint消息的Client端回复一个消息,该回复消息封装了前面生成的Sync Point。
GpuChannelMessageFilter类的成员变量message_loop_描述的是GPU线程的消息循环,GpuChannelMessageFilter类的成员函数OnMessageReceived最后向该消息循环使用的消息队列发送一个Task,该Task绑定了GpuChannelMessageFilter类的成员函数InsertSyncPointOnMainThread,负责处理前面接收到的GpuCommandBufferMsg_InsertSyncPoint消息。这相当于是GPU线程的消息队列多了一个GpuCommandBufferMsg_InsertSyncPoint消息需要处理。
根据前面的分析,这里有一点需要注意,GPU线程在接收到GpuCommandBufferMsg_InsertSyncPoint消息之前,接收到了一个GpuCommandBufferMsg_AsyncFlush消息。该消息也被封装成一个Task发送到了GPU线程的消息队列中。这意味着GPU线程先处理GpuCommandBufferMsg_AsyncFlush消息,再处理GpuCommandBufferMsg_InsertSyncPoint消息。因此就可以保证,当GpuChannelMessageFilter类的成员函数InsertSyncPointOnMainThread被调用时,在向当前正在处理的OpenGL上下文插入的Sync Point之前提交的GPU命令均已处理完毕。在我们这个情景中,就相当于是WebGL端已经将UI绘制好在一个纹理中了,即图5所示的A1~A4命令已处理完毕。
GpuChannelMessageFilter类的成员函数InsertSyncPointOnMainThread的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
static void InsertSyncPointOnMainThread(
base::WeakPtr gpu_channel,
scoped_refptr manager,
int32 routing_id,
uint32 sync_point) {
......
if (gpu_channel) {
GpuCommandBufferStub* stub = gpu_channel->LookupCommandBuffer(routing_id);
if (stub) {
stub->AddSyncPoint(sync_point);
GpuCommandBufferMsg_RetireSyncPoint message(routing_id, sync_point);
gpu_channel->OnMessageReceived(message);
return;
}
......
}
......
}
......
}; 参数gpu_channel描述的是接收到GpuCommandBufferMsg_InsertSyncPoint消息的GPU通道。参数routing_id描述的是负责处理GpuCommandBufferMsg_InsertSyncPoint消息的一个GpuCommandBufferStub对象的Routing ID。根据这个Routing ID,就可以在参数gpu_channel描述的GPU通道中找到对应的GpuCommandBufferStub对象。这个GpuCommandBufferStub对象描述的就是发送GpuCommandBufferMsg_InsertSyncPoint消息的Client端的OpenGL上下文。
找到了目标GpuCommandBufferStub对象之后,GpuChannelMessageFilter类的成员函数InsertSyncPointOnMainThread调用它的成员函数AddSyncPoint,以便将参数sync_point描述的Sync Point交给它处理。
GpuCommandBufferStub类的成员函数AddSyncPoint的实现如下所示:
void GpuCommandBufferStub::AddSyncPoint(uint32 sync_point) {
sync_points_.push_back(sync_point);
} GpuCommandBufferStub类的成员函数AddSyncPoint将参数sync_point描述的Sync Point保存在成员变量sync_points_描述的一个std::deque中。
回到GpuChannelMessageFilter类的成员函数InsertSyncPointOnMainThread,它将参数sync_point描述的Sync Point保存在目标GpuCommandBufferStub对象的成员变量sync_points_描述的一个std::deque中之后,再通过参数gpu_channel描述的GpuChannel对象的成员函数OnMessageReceived向目标GpuCommandBufferStub对象分发一个GpuCommandBufferMsg_RetireSyncPoint消息。
GpuCommandBufferMsg_RetireSyncPoint消息由GpuCommandBufferStub类的成员函数OnMessageReceived接收,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER(GpuCommandBufferMsg_RetireSyncPoint,
OnRetireSyncPoint)
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
......
return handled;
}从这里可以看到,GpuCommandBufferStub类的成员函数OnMessageReceived将GpuCommandBufferMsg_RetireSyncPoint消息分发给成员函数OnRetireSyncPoint处理。
GpuCommandBufferStub类的成员函数OnRetireSyncPoint的实现如下所示:
void GpuCommandBufferStub::OnRetireSyncPoint(uint32 sync_point) {
DCHECK(!sync_points_.empty() && sync_points_.front() == sync_point);
sync_points_.pop_front();
if (context_group_->mailbox_manager()->UsesSync() && MakeCurrent())
context_group_->mailbox_manager()->PushTextureUpdates();
GpuChannelManager* manager = channel_->gpu_channel_manager();
manager->sync_point_manager()->RetireSyncPoint(sync_point);
}从前面的分析可以知道,GpuCommandBufferStub类的成员变量sync_points_保存了在当前正在处理的OpenGL上下文中插入的Sync Point,并且这些Sync Point都是还没有被Retired的。一个Sync Point被Retired,是指该Sync Point所插入的OpenGL上下文,在被插入Sync Point之前的所有GPU命令都已经被处理。
GpuCommandBufferStub类的成员函数OnRetireSyncPoint所做的事情就是Retire参数sync_point描述的Sync Point,注意,插入到一个OpenGL上下文中的Sync Point,是按照插入顺序依次被Retired的。
GpuCommandBufferStub类的成员函数OnRetireSyncPoint是如何Retire一个Sync Point的呢?它首先获得一个GpuChannelManager对象。从前面Chromium的GPU进程启动过程分析一文可以知道,这个GpuChannelManager对象在GPU进程中是一个单例。获得了GPU进程中的GpuChannelManager单例对象之后,再通过它获得一个SyncPointManager对象。这个SyncPointManager对象与前面分析的GpuChannelMessageFilter类的成员变量sync_point_manager_指向的SyncPointManager对象是相同的。这意味着这个SyncPointManager对象在GPU进程中也是一个单例。获得了GPU进程中的SyncPointManager单例对象之后,GpuCommandBufferStub类的成员函数OnRetireSyncPoint就调用它的成员函数RetireSyncPoint将参数sync_point描述的Sync Point设置为被Retired的。
SyncPointManager类的成员函数RetireSyncPoint的实现如下所示:
void SyncPointManager::RetireSyncPoint(uint32 sync_point) {
......
ClosureList list;
{
base::AutoLock lock(lock_);
SyncPointMap::iterator it = sync_point_map_.find(sync_point);
......
list.swap(it->second);
sync_point_map_.erase(it);
}
for (ClosureList::iterator i = list.begin(); i != list.end(); ++i)
i->Run();
}保存在SyncPointManager类的成员变量sync_point_map_描述的一个Hash Map中的Sync Point都是还没有被Retired的。一旦一个Sync Point被Retired,它就需要从该Hash Map移除。在移除的时候,如果这个Sync Point关联的Closure List不为空,那么保存在该Closure List中的每一个Closure都会被执行,也就是它们的成员函数Run会被执行。后面我们就会看到,如何将一个Closure添加到一个Sync Point关联的Closure List中去。
以上就是SyncPointManager类的成员函数RetireSyncPoint的执行逻辑。回到GpuCommandBufferStub类的成员函数OnRetireSyncPoint中,我们注意以下两行代码:
if (context_group_->mailbox_manager()->UsesSync() && MakeCurrent())
context_group_->mailbox_manager()->PushTextureUpdates();将一个纹理从一个OpenGL上下文传递到另一个OpenGL上下文,需要保证另一个OpenGL上下文能够访问该纹理。如果这两个OpenGL上下文是在同一个共享组的,那么很显然能保证被传递的纹理能够被另一个OpenGL上下文访问。如果这两个OpenGL上下文不是在同一个共享组的,那么另一个OpenGL上下文就不能访问传递给它的纹理了。这时候怎么办呢?回忆前面Chromium硬件加速渲染的GPU数据上传机制分析一文,Chromium在执行异步纹理上传时,是通过EGLImageKHR技术实现在两个不是在同一个共享组的OpenGL上下文之间共享同一个纹理的。Chromium的Mailbox机制也是通过GLImageKHR技术实现在两个不是在同一个共享组的OpenGL上下文之间共享同一个纹理的。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,Chromium中的所有OpenGL上下文都是在同一个共享组的,因此在实现Mailbox机制时,就不需要通过EGLImageKHR技术来实现不同OpenGL上下文之间的纹理共享。但是在基于Chromium实现的WebView,它里面创建的OpenGL上下文不是在同一个共享组的,因此在实现Mailbox机制时,就需要通过EGLImageKHR技术来实现不同OpenGL上下文之间的纹理共享。
当需要通过EGLImageKHR技术来实现不同OpenGL上下文之间的纹理共享时,调用上述提到的MailboxManager对象的成员函数UsesSync时,得到的返回值就为true。这时候需要将当前正在处理的OpenGL上下文设置为GPU线程当前使用的OpenGL上下文,以及将正在传递的纹理封装成一个EGLImageKHR对象。这是通过调用上述提到的MailboxManager对象的成员函数PushTexturesUpdates实现的。将一个纹理封装成一个EGLImageKHR对象的过程,可以参考前面Chromium硬件加速渲染的GPU数据上传机制分析一文,这里就不进行具体分析了。
以上就是在一个OpenGL上下文中插入Sync Point的过程。在一个OpenGL上下文中插入的Sync Point,会传递给另外一个OpenGL上下文。一个OpenGL上下文获得了一个Sync Point之后,就可以通过调用GLES2Implementation类的成员函数WaitSyncPointCHROMIUM向其GPU命令缓冲区写入一个gles2::cmds::WaitSyncPointCHROMIUM命令。当该gles2::cmds::WaitSyncPointCHROMIUM命令被执行时,如果它所封装的Sync Point还没有被Retired,那么它所属的OpenGL上下文就必须进行等待,直到它封装的Sync Point被Retired为止。等待的形式就是让OpenGL上下文自动放弃调度。接下来我们就从GLES2Implementation类的成员函数WaitSyncPointCHROMIUM开始,分析一个OpenGL上下文等待一个Sync Point被Retired的过程。
GLES2Implementation类的成员函数WaitSyncPointCHROMIUM的实现如下所示:
void GLES2Implementation::WaitSyncPointCHROMIUM(GLuint sync_point) {
......
helper_->WaitSyncPointCHROMIUM(sync_point);
CheckGLError();
}GLES2Implementation类的成员函数WaitSyncPointCHROMIUM调用成员变量helper_描述的一个GLES2CmdHelper对象的成员函数WaitSyncPointCHROMIUM向当前正在处理的OpenGL上下文的GPU命令缓冲区写入一个gles2::cmds::WaitSyncPointCHROMIUM命令。
从前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文可以知道,GPU命令缓冲区中的gles2::cmds::WaitSyncPointCHROMIUM命令将会被GLES2DecoderImpl类的成员函数HandleWaitSyncPointCHROMIUM进行处理,处理过程如下所示:
error::Error GLES2DecoderImpl::HandleWaitSyncPointCHROMIUM(
uint32 immediate_data_size, const cmds::WaitSyncPointCHROMIUM& c) {
group_->mailbox_manager()->PullTextureUpdates();
if (wait_sync_point_callback_.is_null())
return error::kNoError;
return wait_sync_point_callback_.Run(c.sync_point) ?
error::kNoError : error::kDeferCommandUntilLater;
}GLES2DecoderImpl类的成员函数HandleWaitSyncPointCHROMIUM首先获得成员变量group_描述的资源共享组关联的一个MailboxManager对象,然后调用这个MailboxManager对象的成员函数PullTexturesUpdates,目的是将那些从其它OpenGL上下文传递过来的纹理实现在当前正在处理的OpenGL上下文中共享。
MailboxManager类的成员函数PullTexturesUpdates所做的事情与前面提到的它的另外一个成员函数PushTexturesUpdates刚好相反,它根据后者创建的EGLImageKHR对象在当前正在处理的OpenGL上下文中创建一个纹理,从而实现纹理共享。
GLES2DecoderImpl类的成员函数HandleWaitSyncPointCHROMIUM接下来检查成员变量wait_sync_point_callback_是否指向了一个Callback对象。如果指向了一个Callback对象,那么就调用它的成员函数Run。
GLES2DecoderImpl类的成员变量wait_sync_point_callback_指向的Callback对象是什么呢?从前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文可以知道,WebGL端、Render端和Browser端在创建OpenGL上下文的过程中,会向GPU进程发送一个类型为GpuCommandBufferMsg_Initialize的IPC消息。这个IPC消息由GpuCommandBufferStub类的成员函数OnInitialize进行处理。
GpuCommandBufferStub类的成员函数OnInitialize在处理类型为GpuCommandBufferMsg_Initialize的IPC消息时,会创建一个GLES2DecoderImpl对象,并且调用这个GLES2DecoderImpl对象的成员函数SetWaitSyncPointCallback设置它的成员变量wait_sync_point_callback_,如下所示:
void GpuCommandBufferStub::OnInitialize(
base::SharedMemoryHandle shared_state_handle,
IPC::Message* reply_message) {
......
decoder_.reset(::gpu::gles2::GLES2Decoder::Create(context_group_.get()));
......
decoder_->SetWaitSyncPointCallback(
base::Bind(&GpuCommandBufferStub::OnWaitSyncPoint,
base::Unretained(this)));
......
}GLES2DecoderImpl对象的成员函数SetWaitSyncPointCallback的实现如下所示:
void GLES2DecoderImpl::SetWaitSyncPointCallback(
const WaitSyncPointCallback& callback) {
wait_sync_point_callback_ = callback;
}这意味着GLES2DecoderImpl对象的成员变量wait_sync_point_callback_指向的Callback对象绑定的函数是GpuCommandBufferStub类的成员函数OnWaitSyncPoint,因此GLES2DecoderImpl类的成员函数HandleWaitSyncPointCHROMIUM在处理gles2::cmds::WaitSyncPointCHROMIUM命令时,会调用到GpuCommandBufferStub类的成员函数OnWaitSyncPoint。
GpuCommandBufferStub类的成员函数OnWaitSyncPoint的实现如下所示:
bool GpuCommandBufferStub::OnWaitSyncPoint(uint32 sync_point) {
......
GpuChannelManager* manager = channel_->gpu_channel_manager();
if (manager->sync_point_manager()->IsSyncPointRetired(sync_point))
return true;
......
scheduler_->SetScheduled(false);
......
manager->sync_point_manager()->AddSyncPointCallback(
sync_point,
base::Bind(&GpuCommandBufferStub::OnSyncPointRetired,
this->AsWeakPtr()));
return scheduler_->IsScheduled();
}根据前面的分析,GpuCommandBufferStub类的成员函数OnWaitSyncPoint所要做的事情就是让当前正在处理的OpenGL上下文等待参数sync_point描述的Sync Point被Retired。因此,GpuCommandBufferStub类的成员函数OnWaitSyncPoint首先获得GPU进程中的一个SyncPointManager单例对象,并且调用这个SyncPointManager单例对象的成员函数IsSyncPointRetired判断参数sync_point描述的Sync Point是否已经被Retired,如果已经被Retired,那么当前正在处理的OpenGL上下文就不用等待了,也就是不用自动放弃调度了。
SyncPointManager类的成员函数IsSyncPointRetired的实现如下所示:
bool SyncPointManager::IsSyncPointRetired(uint32 sync_point) {
......
{
base::AutoLock lock(lock_);
SyncPointMap::iterator it = sync_point_map_.find(sync_point);
return it == sync_point_map_.end();
}
}当参数sync_point描述的Sync Point不在成员变量sync_point_map_描述的一个Hash Map时,SyncPointManager类的成员函数IsSyncPointRetired就认为它已经被Retired了。
回到GpuCommandBufferStub类的成员函数OnWaitSyncPoint中,如果参数sync_point描述的Sync Point还没有被Retired,那么它就会调用成员变量scheduler_描述的一个GpuScheduler对象的成员函数SetScheduled将当前正在处理的OpenGL上下文设置为自动放弃调度状态。从前面的分析可以知道,当一个OpenGL上下文自动放弃调度时,它就不能够处理Client端发送过来的GPU消息。
GpuCommandBufferStub类的成员函数OnWaitSyncPoint最后还会调用前面获得的SyncPointManager单例对象的成员函数AddSyncPointCallback为参数sync_point描述的Sync Point增加一个Callback对象,该Callback对象绑定的函数为GpuCommandBufferStub类的成员函数OnSyncPointRetired。
SyncPointManager类的成员函数AddSyncPointCallback的实现如下所示:
void SyncPointManager::AddSyncPointCallback(uint32 sync_point,
const base::Closure& callback) {
......
{
base::AutoLock lock(lock_);
SyncPointMap::iterator it = sync_point_map_.find(sync_point);
if (it != sync_point_map_.end()) {
it->second.push_back(callback);
return;
}
}
callback.Run();
} SyncPointManager类的成员函数AddSyncPointCallback首先根据参数sync_point在成员变量sync_point_map_描述的一个Hash Map中查找一个对应的Sync Point。如果存在,那么就将参数callback描述的Closure对象保存在与该Sync Point关联的一个Closure List中。否则的话,就直接调用参数callback描述的Closure对象的成员函数Run,表示参数参数sync_point描述的Sync Point已经被Retired了。
假设这时候参数sync_point描述的Sync Point还没有被Retired,那么根据前面分析的SyncPointManager类的成员函数RetireSyncPoint,当该Sync Point被Retired时,保存在与它关联的Closure List中的Closure对象,就会被执行,也就是会调用GpuCommandBufferStub类的成员函数OnSyncPointRetired。
GpuCommandBufferStub类的成员函数OnSyncPointRetired的实现如下所示:
void GpuCommandBufferStub::OnSyncPointRetired() {
......
scheduler_->SetScheduled(true);
}GpuCommandBufferStub类的成员函数OnSyncPointRetired所做的事情就是将当前正在处理的OpenGL上下文设置为请求调度状态,使得它可以处理Client端发送过来的GPU消息。
这样,我们就分析完成一个OpenGL上下文自行放弃度调度以及重新请求调度的过程。接下来我们继续分析OpenGL上下文被抢占调度的过程,就是Render端OpenGL上下文被
Browser端OpenGL上下文抢占调度的过程。
我们从Render端OpenGL上下文的绘图表面的创建过程开始分析。从前面Chromium硬件加速渲染的OpenGL上下文绘图表面创建过程分析一文可以知道,Render端OpenGL上下文的绘图表面句柄是通过调用RenderWidgetHostViewAndroid类的成员函数GetCompositingSurface创建的,如下所示:
gfx::GLSurfaceHandle RenderWidgetHostViewAndroid::GetCompositingSurface() {
gfx::GLSurfaceHandle handle =
gfx::GLSurfaceHandle(gfx::kNullPluginWindow, gfx::NATIVE_TRANSPORT);
if (CompositorImpl::IsInitialized()) {
handle.parent_client_id =
ImageTransportFactoryAndroid::GetInstance()->GetChannelID();
}
return handle;
}这个函数定义在文件external/chromium_org/content/browser/renderer_host/render_widget_host_view_android.cc中。
RenderWidgetHostViewAndroid类的成员函数GetCompositingSurface返回的绘图表面句柄用一个gfx::GLSurfaceHandle对象描述,这个gfx::GLSurfaceHandle对象的成员变量parent_client_id被设置为Browser进程中的一个ImageTransportFactoryAndroid单例对象的成员函数GetChannelID的返回值。
ImageTransportFactoryAndroid类的成员函数GetChannelID的实现如下所示:
class CmdBufferImageTransportFactory : public ImageTransportFactoryAndroid {
public:
......
virtual uint32 GetChannelID() OVERRIDE {
return BrowserGpuChannelHostFactory::instance()->GetGpuChannelId();
}
......
};ImageTransportFactoryAndroid类的成员函数GetChannelID通过调用Browser进程中的一个BrowserGpuChannelHostFactory单例对象的成员函数GetGpuChannelId的获得一个GPU通道ID,然后将这个ID返回给调用者。
BrowserGpuChannelHostFactory类的成员函数GetGpuChannelId的实现如下所示:
class CONTENT_EXPORT BrowserGpuChannelHostFactory
: public GpuChannelHostFactory,
public GpuMemoryBufferFactoryHost {
public:
......
int GetGpuChannelId() { return gpu_client_id_; }
......
private:
......
const int gpu_client_id_;
......
};BrowserGpuChannelHostFactory类的成员函数GetGpuChannelId返回的是成员变量gpu_client_id_的值。从前面Chromium的GPU进程启动过程分析一文可以知道,BrowserGpuChannelHostFactory类的成员变量gpu_client_id_描述的是Browser进程与GPU进程之间的GPU通道的ID。这也意味着用来描述Render端OpenGL上下文的绘图表面句柄的gfx::GLSurfaceHandle对象的成员变量parent_client_id指向的是Browser进程与GPU进程之间的GPU通道的ID。
从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文可以知道,前面通过调用RenderWidgetHostViewAndroid类的成员函数GetCompositingSurface创建的gfx::GLSurfaceHandle对象将会传递给GPU进程,用来创建Render端OpenGL上下文的绘图表面,如下所示:
scoped_refptr ImageTransportSurface::CreateNativeSurface(
GpuChannelManager* manager,
GpuCommandBufferStub* stub,
const gfx::GLSurfaceHandle& handle) {
if (handle.transport_type == gfx::NATIVE_TRANSPORT) {
return scoped_refptr(
new ImageTransportSurfaceAndroid(manager,
stub,
manager->GetDefaultOffscreenSurface(),
handle.parent_client_id));
}
......
} 这个函数定义在文件external/chromium_org/content/common/gpu/image_transport_surface_android.cc中。
参数handle描述的gfx::GLSurfaceHandle对象即为前面调用RenderWidgetHostViewAndroid类的成员函数GetCompositingSurface创建的gfx::GLSurfaceHandle对象,它的成员变量transport_type的值等于gfx::NATIVE_TRANSPORT,因此ImageTransportSurface类的成员函数CreateNativeSurface创建一个ImageTransportSurfaceAndroid对象来描述Render端OpenGL上下文的绘图表面。
在调用ImageTransportSurfaceAndroid类的构造函数创建ImageTransportSurfaceAndroid对象的时候,第三个参数指定为参数handle描述的gfx::GLSurfaceHandle对象的成员变量parent_client_id。这个参数将会保存在ImageTransportSurfaceAndroid类的成员变量parent_client_id_中,如下所示:
ImageTransportSurfaceAndroid::ImageTransportSurfaceAndroid(
GpuChannelManager* manager,
GpuCommandBufferStub* stub,
gfx::GLSurface* surface,
uint32 parent_client_id)
: PassThroughImageTransportSurface(manager, stub, surface),
parent_client_id_(parent_client_id) {}从前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文还可以知道,通过ImageTransportSurface类的成员函数CreateNativeSurface创建出来的ImageTransportSurfaceAndroid对象接下来会被始化,这是通过调用它的成员函数Initialize进行的,如下所示:
bool ImageTransportSurfaceAndroid::Initialize() {
......
GpuChannel* parent_channel =
GetHelper()->manager()->LookupChannel(parent_client_id_);
if (parent_channel) {
const CommandLine* command_line = CommandLine::ForCurrentProcess();
if (command_line->HasSwitch(switches::kUIPrioritizeInGpuProcess))
GetHelper()->SetPreemptByFlag(parent_channel->GetPreemptionFlag());
}
return true;
}ImageTransportSurfaceAndroid类的成员函数GetHelper返回的是一个ImageTransportHelper对象,调用这个ImageTransportHelper对象的成员函数manager获得的是GPU进程中的一个GpuChannelManager单例对象。有了这个GpuChannelManager单例对象之后,就可以调用它的成员函数LookupChannel获得与ImageTransportSurfaceAndroid类的成员变量parent_client_id_对应的一个GpuChannel对象。从前面的分析可以知道,这个GpuChannel对象描述的就是Browser进程与GPU进程之间建立的GPU通道。
ImageTransportSurfaceAndroid类的成员函数Initialize会检查GPU进程的启动参数是否包含有一个switches::kUIPrioritizeInGpuProcess选项。如果包含有,就意味着要优先执行Browser端OpenGL上下文的GPU命令,以便可以快速地将网页UI显示在屏幕中。这也意味着Browser端OpenGL上下文可以抢占调度。
我们假设GPU进程的启动参数包含有switches::kUIPrioritizeInGpuProcess选项,这时候 ImageTransportSurfaceAndroid类的成员函数Initialize做了两件事情:
1. 调用用来描述Browser端GPU通道的GpuChannel对象的成员函数GetPreemptionFlag获得一个PreemptionFlag对象,这个PreemptionFlag对象用来描述Browser端OpenGL上下文是否需要抢占调度。
2. 调用ImageTransportSurfaceAndroid类的成员函数GetHelper获得一个ImageTransportHelper对象,并且以前面获得的PreemptionFlag对象为参数,调用这个ImageTransportHelper对象的成员函数SetPreemptByFlag。
接下来我们就分别分析GpuChannel类的成员函数GetPreemptionFlag和ImageTransportHelper类的成员函数SetPreemptByFlag的实现。
GpuChannel类的成员函数GetPreemptionFlag的实现如下所示:
gpu::PreemptionFlag* GpuChannel::GetPreemptionFlag() {
if (!preempting_flag_.get()) {
preempting_flag_ = new gpu::PreemptionFlag;
io_message_loop_->PostTask(
FROM_HERE, base::Bind(
&GpuChannelMessageFilter::SetPreemptingFlagAndSchedulingState,
filter_, preempting_flag_, num_stubs_descheduled_ > 0));
}
return preempting_flag_.get();
}GpuChannel类的成员函数GetPreemptionFlag返回的是成员变量preempting_flag_描述的一个PreemptionFlag对象。如果这个PreemptionFlag对象还没有创建,那么就会先创建,并且在创建出来之后,向GPU进程的IO线程的消息队列发送一个Task,这个Task绑定的是GpuChannel类的成员变量filter_描述的一个GpuChannelMessageFilter对象的成员函数SetPreemptingFlagAndSchedulingState。
这意味着接下来GpuChannelMessageFilter类的成员函数SetPreemptingFlagAndSchedulingState会在GPU进程的IO线程中调用,它的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
void SetPreemptingFlagAndSchedulingState(
gpu::PreemptionFlag* preempting_flag,
bool a_stub_is_descheduled) {
preempting_flag_ = preempting_flag;
a_stub_is_descheduled_ = a_stub_is_descheduled;
}
......
private:
......
scoped_refptr preempting_flag_;
......
bool a_stub_is_descheduled_;
}; 参数preempt_flag来自GpuChannel类的成员变量preempting_flag_,另外一个参数a_stub_is_descheduled表示是否有Browser端OpenGL上下文自行放弃调度。这两个参数分别保存在GpuChannelMessageFilter类的成员变量preempting_flag_和a_stub_is_descheduled_中。
这里有一点需要注意,当前正在处理的GpuChannelMessageFilter对象是一个Message Filter。这个Message Filter是用来过滤通过Browser端GPU通道发送过来的GPU消息的,也就是用来过滤与Browser端OpenGL上下文相关的GPU消息。后面我们还会看到,这个Message Filter还用来决定Browser端OpenGL上下文是否需要抢占调度。
接下来我们继续分析ImageTransportHelper类的成员函数SetPreemptByFlag的实现,如下所示:
void ImageTransportHelper::SetPreemptByFlag(
scoped_refptr preemption_flag) {
stub_->channel()->SetPreemptByFlag(preemption_flag);
} 当前正在处理的ImageTransportHelper对象的成员变量stub_指向的是一个GpuCommandBufferStub对象。这个GpuCommandBufferStub对象描述的是一个Render端OpenGL上下文。调用这个GpuCommandBufferStub对象的成员函数channel获得的是一个GpuChannel对象。这个GpuChannel对象描述的是Render端GPU通道。ImageTransportHelper类的成员函数SetPreemptByFlag调用这个GpuChannel对象的成员函数SetPreemptByFlag,以便将参数preempting_flag描述的PreemptionFlag对象交给它处理。
GpuChannel类的成员函数SetPreemptByFlag的实现如下所示:
void GpuChannel::SetPreemptByFlag(
scoped_refptr preempted_flag) {
preempted_flag_ = preempted_flag;
for (StubMap::Iterator it(&stubs_);
!it.IsAtEnd(); it.Advance()) {
it.GetCurrentValue()->SetPreemptByFlag(preempted_flag_);
}
} GpuChannel类的成员函数SetPreemptByFlag首先将参数preempting_flag描述的PreemptionFlag对象保存在成员变量preempting_flag_,接下来又依次调用保存在成员变量stubs_中的每一个GpuCommandBufferStub对象的成员函数SetPreemptByFlag,以便将参数preempting_flag描述的PreemptionFlag对象交给它们处理。
注意,当前正在处理的GpuChannel对象描述的是Render端GPU通道,相应地,保存在它的成员变量stubs_中的每一个GpuCommandBufferStub对象描述的都是一个Render端OpenGL上下文。
GpuCommandBufferStub类的成员函数SetPreemptByFlag的实现如下所示:
void GpuCommandBufferStub::SetPreemptByFlag(
scoped_refptr flag) {
preemption_flag_ = flag;
if (scheduler_)
scheduler_->SetPreemptByFlag(preemption_flag_);
} GpuCommandBufferStub类的成员函数SetPreemptByFlag首先将参数flag描述的PreemptionFlag对象保存在成员变量preempting_flag_,接下来又调用成员变量scheduler_描述的一个GpuScheduler对象的成员函数SetPreemptByFlag,以便将参数flag描述的PreemptionFlag对象交给它处理。
GpuScheduler类的成员函数SetPreemptByFlag的实现如下所示:
class GPU_EXPORT GpuScheduler
: NON_EXPORTED_BASE(public CommandBufferEngine),
public base::SupportsWeakPtr {
public:
......
void SetPreemptByFlag(scoped_refptr flag) {
preemption_flag_ = flag;
}
......
private:
......
scoped_refptr preemption_flag_;
......
}; GpuScheduler类的成员函数SetPreemptByFlag将参数flag描述的PreemptionFlag对象保存在成员变量preemption_flag_中。
从前面的分析可以知道,GpuChannel类的成员函数HandleMessage负责将接收到的GPU消息分发给相应的GpuComandBufferStub对象处理。不过在分发之前,会先判断目标GpuComandBufferStub对象描述的OpenGL上下文是否被抢占调度,这是通过调用目标GpuComandBufferStub对象的成员函数IsPreempted实现的。如果被抢占调度,那么GpuChannel类的成员函数HandleMessage就暂时不会将GPU消息分发给目标GpuComandBufferStub对象处理。在我们这个情景中,目标GpuComandBufferStub对象描述的OpenGL上下文即为Render端OpenGL上下文。
GpuComandBufferStub类的成员函数IsPreempted的实现如下所示:
class GpuCommandBufferStub
: public GpuMemoryManagerClient,
public IPC::Listener,
public IPC::Sender,
public base::SupportsWeakPtr {
public:
......
bool IsPreempted() const {
return scheduler_.get() && scheduler_->IsPreempted();
}
......
private:
......
scoped_ptr scheduler_;
......
}; GpuComandBufferStub类的成员函数IsPreempted调用成员变量scheduler_描述的一个GpuScheduler对象的成员函数IsPreempted判断当前正在处理的OpenGL上下文是否被抢占调度。
GpuScheduler类的成员函数IsPreempted的实现如下所示:
bool GpuScheduler::IsPreempted() {
if (!preemption_flag_.get())
return false;
......
return preemption_flag_->IsSet();
}如果GpuScheduler类的成员变量preemption_flag_没有指向一个PreemptionFlag对象,那么GpuScheduler类的成员函数IsPreempted的返回值就为false,表示当前正在处理的OpenGL上下文没有被抢占。
只有当GpuScheduler类的成员变量preemption_flag_指向了一个PreemptionFlag对象的时候,当前正在处理的OpenGL上下文才可能被抢占调度,这取决于成员变量preemption_flag_指向的PreemptionFlag对象的成员函数IsSet的返回值。当这个返回值为true的时候,就表示正在处理的OpenGL上下文被抢占调度。
PreemptionFlag类的定义如下所示:
class PreemptionFlag
: public base::RefCountedThreadSafe {
public:
PreemptionFlag() : flag_(0) {}
bool IsSet() { return !base::AtomicRefCountIsZero(&flag_); }
void Set() { base::AtomicRefCountInc(&flag_); }
void Reset() { base::subtle::NoBarrier_Store(&flag_, 0); }
private:
base::AtomicRefCount flag_;
......
}; PreemptionFlag类有一个类型为AtomicRefCount的成员变量flag_。当它的值不等于0的时候,PreemptionFlag类的成员函数IsSet的返回值就为true。否则的话,PreemptionFlag类的成员函数IsSet的返回值就为false。
PreemptionFlag类的成员变量flag_的值被初始化为0,以后每一次调用PreemptionFlag类的成员函数Set,将会使它的值增加1。另外,调用PreemptionFlag类的成员函数Reset之后,可以将这个成员变量的值重新设置为0。
现在,我们需要知道在什么情况下,Render端OpenGL上下文使用的GpuScheduler对象的成员变量preemption_flag_描述的PreemptionFlag对象的成员函数Set什么时候会被调用。从前面的分析可以知道,这个PreemptionFlag对象就是用来描述Browser端GPU通道的一个GpuChannel对象的成员变量preempting_flag_指向的PreemptionFlag对象。
从前面的分析还可以知道,用来描述Browser端GPU通道的一个GpuChannel对象的成员变量preempting_flag_指向的PreemptionFlag对象还被一个GpuChannelMessageFilter对象的成员变量preempting_flag_引用。这个GpuChannelMessageFilter对象是用来过滤与Browser端OpenGL上下文相关的GPU消息的。在过滤的过程,就有可能会调用其成员变量preempting_flag_引用的PreemptionFlag对象的成员函数Set。
接下来我们就分析GpuChannelMessageFilter类是过滤与Browser端OpenGL上下文相关的GPU消息的过程。不过在分析这个过程之前,我们首先分析GpuChannelMessageFilter类的一个成员变量preemption_state_,如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
GpuChannelMessageFilter(base::WeakPtr gpu_channel,
scoped_refptr sync_point_manager,
scoped_refptr message_loop)
: preemption_state_(IDLE),
...... {}
......
private:
enum PreemptionState {
// Either there's no other channel to preempt, there are no messages
// pending processing, or we just finished preempting and have to wait
// before preempting again.
IDLE,
// We are waiting kPreemptWaitTimeMs before checking if we should preempt.
WAITING,
// We can preempt whenever any IPC processing takes more than
// kPreemptWaitTimeMs.
CHECKING,
// We are currently preempting (i.e. no stub is descheduled).
PREEMPTING,
// We would like to preempt, but some stub is descheduled.
WOULD_PREEMPT_DESCHEDULED,
};
PreemptionState preemption_state_;
......
}; 这个成员变量定义在文件external/chromium_org/content/common/gpu/gpu_channel.cc中。
GpuChannelMessageFilter类的成员变量preemption_state_用来描述Browser端GPU通道的状态,一共有五个:
1. IDLE:空闲状态,或者是因为没有GPU消息需要处理,或者因为刚完成了一次抢占。
2. WAITING:等待状态,等待进入检查状态。
3. CHECKING:检查状态,检查是否需要进入抢占状态。
4. PREEMPTING:抢占状态。
5. WOULD_PREEMPT_DESCHEDULED:在等待进入抢占状态或者正在抢占状态期间,有其它的Browser端OpenGL上下文自动放弃调度。
关于这五个状态的迁移,参见前面的图3。从GpuChannelMessageFilter类的构造函数可以知道,它的成员变量preemption_state_开始时处于IDLE状态。
有三种情况会触发Browser端GPU通道从IDLE状态开始,迁移至其它状态。第一种情况是接收到了新的GPU消息,如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
virtual bool OnMessageReceived(const IPC::Message& message) OVERRIDE {
......
bool handled = false;
......
if (!handled) {
messages_forwarded_to_channel_++;
if (preempting_flag_.get())
pending_messages_.push(PendingMessage(messages_forwarded_to_channel_));
UpdatePreemptionState();
}
......
return handled;
}
......
private:
......
scoped_refptr preempting_flag_;
std::queue pending_messages_;
......
}; 在成员变量preempting_flag_指向了一个PreemptingFlag对象的情况下,GpuChannelMessageFilter类的成员函数OnMessageReceived创建一个PendingMessage对象来描述接收的GPU消息,并且给这个PendingMessage对象赋予一个序号,然后保存在成员变量pending_messages_描述的一个std::queue中。对于非Browser端GPU通道来说,它用来过滤GPU消息的GpuChannelMessageFilter对象的成员变量preempting_flag_没有指向一个PreemptingFlag对象,因此它们的状态会保持为IDLE,不会发生抢占调度的情况。
GpuChannelMessageFilter类的成员函数OnMessageReceived接下来会调用另外一个成员函数UpdatePreemptionState更新Browser端GPU通道的状态。
第二种情况是Browser端OpenGL上下文自动放弃调度和重新请求调度时。前面分析GpuScheduler类的成员函数SetScheduled时提到,当一个OpenGL上下文自动放弃调度和重新请求调度时,会执行GpuScheduler类的成员变量scheduling_changed_callback_描述的一个Callback对象。这个Callback对象是通过调用GpuScheduler类的成员函数SetSchedulingChangedCallback设置的,如下所示:
void GpuScheduler::SetSchedulingChangedCallback(
const SchedulingChangedCallback& callback) {
scheduling_changed_callback_ = callback;
}那么GpuScheduler类的成员函数SetSchedulingChangedCallback是什么时候被谁调用的呢?在前面Chromium硬件加速渲染的OpenGL上下文创建过程分析一文中提到,OpenGL上下文是由GpuCommandBufferStub类的成员函数OnInitialize进行初始化的。在初始化OpenGL上下文的过程中,GpuCommandBufferStub类的成员函数OnInitialize就会调用成员变量scheduler_描述的一个GpuScheduler对象的成员函数SetSchedulingChangedCallback,以便给该GpuScheduler对象的成员变量scheduling_changed_callback_描述的一个Callback对象,如下所示:
void GpuCommandBufferStub::OnInitialize(
base::SharedMemoryHandle shared_state_handle,
IPC::Message* reply_message) {
......
scheduler_->SetSchedulingChangedCallback(
base::Bind(&GpuChannel::StubSchedulingChanged,
base::Unretained(channel_)));
......
}从这里就可以看到,GpuScheduler类的成员变量scheduling_changed_callback_描述的Callback对象绑定的函数是其成员变量channel_描述的一个GpuChannel对象的成员函数StubSchedulingChanged。
这意味着,当一个OpenGL上下文自动放弃调度和重新请求调度时,会调用描述它所使用的GPU通道的一个GpuChannel对象的成员函数StubSchedulingChanged,以便通知该GPU通道,它其中的一个OpenGL上下文调度状态发生了变化。
GpuChannel类的成员函数StubSchedulingChanged的实现如下所示:
void GpuChannel::StubSchedulingChanged(bool scheduled) {
bool a_stub_was_descheduled = num_stubs_descheduled_ > 0;
if (scheduled) {
num_stubs_descheduled_--;
OnScheduled();
} else {
num_stubs_descheduled_++;
}
DCHECK_LE(num_stubs_descheduled_, stubs_.size());
bool a_stub_is_descheduled = num_stubs_descheduled_ > 0;
if (a_stub_is_descheduled != a_stub_was_descheduled) {
if (preempting_flag_.get()) {
io_message_loop_->PostTask(
FROM_HERE,
base::Bind(&GpuChannelMessageFilter::UpdateStubSchedulingState,
filter_,
a_stub_is_descheduled));
}
}
} GpuChannel类的成员变量num_stubs_descheduled_描述的是当前正在处理的GPU通道,有多少个OpenGL上下文自动放弃了调度,它是根据GpuChannel类的成员函数StubSchedulingChanged的调用次数及其参数scheduled计算出来的。
每当一个GPU通道自动放弃调度的OpenGL上下文的个数发生变化时,GpuChannel类的成员函数StubSchedulingChanged就会向GPU进程的IO线程的消息队列发送一个Task,这个Task绑定的函数是用来过滤该GPU通道消息的一个GpuChannelMessageFilter对象的成员函数UpdateStubSchedulingState。
GpuChannelMessageFilter类的成员函数UpdateStubSchedulingState的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
void UpdateStubSchedulingState(bool a_stub_is_descheduled) {
a_stub_is_descheduled_ = a_stub_is_descheduled;
UpdatePreemptionState();
}
......
private:
......
bool a_stub_is_descheduled_;
};GpuChannelMessageFilter类的成员函数UpdateStubSchedulingState将参数a_stub_is_descheduled的值保存在成员变量a_stub_is_descheduled_,因此当GpuChannelMessageFilter类的成员变量a_stub_is_descheduled_等于true的时候,就表示有一个OpenGL上下文自动放弃了调度。
从这里就可以看到,与前面分析的GpuChannelMessageFilter类的成员函数OnMeesageReceived一样,GpuChannelMessageFilter类的成员函数UpdateStubSchedulingState也会调用成员函数UpdatePreemptionState来更新当前正在处理的GPU通道的状态。
第三种情况是用来描述OpenGL上下文的GpuCommandBufferStub类通过成员函数OnMessageReceived处理了一个GPU消息时。从前面分析的GpuChannel类的成员函数HandleMessage可以知道,这时候GpuChannel类的成员函数MessageProcessed会被调用,调用过程如下所示:
void GpuChannel::MessageProcessed() {
messages_processed_++;
if (preempting_flag_.get()) {
io_message_loop_->PostTask(
FROM_HERE,
base::Bind(&GpuChannelMessageFilter::MessageProcessed,
filter_,
messages_processed_));
}
} GpuChannel类的成员函数MessageProcessed首先增加成员变量messages_processed_的值,接着向GPU进程的IO线程的消息队列发送一个Task,这个Task绑定的函数为其成员变量filter_描述的一个GpuChannelMessageFilter对象的成员函数MessageProcessed。GpuChannel类的成员变量messages_processed_描述的是当前正在处理的GPU通道已经处理的GPU消息的个数。
GpuChannelMessageFilter类的成员函数MessageProcessed的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
void MessageProcessed(uint64 messages_processed) {
while (!pending_messages_.empty() &&
pending_messages_.front().message_number <= messages_processed)
pending_messages_.pop();
UpdatePreemptionState();
}
......
};前面提到,GpuChannelMessageFilter类的成员变量pending_messages_描述的一个std::queue保存的每一个PendingMessage对象都代表了一个接收到的但还未处理的GPU消息,并且每一个PendingMessage对象都设置有一个序号。当一个PendingMessage对象的序号小于等于参数messages_processed的值时,就表示该PendingMessage对象代表的GPU消息已经被处理,因此就需要从GpuChannelMessageFilter类的成员变量pending_messages_描述的一个std::queue中移除。
最后,GpuChannelMessageFilter类的成员函数MessageProcessed也像前面描述的两种情况一样,调用另外一个成员函数UpdatePreemptionState更新当前正在处理的GPU通道的状态。
GpuChannelMessageFilter类的成员函数UpdatePreemptionState的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void UpdatePreemptionState() {
switch (preemption_state_) {
case IDLE:
if (preempting_flag_.get() && !pending_messages_.empty())
TransitionToWaiting();
break;
case WAITING:
// A timer will transition us to CHECKING.
DCHECK(timer_.IsRunning());
break;
case CHECKING:
if (!pending_messages_.empty()) {
base::TimeDelta time_elapsed =
base::TimeTicks::Now() - pending_messages_.front().time_received;
if (time_elapsed.InMilliseconds() < kPreemptWaitTimeMs) {
// Schedule another check for when the IPC may go long.
timer_.Start(
FROM_HERE,
base::TimeDelta::FromMilliseconds(kPreemptWaitTimeMs) -
time_elapsed,
this, &GpuChannelMessageFilter::UpdatePreemptionState);
} else {
if (a_stub_is_descheduled_)
TransitionToWouldPreemptDescheduled();
else
TransitionToPreempting();
}
}
break;
case PREEMPTING:
// A TransitionToIdle() timer should always be running in this state.
DCHECK(timer_.IsRunning());
if (a_stub_is_descheduled_)
TransitionToWouldPreemptDescheduled();
else
TransitionToIdleIfCaughtUp();
break;
case WOULD_PREEMPT_DESCHEDULED:
// A TransitionToIdle() timer should never be running in this state.
DCHECK(!timer_.IsRunning());
if (!a_stub_is_descheduled_)
TransitionToPreempting();
else
TransitionToIdleIfCaughtUp();
break;
default:
NOTREACHED();
}
}
......
};从这里可以看到,一个GPU通道可以从初始的IDLE状态迁移到其它状态,需要满足两个条件:
1. 用来过滤GPU消息的GpuChannelMessageFilter对象的成员变量preemption_state_指向了一个PreemptionFlag对象。
2. 接收到了GPU消息。
第1个条件并不是所有的GPU通道都能满足的。前面分析ImageTransportSurfaceAndroid类的成员函数Initialize提到,当GPU进程的启动参数包含有switches::kUIPrioritizeInGpuProcess选项时,用来描述Browser端GPU通道的一个GpuChannel对象的成员函数GetPreemptionFlag会被调用,如下所示:
bool ImageTransportSurfaceAndroid::Initialize() {
......
GpuChannel* parent_channel =
GetHelper()->manager()->LookupChannel(parent_client_id_);
if (parent_channel) {
const CommandLine* command_line = CommandLine::ForCurrentProcess();
if (command_line->HasSwitch(switches::kUIPrioritizeInGpuProcess))
GetHelper()->SetPreemptByFlag(parent_channel->GetPreemptionFlag());
}
return true;
}GpuChannel类的成员函数GetPreemptionFlag在调用的时候,会触发创建一个PreemptionFlag对象,如下所示:
gpu::PreemptionFlag* GpuChannel::GetPreemptionFlag() {
if (!preempting_flag_.get()) {
preempting_flag_ = new gpu::PreemptionFlag;
io_message_loop_->PostTask(
FROM_HERE, base::Bind(
&GpuChannelMessageFilter::SetPreemptingFlagAndSchedulingState,
filter_, preempting_flag_, num_stubs_descheduled_ > 0));
}
return preempting_flag_.get();
}GpuChannel类的成员函数GetPreemptionFlag会将创建的PreemptionFlag对象传递给其成员变量filter_描述的一个GpuChannelMessageFilter对象,如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
public:
......
void SetPreemptingFlagAndSchedulingState(
gpu::PreemptionFlag* preempting_flag,
bool a_stub_is_descheduled) {
preempting_flag_ = preempting_flag;
a_stub_is_descheduled_ = a_stub_is_descheduled;
}
......
};由于用来描述非Browser端GPU通道的GpuChannel对象的成员函数GetPreemptionFlag不会被调用,因此就会导致用来过滤它们的GPU消息的GpuChannelMessageFilter对象的成员变量preempting_flag_没有指向一个PreemptionFlag对象,于是非Browser端GPU通道的状态就会保持为IDLE不变。正是通过这种方式,使得非Browser端OpenGL上下文不会发生抢占调度的情况,而Browser端OpenGL上下文却可以抢占调度。
接下来,我们就分析Browser端GPU通道的状态迁移过程。首先是从IDLE状态迁移到WAITING状态,这是通过调用GpuChannelMessageFilter类的成员函数TransitionToWaiting实现的,如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void TransitionToWaiting() {
DCHECK_EQ(preemption_state_, IDLE);
DCHECK(!timer_.IsRunning());
preemption_state_ = WAITING;
timer_.Start(
FROM_HERE,
base::TimeDelta::FromMilliseconds(kPreemptWaitTimeMs),
this, &GpuChannelMessageFilter::TransitionToChecking);
}
......
};Browser端GPU通道进入WAITING状态后,会启用一个定时器,该定时器在kPreemptWaitTimeMs毫秒之后,会调用GpuChannelMessageFilter类的成员函数TransitionToChecking。
kPreemptWaitTimeMs是一个常量,它的定义如下所示:
// Number of milliseconds between successive vsync. Many GL commands block
// on vsync, so thresholds for preemption should be multiples of this.
const int64 kVsyncIntervalMs = 17;
// Amount of time that we will wait for an IPC to be processed before
// preempting. After a preemption, we must wait this long before triggering
// another preemption.
const int64 kPreemptWaitTimeMs = 2 * kVsyncIntervalMs;kPreemptWaitTimeMs刚好就定义为2个kVsyncIntervalMs的大小,一个kVsyncIntervalMs是17毫秒,等于60fps屏幕刷新频率的一个VSync信号时间间隔,也就是说,kPreemptWaitTimeMs等于2个VSync信号时间间隔。
GpuChannelMessageFilter类的成员函数TransitionToChecking的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void TransitionToChecking() {
DCHECK_EQ(preemption_state_, WAITING);
DCHECK(!timer_.IsRunning());
preemption_state_ = CHECKING;
max_preemption_time_ = base::TimeDelta::FromMilliseconds(kMaxPreemptTimeMs);
UpdatePreemptionState();
}
......
};GpuChannelMessageFilter类的成员函数TransitionToChecking将Browser端GPU通道的状态设置为CHECKING,并且将成员变量max_preemption_time_的值设置为kMaxPreemptTimeMs毫秒,用来描述Browser端GPU通道最多可抢占调度的时间。
kMaxPreemptTimeMs也是一个常量,它的定义如下所示:
const int64 kMaxPreemptTimeMs = kVsyncIntervalMs;kMaxPreemptTimeMs定义为1个kVsyncIntervalMs的大小,也就是1个Vsync信号时间间隔。这意味着Browser端OpenGL上下文最多可抢占其它OpenGL上下文一个Vsync信号时间间隔长度。
Browser端GPU通道从CHECKING状态可以迁移至PREEMPTING状态或者WOULD_PREEMPT_DESCHEDULED状态,也有可能会维持CHECKING不变,如下所示:
switch (preemption_state_) {
......
case CHECKING:
if (!pending_messages_.empty()) {
base::TimeDelta time_elapsed =
base::TimeTicks::Now() - pending_messages_.front().time_received;
if (time_elapsed.InMilliseconds() < kPreemptWaitTimeMs) {
// Schedule another check for when the IPC may go long.
timer_.Start(
FROM_HERE,
base::TimeDelta::FromMilliseconds(kPreemptWaitTimeMs) -
time_elapsed,
this, &GpuChannelMessageFilter::UpdatePreemptionState);
} else {
if (a_stub_is_descheduled_)
TransitionToWouldPreemptDescheduled();
else
TransitionToPreempting();
}
}
break;
......
}在以下两种情况下,CHECKING状态会维持CHECKING状态不变:
1. 此时没有未处理GPU消息。
2. 最早接收到的还未处理GPU消息的流逝时间time_elapsed小于kPreemptWaitTimeMs毫秒,即1个屏幕刷新时间间隔。
在第2种情况下,会启动一个定时器,在(kPreemptWaitTimeMs - time_elapsed)毫秒后,会重新调用GpuChannelMessageFilter类的成员函数UpdatePreemptionState检查是否需要更新状态。
在最早接收到的未处理GPU消息的流逝时间time_elapsed大于等于kPreemptWaitTimeMs毫秒的情况下,CHECKING状态会向PREEMPTING或者WOULD_PREEMPT_DESCHEDULED状态迁移,取决于此时有没有Browser端OpenGL上下文自动放弃调度,即取决于此时GpuChannelMessageFilter类的成员变量a_stub_is_descheduled_的值。
如果GpuChannelMessageFilter类的成员变量a_stub_is_descheduled_的值等于true,那么就调用成员函数TransitionToWouldPreemptDescheduled迁移至WOULD_PREEMPT_DESCHEDULED状态。否则的话,就调用成员函数TransitionToPreempting迁移至PREEMPTING状态。
GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void TransitionToWouldPreemptDescheduled() {
DCHECK(preemption_state_ == CHECKING ||
preemption_state_ == PREEMPTING);
DCHECK(a_stub_is_descheduled_);
if (preemption_state_ == CHECKING) {
// Stop any pending state update checks that we may have queued
// while CHECKING.
timer_.Stop();
} else {
// Stop any TransitionToIdle() timers that we may have queued
// while PREEMPTING.
timer_.Stop();
max_preemption_time_ = timer_.desired_run_time() - base::TimeTicks::Now();
if (max_preemption_time_ < base::TimeDelta()) {
TransitionToIdle();
return;
}
}
preemption_state_ = WOULD_PREEMPT_DESCHEDULED;
preempting_flag_->Reset();
TRACE_COUNTER_ID1("gpu", "GpuChannel::Preempting", this, 0);
UpdatePreemptionState();
}
......
};后面我们会看到,Browser端GPU通道从PREEMPTING状态迁移至WOULD_PREEMPT_DESCHEDULED状态也是调用GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled进行的。
如果是从CHECKING状态迁移至WOULD_PREEMPT_DESCHEDULED状态,那么根据前面的分析,当前可能正启动着一个定时器,这个定时器负责再次调用GpuChannelMessageFilter类的成员函数UpdatePreemptionState更新Browser端GPU通道。这时候GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled首先停止该定时器,然后将Browser端GPU通道的状态个修改为WOULD_PREEMPT_DESCHEDULED。
如果是从PREEMPTING状态迁移至WOULD_PREEMPT_DESCHEDULED状态,那么这时候也会启动着一个定时器,该定时器负责将Browser端GPU通道从PREEMPTING状态迁移至IDLE状态,因此GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled也是首先停止该定时器,然后计算剩余的可抢占调度的时间长度。这个时间长度是Browser端GPU通道从WOULD_PREEMPT_DESCHEDULED状态迁移至PREEMPTING状态时,可用的抢占调度时间长度。
前面分析GpuChannelMessageFilter类的成员函数TransitionToChecking时提到,Browser端GPU通道的最大可抢占调度时间长度设置为kMaxPreemptTimeMs毫秒。假设Browser端GPU通道的状态变化过程为PREEMPTING->WOULD_PREEMPT_DESCHEDULED->PREEMPTING,那么第一次进入PREEMPTING状态的可用抢占调度时间长度为kMaxPreemptTimeMs毫秒,第二次进入PREEMPTING状态的可用抢占调度时间长度为第一次进入PREEMPTING状态时剩余的抢占调度时间。如果剩余的抢占调度时间已经小于0,那么就没有必要第二次进入PREEMPTING状态了。因此,这时候GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled调用另外一个成员函数TransitionToIdle把Browser端GPU通道的状态设置为IDLE。
如果前面所述的剩余的抢占调度时间大于0,那么GpuChannelMessageFilter类的成员函数TransitionToWouldPreemptDescheduled将Browser端GPU通道的状态修改为WOULD_PREEMPT_DESCHEDULED,并且调用成员变量preempting_flag_描述的一个PreemptionFlag对象的成员函数Reset,用来取消Browser端GPU通道之前设置的抢占调度标志。如果此时是从PREEMPTING状态迁移至WOULD_PREEMPT_DESCHEDULED状态,那么Browser端GPU通道设置的抢占调度标志之前就是设置了抢占调度标志的。
GpuChannelMessageFilter类的成员函数TransitionToPreempting的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void TransitionToPreempting() {
DCHECK(preemption_state_ == CHECKING ||
preemption_state_ == WOULD_PREEMPT_DESCHEDULED);
DCHECK(!a_stub_is_descheduled_);
// Stop any pending state update checks that we may have queued
// while CHECKING.
if (preemption_state_ == CHECKING)
timer_.Stop();
preemption_state_ = PREEMPTING;
preempting_flag_->Set();
TRACE_COUNTER_ID1("gpu", "GpuChannel::Preempting", this, 1);
timer_.Start(
FROM_HERE,
max_preemption_time_,
this, &GpuChannelMessageFilter::TransitionToIdle);
UpdatePreemptionState();
}
......
};后面我们会看到,Browser端GPU通道从WOULD_PREEMPT_DESCHEDULED状态迁移至PREEMPTING状态也是调用GpuChannelMessageFilter类的成员函数TransitionToPreempting进行的。
如果是从CHECKING状态迁移至PREEMPTING状态,那么根据前面的分析,当前可能正启动着一个定时器,这个定时器负责再次调用GpuChannelMessageFilter类的成员函数UpdatePreemptionState更新Browser端GPU通道。这时候GpuChannelMessageFilter类的成员函数TransitionToPreempting首先停止该定时器,然后将Browser端GPU通道的状态修改为PREEMPTING。
将Browser端GPU通道的状态个修改为PREEMPTING之后,GpuChannelMessageFilter类的成员函数TransitionToPreempting还有两件重要的事情要做:
1. 调用成员变量preempting_flag_描述的一个PreemptionFlag对象的成员函数Set,给Browser端GPU通道设置抢占调度标志。这样就会导致正在调度的OpenGL上下文停止调度,以便将GPU线程释放出来给Browser端OpenGL上下文使用,正如前面分析的GpuChannel类的成员函数HandleMessage和GpuScheduler类的成员函数PutChanged所示。
2. 启用一个定时器,这个定时器会在max_preemption_time_毫秒后超时,超时之后Browser端GPU通道的状态通过GpuChannelMessageFilter类的成员函数TransitionToIdle重新进入IDLE状态。结合前面的分析,我们就可以知道,这个定时器将Browser端OpenGL上下文的最大抢占调度时间长度限制为kMaxPreemptTimeMs毫秒,即一个屏幕刷新时间间隔,用来避免其他OpenGL上下文被无限抢占调度。
Browser端GPU通道从WOULD_PREEMPT_DESCHEDULED状态可以迁移至PREEMPTING状态或者IDLE状态,如下所示:
switch (preemption_state_) {
......
case WOULD_PREEMPT_DESCHEDULED:
// A TransitionToIdle() timer should never be running in this state.
DCHECK(!timer_.IsRunning());
if (!a_stub_is_descheduled_)
TransitionToPreempting();
else
TransitionToIdleIfCaughtUp();
break;
......
}这个代码片断定义在文件external/chromium_org/content/common/gpu/gpu_channel.cc中。
如果此时没有Browser端OpenGL上下文自动放弃调度,即GpuChannelMessageFilter类的成员变量a_stub_is_descheduled_的值等于false,那么Browser端GPU通道就会调用前面分析过的GpuChannelMessageFilter类的成员函数TransitionToPreempting从WOULD_PREEMPT_DESCHEDULED状态可以迁移至PREEMPTING状态。否则的话,就会调用GpuChannelMessageFilter类的成员函数TransitionToIdleIfCaughtUp检查是否需要从WOULD_PREEMPT_DESCHEDULED状态可以迁移至IDLE状态。
GpuChannelMessageFilter类的成员函数TransitionToIdleIfCaughtUp的实现如下所示:
class GpuChannelMessageFilter : public IPC::MessageFilter {
......
private:
......
void TransitionToIdleIfCaughtUp() {
DCHECK(preemption_state_ == PREEMPTING ||
preemption_state_ == WOULD_PREEMPT_DESCHEDULED);
if (pending_messages_.empty()) {
TransitionToIdle();
} else {
base::TimeDelta time_elapsed =
base::TimeTicks::Now() - pending_messages_.front().time_received;
if (time_elapsed.InMilliseconds() < kStopPreemptThresholdMs)
TransitionToIdle();
}
}
......
};这个函数定义在文件external/chromium_org/content/common/gpu/gpu_channel.cc中。
后面我们会看到,Browser端GPU通道从PREEMPTING状态迁移至IDLE状态也是调用GpuChannelMessageFilter类的成员函数TransitionToIdleIfCaughtUp进行的。
在两种情况下,Browser端GPU通道会从WOULD_PREEMPT_DESCHEDULED和PREEMPTING状态迁移至IDLE状态:
1. 此时没有未处理的GPU消息。
2. 最早接收到的还未处理GPU消息的流逝时间time_elapsed小于kStopPreemptThresholdMs毫秒。
kStopPreemptThresholdMs是一个常量,它的定义如下所示:
const int64 kStopPreemptThresholdMs = kVsyncIntervalMs; 这意味着Browser端GPU通道处于WOULD_PREEMPT_DESCHEDULED和PREEMPTING状态时,如果最早接收到的还未处理GPU消息的流逝时间time_elapsed小于1个屏幕刷新时间间隔,那么Browser端GPU通道就会放弃抢占调度。
这样,我们就分析完成Browser端OpenGL上下文抢占调度过程了。至此,我们也分析完成Chromium硬件加速渲染的OpenGL上下文调度过程了,主要涉及到三个关键过程:
1. OpenGL上下文切换,主要是通过EGL函数eglMakeCurrent实现的。
2. OpenGL上下文自动放弃调度,这主要是等待Sync Point引发的。
3. OpenGL上下文抢占调度,发生在Browser端OpenGL上下文抢占调度其它OpenGL上下文上。
在接下来的一篇文章中,我们分析Browser端合成WebGL端和Render端UI的过程。那时候我们就可以看到,Browser端在合成WebGL端UI的过程中,会用到这篇文章分析的Sync Point机制。敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。