关于负采样tf.nn.sampled_softmax_loss
有NCE loss,这种loss版本用的多,【据说nce是针对多标签的,而本文的是单标签的】下面介绍下tf.nn.sampled_softmax_loss
首先看help的结果:
sampled_softmax_loss(weights, biases, labels, inputs, num_sampled, num_classes,
num_true=1, sampled_values=None, remove_accidental_hits=True,
partition_strategy='mod', name='sampled_softmax_loss', seed=None)
weights是一个shape为[num_classes, dim]的tensor或者是Tensor的列表,列表中的Tensor沿着axis=0方向拼接后的shape仍旧是[num_classes, dim]
The (possibly-sharded) class embeddings这句话咋理解呢?分片的类的embeddings,我理解为各个类的embeddings
用embedding来作为权值w,这还是第一次见。
biases 偏置,shape [num_classes]
labels int64的Tensor,shape [batch_size,num_true] 目标类别。其中的num_true是啥意思??正例的个数??隐含意思是有负例?【补充,是有labels的个数,是正例的个数】
num_sampled 每个batch随机采样的类别数【补充,下面的issues解释为负采样数】
【补充问题,但是我迷糊了,既然一个batch_size有num_true个正例,有num_sampled个负例,这俩数相加不一定是batch_size啊,我这个是问题吗?后来仔细想了下,类别数不是个数,同一类别可以有很多个例子,这么说同一个batch只有一个类别,其他的都是负采样的,按照下面的例子,那么有(batch_size-num_sampled)个数据/例子是num_true类别,有num_sampled个是负采样的,是负例】
num_classes 可能的类数???【补充,正例类别数(已知的类别数),相对负采样的类别的概念】
sampled_values 采样值,由采样函数得到,默认的采样函数是log_uniform_candidate_sampler
是一个元组(`sampled_candidates`, `true_expected_count`, `sampled_expected_count`)
partition_strategy 分割策略,字符串。目前支持"div"和"mod",默认为后者,训练时请使用前者
inputs [batch_size, dim] 输入网络的正向激活。
:
看了这些文档要是能看懂的话就不会有啥难度了,人人都可搞深度学习了,也就没有现在的高薪了,也不会行行转计算机了。
不是哈,没有难度是不可能的。我搜了下发现了一个例子,见这里.我又开始搞mnist了,复盘。
实际整了下这个代码发现loss是下面这种,还有为0的时候???what?这是真的吗?这么看是看不出啥的,必须加上正确率啥的评价指标。
step 3500, loss 2.792289
step 3600, loss 0.068885
step 3700, loss 5.048674
step 3800, loss 1.509981
step 3900, loss 0.000000
step 4000, loss 1.149292
step 4100, loss 3.140670
step 4200, loss 1.334031 那么要明白tf.nn.sampled_softmax_loss返回的是个啥东西,help后的解释是batch_size大小的1维tensor,如下
>>> sampled_loss
因此可知,这个玩意还是调用的交叉熵,这也与源码相符
logits, labels = _compute_sampled_logits(
weights=weights,
biases=biases,
labels=labels,
inputs=inputs,
num_sampled=num_sampled,
num_classes=num_classes,
num_true=num_true,
sampled_values=sampled_values,
subtract_log_q=True,
remove_accidental_hits=remove_accidental_hits,
partition_strategy=partition_strategy,
name=name,
seed=seed)
labels = array_ops.stop_gradient(labels, name="labels_stop_gradient")
sampled_losses = nn_ops.softmax_cross_entropy_with_logits_v2(
labels=labels, logits=logits)
# sampled_losses is a [batch_size] tensor.
return sampled_losses由于sampled_loss是batch_size的长度(与种类数不同,即使相同也不对啊,这里的确不是这个含义),所以不可能从这里求argmax,所以这里面是找不到y_pred的,因此在计算中想求得acc等参数,必须另外写怎么求y_pred,这就麻烦了,这需要另外定义个优化器及方法,这样的话,反向传播也会影响权值的学习,这是不对的,但是,不影响测试集求评价指标,这样就可以直接调用sklearn的classification_report,简单而又方便。
然而我有点蒙蔽,这个保存的模型的输入输出是啥啊??输入毫无疑问,输出呢??我蒙蔽了真的,这个sampled_softmax_loss无法计算y_pred,加载ckpt后我也不知道怎么得到,何况我看了这个ckpt那是相当懵逼,脑袋全是毛线了。。。如图

就特么单层FC搞这么复杂???what?
sampled_loss=tf.nn.sampled_softmax_loss(
weights=weights['h1'],
biases=biases['b1'],
labels=labels,
inputs=layer_1,
num_sampled=num_sampled,
num_true=num_true,
num_classes=num_classes,
name='sampled_softmax_loss')我分明是命名了这个Op,结果没有这个tensor??what?woc
>>> sess.graph.get_tensor_by_name('sampled_softmax_loss:0')
Traceback (most recent call last):
File "", line 1, in
sess.graph.get_tensor_by_name('sampled_softmax_loss:0')
File "D:\python36\lib\site-packages\tensorflow_core\python\framework\ops.py", line 3783, in get_tensor_by_name
return self.as_graph_element(name, allow_tensor=True, allow_operation=False)
File "D:\python36\lib\site-packages\tensorflow_core\python\framework\ops.py", line 3607, in as_graph_element
return self._as_graph_element_locked(obj, allow_tensor, allow_operation)
File "D:\python36\lib\site-packages\tensorflow_core\python\framework\ops.py", line 3649, in _as_graph_element_locked
"graph." % (repr(name), repr(op_name)))
KeyError: "The name 'sampled_softmax_loss:0' refers to a Tensor which does not exist. The operation, 'sampled_softmax_loss', does not exist in the graph."
>>> sess.graph.get_tensor_by_name('add:0')
>>> sess.graph.get_tensor_by_name('relu:0')
>>> sess.graph.get_tensor_by_name('reduce_mean:0')
也是醉了,这个sampled_softmax_loss真是厉害了,我求出来最后的loss怎么测试呢????没有啥评价指标吗?有点不科学啊
直接将测试数据放入,得到的输出layer-256D就是embedding???我表示难以置信,这样的话,同一类别的应该会很相似,下面我试试faiss,
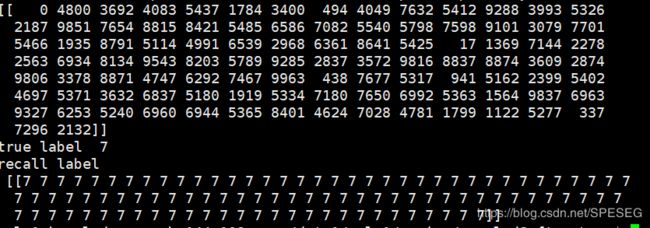
将test的第一个召回了与其近似的100个,果然是同一个标签,训练应该有效果吧。
如果想搞一下深入,那么就是再来几层FC,这样能用这个loss函数吗?我试试
加了一层到128D,结果出现其他标签也是意料之中
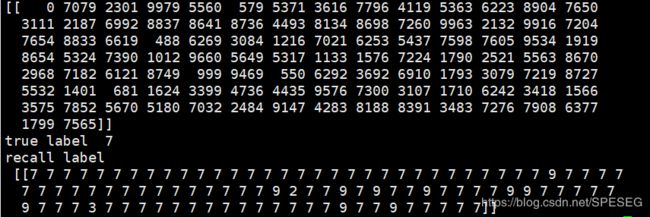
但是我发现如果按照stackoverflow上的做法,shape并不相同啊,如下是两层FC的
>>> weights['h2']
>>> labels
>>> biases['b2']
>>> layer_1
>>> num_sampled
3
>>> num_true
1
>>> num_classes
10 而按照sampled_softmax_loss的help结果(如下),发现权值w和b是不对的shape,试试单层FC
weights [num_classes, dim]
biases [num_classes]
labels [batch_size,num_true]
inputs [batch_size, dim]but 同样的问题
>>> weights['h1']
>>> biases['b1']
>>> labels
>>> layer_1
关于召回率及多个测试,请看关于召回率及hit rate的另一篇博文,再见,这个sampled_softmax_loss只有这点用了,
待续。。。
20200518早上
将醒未醒之时突然发觉这个keras的Embedding与本文得到的结果是一样的shape??如下:
>>> emb=tf.keras.layers.Embedding(784,128)
W0518 09:32:37.357864 9244 deprecation.py:506] From D:\python\lib\site-packages\tensorflow_core\python\keras\initializers.py:119: calling RandomUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
>>> inputs=tf.keras.Input(shape=784)
>>> emb(inputs)
关键在于怎么定义输入维度,是一维还是784??
我以为Embedding就是类似于FC的作用,发现在shape上也不一样,哎,看来梦中都是浮云啊。
后续2:
关于sampled_softmax_loss的进一步解读,官方有个issue讨论。
关于inputs,其中解释说是batch_size大小的固定长dim维度的输入,对于num_classes中的每个类,都有一个dim长度的embedding vector。num_sampled是负采样数,然后计算在labels和负采样类之间的交叉熵,这就化成了二分类问题。
详细的解释看着有点费劲,只有真正了解了才知道吧。
更多问题请加下面的推荐群讨论。
For Video Recommendation in Deep learning QQ Group 277356808
For Speech, Image, Video in deep learning QQ Group 868373192
I'm here waiting for you