前言
之前看了很多关于MySQL索引的文章也看了《高性能MySQL》这本书,自以为熟悉了MySQL索引使用原理,入职面试时和面试官交流,发现对复合索引的使用有些理解偏颇,发现自己的不足整理一下这方面的内容。
实例表:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`uId` int(10) unsigned NOT NULL,
`chatId` smallint(5) unsigned NOT NULL,
`tId` int(11) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `test_uId_chatId_tId` (`uId`,`chatId`,`tId`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4;
最左前缀匹配原则
在MySQL建立联合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例:
对列uId、列chatId和列tId建一个联合索引
shell KEY test_uId_chatId_tId on test(uId,chatId,tId);
联合索引test_uId_chatId_tId 实际建立了(uId)、(uId,chatId)、(uId,chatId,tId)三个索引。
SELECT * FROM test WHERE uId=“1” AND chatId=“2”;
上面这个查询语句执行时会依照最左前缀匹配原则,检索时会使用索引(uId,chatId)进行数据匹配。
注意:
索引的字段可以是任意顺序的,如:
SELECT * FROM test WHERE uId=“1” AND chatId=“2”;
SELECT * FROM test WHERE chatId=“2” AND uId=“1”;
这两个查询语句都会用到索引(uId,chatId),MySQL创建联合索引的规则是首先会对联合合索引的最左边的,也就是第一个字段uId的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个字段chatId进行排序。其实就相当于实现了类似 order by uId chatId这样一种排序规则。
有人会疑惑第二个查询语句不符合最左前缀匹配:首先可以肯定是两个查询语句都包涵索引(uId,chatId)中的uId、chatId两个字段,只是顺序不一样,查询条件一样,最后所查询的结果肯定是一样的。既然结果是一样的,到底以何种顺序的查询方式最好呢?此时我们可以借助mysql查询优化器explain,explain会纠正sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
为什么要使用联合索引
- 减少开销,联合索引test_uId_chatId_tId 实际建立了(uId)、(uId,chatId)、(uId,chatId,tId)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
- 覆盖索引,对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
- 效率高,索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
引申:
对于联合索引(uId,chatId,tId),查询语句SELECT * FROM test WHERE chatId=2;是否能够触发索引,当时面试官问我时我回答是不触发,实际上是触发索引的
原因总结:
EXPLAIN SELECT * FROM `test` WHERE uid='1' AND chatId='2';
EXPLAIN SELECT * FROM `test` WHERE chatId='2';
观察上述两个explain结果中的type字段。查询中分别是:
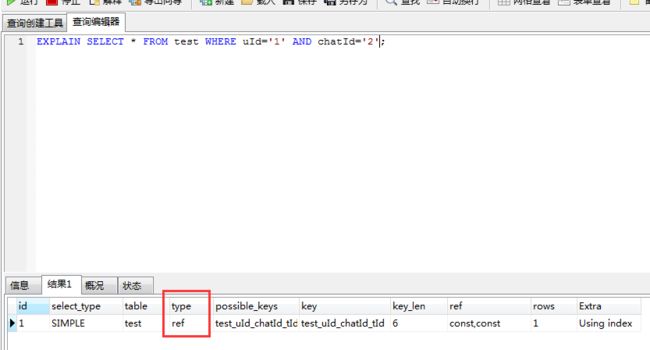
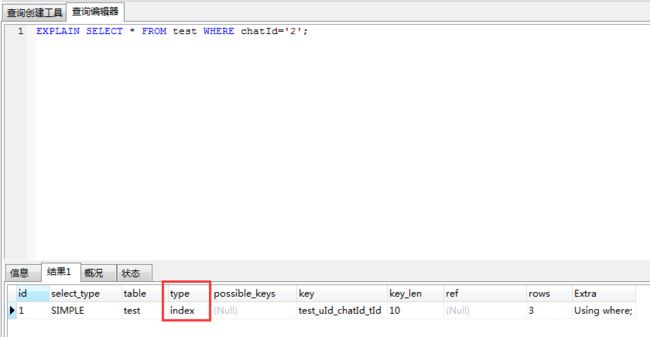
上述两个查询的explain结果中显示用到索引的情况类型是不一样的。可观察explain结果中的type字段,分别是:
- type: index
index:这种类型表示mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个联合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。所以,上述语句会触发索引。 - type: ref
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。