YOLOv1——学习笔记
看了很多论文,始终过后即忘,毕竟不是自己亲自写出来的,还是得来终觉浅。
总述:
one-stage 方法,将一幅图像划分栅格s×s,每个栅格负责检测回归落在该栅格中的目标。在输出层回归位置和类别,cell预测类别,边框预测位置。速度快,45fps。
1主要流程:
输入图像224×224进行训练,划分成7×7的cells。检测时候将图像resize到448×448, 有助于提升map。

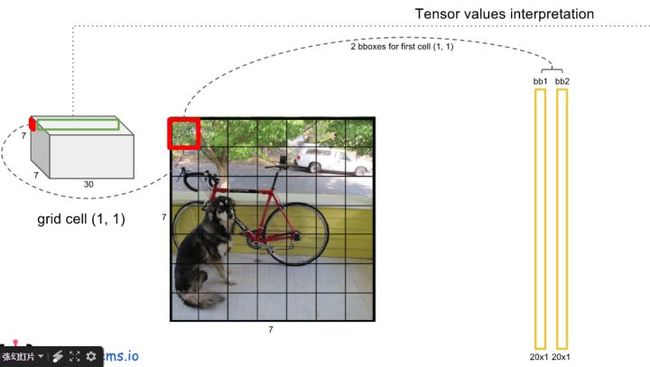
每个网格cell预测B(B=2)个boxes(X-center,Y-center,W,H)、confidence、和类别(20类)Pr(Classi|Object)。
其中boxes四个坐标分别为 x,y归一化到cell的0-1范围,w,h归一化到整个图像的0-1范围。confidence预测表示预测框与实际边界框之间的IOU。每个cell只预测一组类别,跟该cell有几个boxes无关。
测试时候,由下面公式给出每个boxes的预测概率:
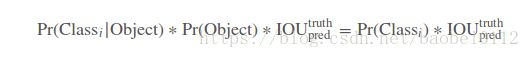
最终的输出为大小( 7×7).cells ×((4.coords+1.confidence)×2.boxes+20.classes)= 7*7*30的张量。

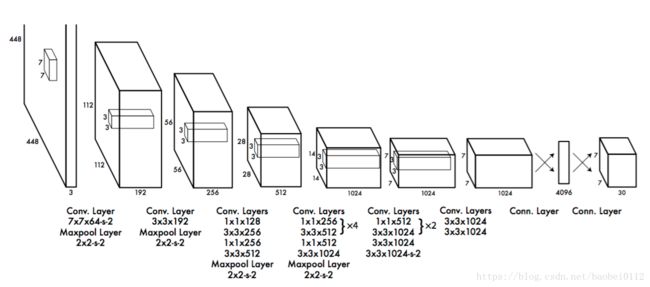
2. 网络设计
网络有24个卷积层,2个全连接层
3. 训练
先用上图前20卷积层+最大池化层+全连接层训练,执行检测时候,去掉最后两层改用4个卷积层+2全连接层,输入分辨率提升至448×448。最后一层进行类别概率预测和框坐标,均采用归一化到0-1范围。
1)最后一层使用线性激活函数,其他层使用下面的泄漏修正激活函数:
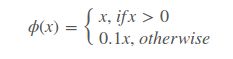
2)对平方和误差进行优化。一张图像中,大多数网格中不包含目标,这将这些单元格的“置信度”分数推向零,通常压倒了包含目标的单元格的梯度。这可能导致模型不稳定,从而导致训练早期发散。为了改善这一点,我们增加了边界框坐标预测损失,并减少了不包含目标边界框的置信度预测损失。我们使用两个参数λcoord和λnoobj来完成这个工作。我们设置λcoord=5和λnoobj=.5。
3)平方和误差也可以在大盒子和小盒子中同样加权误差。我们的错误指标应该反映出,大盒子小偏差的重要性不如小盒子小偏差的重要性。为了部分解决这个问题,我们直接预测边界框宽度和高度的平方根,而不是宽度和高度。
4)YOLO每个网格单元预测多个边界框。在训练时,每个目标我们只需要一个边界框预测器来负责。我们指定一个预测器“负责”根据哪个预测与真实值之间具有当前最高的IOU来预测目标。这导致边界框预测器之间的专业化。每个预测器可以更好地预测特定大小,方向角,或目标的类别,从而改善整体召回率。
在训练期间,我们优化以下多部分损失函数:


我们对Pascal VOC 2007和2012的训练和验证数据集进行了大约135个迭代周期的网络训练。在Pascal VOC 2012上进行测试时,我们的训练包含了Pascal VOC 2007的测试数据。在整个训练过程中,我们使用了64的批大小,0.9的动量和0.0005的衰减。
5)学习率方案如下:对于第一个迭代周期,我们慢慢地将学习率0.001提高到0.01。如果我们从高学习率开始,我们的模型往往会由于不稳定的梯度而发散。我们继续以0.01的学习率训练75个迭代周期,然后用0.001的学习率训练30个迭代周期,最后用0.0001学习率训练30个迭代周期。
6)为了避免过度拟合,我们使用丢弃和大量的数据增强。在第一个连接层之后,丢弃层使用=.5的比例,防止层之间的互相适应[18]。对于数据增强,我们引入高达原始图像20%大小的随机缩放和转换。我们还在HSV色彩空间中使用高达1.5的因子来随机调整图像的曝光和饱和度。
4.推断
就像在训练中一样,预测测试图像的检测只需要一次网络评估。在Pascal VOC上,每张图像上网络预测98个边界框和每个框的类别概率。YOLO在测试时非常快,因为它只需要一次网络评估,不像基于分类器的方法。
网格设计强化了边界框预测中的空间多样性。通常很明显一个目标落在哪一个网格单元中,而网络只能为每个目标预测一个边界框。然而,一些大的目标或靠近多个网格单元边界的目标可以被多个网格单元很好地定位。非极大值抑制可以用来修正这些多重检测。对于R-CNN或DPM而言,性能不是关键的,非最大抑制会增加2-3%的mAP。
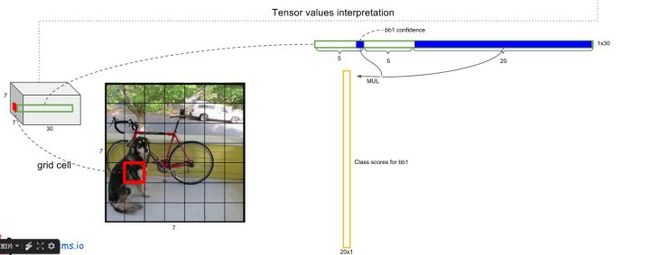

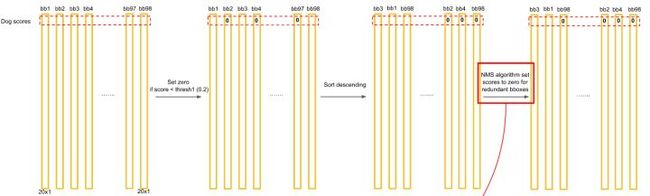
- 对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)


- 得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。