哈夫曼编码(基于哈夫曼树-最优二叉树,不唯一)、B树(b-树)、B+树
整合自:
http://blog.csdn.net/shuangde800/article/details/7341289
http://www.cnblogs.com/Jezze/archive/2011/12/23/2299884.html
http://blog.csdn.net/jdhanhua/article/details/6621026
B树介绍:点击打开链接
tire树:点击打开链接 点击打开链接
树集合:点击打开链接
1.定义:
什么是哈夫曼树?
让我们先举一个例子。
判定树:
在一般的数据结构的书中,树的那章后面,著者一般都会介绍一下哈夫曼(HUFFMAN)
树和哈夫曼编码。哈夫曼编码是哈夫曼树的一个应用。哈夫曼编码应用广泛,如
JPEG中就应用了哈夫曼编码。 首先介绍什么是哈夫曼树。哈夫曼树又称最优二叉树,
是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点
的权值乘上其到根结点的 路径长度(若根结点为0层,叶结点到根结点的路径长度
为叶结点的层数)。树的带权路径长度记为WPL= (W1*L1+W2*L2+W3*L3+...+Wn*Ln)
,N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径
长度为Li(i=1,2,...n)。可以证明哈夫曼树的WPL是最小的。
2.哈夫曼编码步骤:
一、对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F= {T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。(为方便在计算机上实现算 法,一般还要求以Ti的权值Wi的升序排列。)
二、在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,直到集合F中只有一棵二叉树为止。
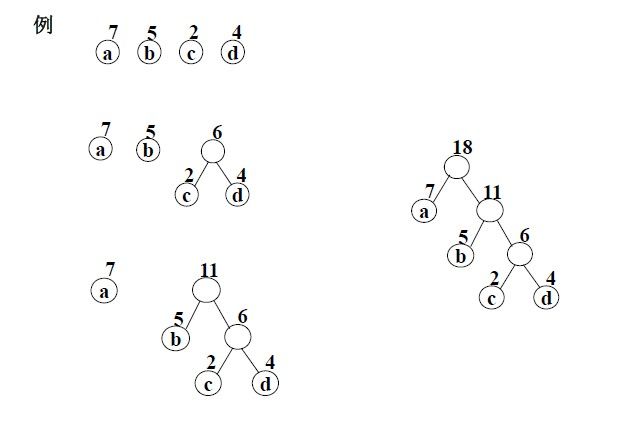
简易的理解就是,假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:

虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:

再依次建立哈夫曼树,如下图:

其中各个权值替换对应的字符即为下图:

所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
例2:
例3:
霍夫曼编码是一种无前缀编码。解码时不会混淆。其主要应用在数据压缩,加密解密等场合。
3.代码实现:
//首先:定义哈夫曼树的节点类,为了方便使用集合类的排序功能,实现了Comparable接口(可以不是实现该接口,此时需要实现排序功能)
public class Node implements Comparable> {
private T data;
private double weight;
private Node left;
private Node right;
public Node(T data, double weight){
this.data = data;
this.weight = weight;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
@Override
public String toString(){
return "data:"+this.data+";weight:"+this.weight;
}
@Override
public int compareTo(Node other) {
if(other.getWeight() > this.getWeight()){
return 1;
}
if(other.getWeight() < this.getWeight()){
return -1;
}
return 0;
}
}
//然后:实现哈夫曼树的主题类,其中包括两个静态的泛型方法,为创建哈夫曼树和广度优先遍历哈夫曼树
package my.huffmanTree;
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Queue;
public class HuffmanTree {
public static Node createTree(List> nodes){
while(nodes.size() > 1){
Collections.sort(nodes);
Node left = nodes.get(nodes.size()-1);
Node right = nodes.get(nodes.size()-2);
Node parent = new Node(null, left.getWeight()+right.getWeight());
parent.setLeft(left);
parent.setRight(right);
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);
}
public static List> breadth(Node root){
List> list = new ArrayList>();
Queue> queue = new ArrayDeque>();
if(root != null){
queue.offer(root);
}
while(!queue.isEmpty()){
list.add(queue.peek());
Node node = queue.poll();
if(node.getLeft() != null){
queue.offer(node.getLeft());
}
if(node.getRight() != null){
queue.offer(node.getRight());
}
}
return list;
}
}
最后:编写一共测试端
[java] view plain copy
package my.huffmanTree;
import java.util.ArrayList;
import java.util.List;
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
List> list = new ArrayList>();
list.add(new Node("a",7));
list.add(new Node("b",5));
list.add(new Node("c",4));
list.add(new Node("d",2));
Node root = HuffmanTree.createTree(list);
System.out.println(HuffmanTree.breadth(root));
// System.out.println(list);
}
}
其中添加四个节点,其权重为{7,5,4,2},最终按照广度优先遍历,应为七个节点,为:18,7,11,5,6,2,4;
控制台输出为:
[data:null;weight:18.0, data:a;weight:7.0, data:null;weight:11.0, data:b;weight:5.0, data:null;weight:6.0, data:d;weight:2.0, data:c;weight:4.0]
与实际想符合。 ----------------------------------------
B树总结
红黑树:平衡二叉树,广泛用在C++的STL中。map和set都是用红黑树实现的。
B/B+树用在磁盘文件组织 数据索引和数据库索引
Trie树 字典树,用在统计和排序大量字符串(场景自己yy = =)
AVL RBtree
B B+
Trie
AVL早期有应用在linux内核上,后来被RBtree代替了,具体是用在哪个模块上,sorry,我忘了,求知欲那么强的你,google一下就有答案了,两者都保持log(n)的插入与查询,是平衡的BST,不会出现(n2)的糟糕情况,那为什么linux内核要用RBtree替代AVL呢,我没具体了解过,但从原理上看,个人猜想是AVL需要大量的旋转来保持平衡,而RBtree的旋转调节可能会少些,这是个人的臆断,真心希望有深入理解的同仁指正,用力的拍,另外我们熟悉的STL的map容器底层是RBtree,当然指的不是unordered_map,后者是hash。
而 B B+则运用在file system database这类持续存储结构,同样能保持lon(n)的插入与查询,也需要额外的平衡调节。像mysql的数据库定义是可以指定B+ 索引还是hash索引。
trie树大都用在word的匹配,但单纯的trie内存消耗很大,建trie树也需要些时间,通常用在带词典的机械分词,jieba分词就是建立在trie上匹配的,trie有其他变体可以压缩空间,像double array trie这类比较老且经典的压缩方法,也有其他比较新的压缩方式,看论文时有看过,没自己实现过所以不断言了,其实面对多模匹配trie没有其变体aho-corasick来得理想,另外aho-corasick也是可以用巧妙的方法来进行压缩空间,这里不再展开,毕竟手机码字,同时想基数树与其也类似,在nginx上有应用,说到aho-corasick其实早期的入侵检测工具snort也有应用实现,但如今改成wu-menber了,具体记不清了,其实trie还是挺有用的,Tengine也用trie实现了了匹配模块。但要是用在大量单词的匹配上确实吃内存。
红黑树的应用就很多了,除了上面同学提到的STL,还有
- 著名的linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块
- epoll在内核中的实现,用红黑树管理事件块
- nginx中,用红黑树管理timer等
- Java的TreeMap实现
B和B+主要用在文件系统以及数据库中做索引等,比如Mysql:B-Tree Index in MySql
trie 树的一个典型应用是前缀匹配,比如下面这个很常见的场景,在我们输入时,搜索引擎会给予提示
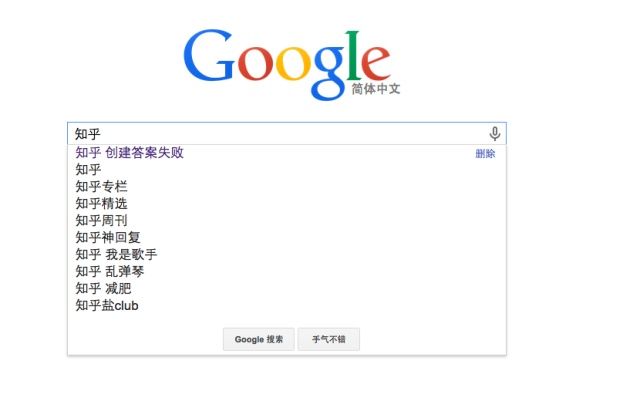
还有比如IP选路,也是前缀匹配,一定程度会用到trie
B树是为磁盘或其他直接存取辅助存储设置而设计的一种平衡查找树。其能够有效降低磁盘I/O操作次数。许多数据库系统使用B树或B树的变形来储存信息。参考《算法导论》第二版第十八章的思想使用java语言实现了一颗简单的B树,在此跟大家分享下:
package com.discover;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Random;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
/**
* 一颗B树的简单实现。
*
* 其实现原理参考《算法导论》第二版第十八章。
*
* 如果大家想读懂这些源代码,不妨先看看上述章节。
*
* @author WangPing
*
* @param - 键类型
* @param - 值类型
*/
public class BTree
{
private static Log logger = LogFactory.getLog(BTree.class);
/**
* 在B树节点中搜索给定键值的返回结果。
*
* 该结果有两部分组成。第一部分表示此次查找是否成功,
* 如果查找成功,第二部分表示给定键值在B树节点中的位置,
* 如果查找失败,第二部分表示给定键值应该插入的位置。
*/
private static class SearchResult
{
private boolean result;
private int index;
public SearchResult(boolean result, int index)
{
this.result = result;
this.index = index;
}
public boolean getResult()
{
return result;
}
public int getIndex()
{
return index;
}
}
/**
* 为了简单起见,暂时只支持整型的key,
* 等到工作完成后,支持泛型。
*
*
* TODO 需要考虑并发情况下的存取。
*/
private static class BTreeNode
{
/** 节点的关键字,以非降序存放 */
private List keys;
/** 内节点的子节点 */
private List children;
/** 是否为叶子节点 */
private boolean leaf;
public BTreeNode()
{
keys = new ArrayList();
children = new ArrayList();
leaf = false;
}
public boolean isLeaf()
{
return leaf;
}
public void setLeaf(boolean leaf)
{
this.leaf = leaf;
}
/**
* 返回关键字的个数。如果是非叶子节点,该节点的
* 子节点个数为({@link #size()} + 1)。
*
* @return 关键字的个数
*/
public int size()
{
return keys.size();
}
/**
* 在节点中查找给定的key,如果节点中存在给定的
* key,则返回一个SearchResult,
* 标识此次查找成功,给定key在节点中的索引和给定
* key对应的值。如果不存在,则返回SearchResult
* 标识此次查找失败,给定key应该插入的位置,该key
* 对应的值为null。
*
* 如果查找失败,返回结果中的索引域为[0, {@link #size()}];
* 如果查找成功,返回结果中的索引域为[0, {@link #size()} - 1]
*
* 这是一个二分查找算法,可以保证时间复杂度为O(log(t))。
*
* @param key - 给定的键值
* @return - 查找结果
*/
public SearchResult searchKey(Integer key)
{
int l = 0;
int h = keys.size() - 1;
int mid = 0;
while(l <= h)
{
mid = (l + h) / 2; // 先这么写吧,BTree实现中,l+h不可能溢出
if(keys.get(mid) == key)
break;
else if(keys.get(mid) > key)
h = mid - 1;
else // if(keys.get(mid) < key)
l = mid + 1;
}
boolean result = false;
int index = 0;
if(l <= h) // 说明查找成功
{
result = true;
index = mid; // index表示元素所在的位置
}
else
{
result = false;
index = l; // index表示元素应该插入的位置
}
return new SearchResult(result, index);
}
/**
* 将给定的key追加到节点的末尾,
* 一定要确保调用该方法之后,节点中的关键字还是
* 以非降序存放。
*
* @param key - 给定的键值
*/
public void addKey(Integer key)
{
keys.add(key);
}
/**
* 删除给定索引的键值。
*
* 你需要自己保证给定的索引是合法的。
*
* @param index - 给定的索引
*/
public void removeKey(int index)
{
keys.remove(index);
}
/**
* 得到节点中给定索引的键值。
*
* 你需要自己保证给定的索引是合法的。
*
* @param index - 给定的索引
* @return 节点中给定索引的键值
*/
public Integer keyAt(int index)
{
return keys.get(index);
}
/**
* 在该节点中插入给定的key,
* 该方法保证插入之后,其键值还是以非降序存放。
*
* 不过该方法的时间复杂度为O(t)。
*
* TODO 需要考虑键值是否可以重复。
*
* @param key - 给定的键值
*/
public void insertKey(Integer key)
{
SearchResult result = searchKey(key);
insertKey(key, result.getIndex());
}
/**
* 在该节点中给定索引的位置插入给定的key,
* 你需要自己保证key插入了正确的位置。
*
* @param key - 给定的键值
* @param index - 给定的索引
*/
public void insertKey(Integer key, int index)
{
/* TODO
* 通过新建一个ArrayList来实现插入真的很恶心,先这样吧
* 要是有类似C中的reallocate就好了。
*/
List newKeys = new ArrayList();
int i = 0;
// index = 0或者index = keys.size()都没有问题
for(; i < index; ++ i)
newKeys.add(keys.get(i));
newKeys.add(key);
for(; i < keys.size(); ++ i)
newKeys.add(keys.get(i));
keys = newKeys;
}
/**
* 返回节点中给定索引的子节点。
*
* 你需要自己保证给定的索引是合法的。
*
* @param index - 给定的索引
* @return 给定索引对应的子节点
*/
public BTreeNode childAt(int index)
{
if(isLeaf())
throw new UnsupportedOperationException("Leaf node doesn't have children.");
return children.get(index);
}
/**
* 将给定的子节点追加到该节点的末尾。
*
* @param child - 给定的子节点
*/
public void addChild(BTreeNode child)
{
children.add(child);
}
/**
* 删除该节点中给定索引位置的子节点。
*
* 你需要自己保证给定的索引是合法的。
*
* @param index - 给定的索引
*/
public void removeChild(int index)
{
children.remove(index);
}
/**
* 将给定的子节点插入到该节点中给定索引
* 的位置。
*
* @param child - 给定的子节点
* @param index - 子节点带插入的位置
*/
public void insertChild(BTreeNode child, int index)
{
List newChildren = new ArrayList();
int i = 0;
for(; i < index; ++ i)
newChildren.add(children.get(i));
newChildren.add(child);
for(; i < children.size(); ++ i)
newChildren.add(children.get(i));
children = newChildren;
}
}
private static final int DEFAULT_T = 2;
/** B树的根节点 */
private BTreeNode root;
/** 根据B树的定义,B树的每个非根节点的关键字数n满足(t - 1) <= n <= (2t - 1) */
private int t = DEFAULT_T;
/** 非根节点中最小的键值数 */
private int minKeySize = t - 1;
/** 非根节点中最大的键值数 */
private int maxKeySize = 2*t - 1;
public BTree()
{
root = new BTreeNode();
root.setLeaf(true);
}
public BTree(int t)
{
this();
this.t = t;
minKeySize = t - 1;
maxKeySize = 2*t - 1;
}
/**
* 搜索给定的key。
*
* TODO 需要重新定义返回结果,应该返回
* key对应的值。
*
* @param key - 给定的键值
* @return TODO 得返回值类型
*/
public int search(Integer key)
{
return search(root, key);
}
/**
* 在以给定节点为根的子树中,递归搜索
* 给定的key
*
* @param node - 子树的根节点
* @param key - 给定的键值
* @return TODO
*/
private static int search(BTreeNode node, Integer key)
{
SearchResult result = node.searchKey(key);
if(result.getResult())
return result.getIndex();
else
{
if(node.isLeaf())
return -1;
else
search(node.childAt(result.getIndex()), key);
}
return -1;
}
/**
* 分裂一个满子节点childNode。
*
* 你需要自己保证给定的子节点是满节点。
*
* @param parentNode - 父节点
* @param childNode - 满子节点
* @param index - 满子节点在父节点中的索引
*/
private void splitNode(BTreeNode parentNode, BTreeNode childNode, int index)
{
assert childNode.size() == maxKeySize;
BTreeNode siblingNode = new BTreeNode();
siblingNode.setLeaf(childNode.isLeaf());
// 将满子节点中索引为[t, 2t - 2]的(t - 1)个关键字插入新的节点中
for(int i = 0; i < minKeySize; ++ i)
siblingNode.addKey(childNode.keyAt(t + i));
// 提取满子节点中的中间关键字,其索引为(t - 1)
Integer key = childNode.keyAt(t - 1);
// 删除满子节点中索引为[t - 1, 2t - 2]的t个关键字
for(int i = maxKeySize - 1; i >= t - 1; -- i)
childNode.removeKey(i);
if(!childNode.isLeaf()) // 如果满子节点不是叶节点,则还需要处理其子节点
{
// 将满子节点中索引为[t, 2t - 1]的t个子节点插入新的节点中
for(int i = 0; i < minKeySize + 1; ++ i)
siblingNode.addChild(childNode.childAt(t + i));
// 删除满子节点中索引为[t, 2t - 1]的t个子节点
for(int i = maxKeySize; i >= t; -- i)
childNode.removeChild(i);
}
// 将key插入父节点
parentNode.insertKey(key, index);
// 将新节点插入父节点
parentNode.insertChild(siblingNode, index + 1);
}
/**
* 在一个非满节点中插入给定的key。
*
* @param node - 非满节点
* @param key - 给定的键值
*/
private void insertNotFull(BTreeNode node, Integer key)
{
assert node.size() < maxKeySize;
if(node.isLeaf()) // 如果是叶子节点,直接插入
node.insertKey(key);
else
{
/* 找到key在给定节点应该插入的位置,那么key应该插入
* 该位置对应的子树中
*/
SearchResult result = node.searchKey(key);
BTreeNode childNode = node.childAt(result.getIndex());
if(childNode.size() == 2*t - 1) // 如果子节点是满节点
{
// 则先分裂
splitNode(node, childNode, result.getIndex());
/* 如果给定的key大于分裂之后新生成的键值,则需要插入该新键值的右边,
* 否则左边。
*/
if(key > node.keyAt(result.getIndex()))
childNode = node.childAt(result.getIndex() + 1);
}
insertNotFull(childNode, key);
}
}
/**
* 在B树中插入给定的key。
*
* @param key - 给定的键值
*/
public void insert(Integer key)
{
if(root.size() == maxKeySize) // 如果根节点满了,则B树长高
{
BTreeNode newRoot = new BTreeNode();
newRoot.setLeaf(false);
newRoot.addChild(root);
splitNode(newRoot, root, 0);
root = newRoot;
}
insertNotFull(root, key);
}
/**
* 从B树中删除一个给定的key。
*
* @param key - 给定的键值
*/
public void delete(Integer key)
{
// root的情况还需要做一些特殊处理
delete(root, key);
}
/**
* 从以给定node为根的子树中删除指定的key。
*
* 删除的实现思想请参考《算法导论》第二版的第18章。
*
* TODO 需要重构,代码太长了
*
* @param node - 给定的节点
* @param key - 给定的键值
*/
public void delete(BTreeNode node, Integer key)
{
// 该过程需要保证,对非根节点执行删除操作时,其关键字个数至少为t。
assert node.size() >= t || node == root;
SearchResult result = node.searchKey(key);
/*
* 因为这是查找成功的情况,0 <= result.getIndex() <= (node.size() - 1),
* 因此(result.getIndex() + 1)不会溢出。
*/
if(result.getResult())
{
// 1.如果关键字在节点node中,并且是叶节点,则直接删除。
if(node.isLeaf())
node.removeKey(result.getIndex());
else
{
// 2.a 如果节点node中前于key的子节点包含至少t个关键字
BTreeNode leftChildNode = node.childAt(result.getIndex());
if(leftChildNode.size() >= t)
{
// 使用leftChildNode中的最后一个键值代替node中的key
node.removeKey(result.getIndex());
node.insertKey(leftChildNode.keyAt(leftChildNode.size() - 1), result.getIndex());
delete(leftChildNode, leftChildNode.keyAt(leftChildNode.size() - 1));
// node.
}
else
{
// 2.b 如果节点node中后于key的子节点包含至少t个关键字
BTreeNode rightChildNode = node.childAt(result.getIndex() + 1);
if(rightChildNode.size() >= t)
{
// 使用rightChildNode中的第一个键值代替node中的key
node.removeKey(result.getIndex());
node.insertKey(rightChildNode.keyAt(0), result.getIndex());
delete(rightChildNode, rightChildNode.keyAt(0));
}
else // 2.c 前于key和后于key的子节点都只包含t-1个关键字
{
node.removeKey(result.getIndex());
node.removeChild(result.getIndex() + 1);
// 将key和rightChildNode中的键值合并进leftChildNode
leftChildNode.addKey(key);
for(int i = 0; i < rightChildNode.size(); ++ i)
leftChildNode.addKey(rightChildNode.keyAt(i));
// 将rightChildNode中的子节点合并进leftChildNode,如果有的话
if(!rightChildNode.isLeaf())
{
for(int i = 0; i <= rightChildNode.size(); ++ i)
leftChildNode.addChild(rightChildNode.childAt(i));
}
delete(leftChildNode, key);
}
}
}
}
else
{
/*
* 因为这是查找失败的情况,0 <= result.getIndex() <= node.size(),
* 因此(result.getIndex() + 1)会溢出。
*/
if(node.isLeaf()) // 如果关键字不在节点node中,并且是叶节点,则什么都不做,因为该关键字不在该B树中
{
logger.info("The key: " + key + " isn't in this BTree.");
return;
}
BTreeNode childNode = node.childAt(result.getIndex());
if(childNode.size() >= t)
delete(childNode, key); // 递归删除
else // 3
{
// 先查找右边的兄弟节点
BTreeNode siblingNode = null;
int siblingIndex = -1;
if(result.getIndex() < node.size()) // 存在右兄弟节点
{
if(node.childAt(result.getIndex() + 1).size() >= t)
{
siblingNode = node.childAt(result.getIndex() + 1);
siblingIndex = result.getIndex() + 1;
}
}
// 如果右边的兄弟节点不符合条件,则试试左边的兄弟节点
if(siblingNode == null)
{
if(result.getIndex() > 0) // 存在左兄弟节点
{
if(node.childAt(result.getIndex() - 1).size() >= t)
{
siblingNode = node.childAt(result.getIndex() - 1);
siblingIndex = result.getIndex() - 1;
}
}
}
// 3.a 有一个相邻兄弟节点至少包含t个关键字
if(siblingNode != null)
{
if(siblingIndex < result.getIndex()) // 左兄弟节点满足条件
{
childNode.insertKey(node.keyAt(siblingIndex), 0);
node.removeKey(siblingIndex);
node.insertKey(siblingNode.keyAt(siblingNode.size() - 1), siblingIndex);
siblingNode.removeKey(siblingNode.size() - 1);
// 将左兄弟节点的最后一个孩子移到childNode
if(!siblingNode.isLeaf())
{
childNode.insertChild(siblingNode.childAt(siblingNode.size()), 0);
siblingNode.removeChild(siblingNode.size());
}
}
else // 右兄弟节点满足条件
{
childNode.insertKey(node.keyAt(result.getIndex()), childNode.size() - 1);
node.removeKey(result.getIndex());
node.insertKey(siblingNode.keyAt(0), result.getIndex());
siblingNode.removeKey(0);
// 将右兄弟节点的第一个孩子移到childNode
// childNode.insertChild(siblingNode.childAt(0), childNode.size() + 1);
if(!siblingNode.isLeaf())
{
childNode.addChild(siblingNode.childAt(0));
siblingNode.removeChild(0);
}
}
delete(childNode, key);
}
else // 3.b 如果其相邻左右节点都包含t-1个关键字
{
if(result.getIndex() < node.size()) // 存在右兄弟
{
BTreeNode rightSiblingNode = node.childAt(result.getIndex() + 1);
childNode.addKey(node.keyAt(result.getIndex()));
node.removeKey(result.getIndex());
node.removeChild(result.getIndex() + 1);
for(int i = 0; i < rightSiblingNode.size(); ++ i)
childNode.addKey(rightSiblingNode.keyAt(i));
if(!rightSiblingNode.isLeaf())
{
for(int i = 0; i <= rightSiblingNode.size(); ++ i)
childNode.addChild(rightSiblingNode.childAt(i));
}
}
else // 存在左节点
{
BTreeNode leftSiblingNode = node.childAt(result.getIndex() - 1);
childNode.addKey(node.keyAt(result.getIndex() - 1));
node.removeKey(result.getIndex() - 1);
node.removeChild(result.getIndex() - 1);
for(int i = leftSiblingNode.size() - 1; i >= 0; -- i)
childNode.insertKey(leftSiblingNode.keyAt(i), 0);
if(!leftSiblingNode.isLeaf())
{
for(int i = leftSiblingNode.size(); i >= 0; -- i)
childNode.insertChild(leftSiblingNode.childAt(i), 0);
}
}
// 如果node是root并且node不包含任何关键字了
if(node == root && node.size() == 0)
root = childNode;
delete(childNode, key);
}
}
}
}
/**
* 一个简单的层次遍历B树实现,用于输出B树。
*
* TODO 待改进,使显示更加形象化。
*/
public void output()
{
Queue queue = new LinkedList();
queue.offer(root);
while(!queue.isEmpty())
{
BTreeNode node = queue.poll();
for(int i = 0; i < node.size(); ++ i)
System.out.print(node.keyAt(i) + " ");
System.out.println();
if(!node.isLeaf())
{
for(int i = 0; i <= node.size(); ++ i)
queue.offer(node.childAt(i));
}
}
}
public static void main(String[] args)
{
Random random = new Random();
BTree btree = new BTree();
for(int i = 0; i < 10; ++ i)
{
int r = random.nextInt(100);
System.out.println(r);
btree.insert(r);
}
System.out.println("----------------------");
btree.output();
}
}
其他java实现balance tree
package debuggees;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.NoSuchElementException;
/**
* jBixbe debuggee: test insert and delete operation of a balanced tree data
* structure. Using integer values read from keyboard as tree elements.
*
* @author ds-emedia
*/
public class BTree> {
private static BTree tree = new BTree();
private static BufferedReader reader = new BufferedReader(
new InputStreamReader(System.in));
public static void main(String args[]) throws IOException {
System.out.println("test balanced tree operations");
System.out.println("*****************************");
String input;
Integer value;
do {
input = stringInput("please select: [i]nsert, [d]elete, [e]xit");
switch (input.charAt(0)) {
case 'i':
value = Integer.parseInt(stringInput("insert: "), 10);
if (tree.isMember(value)) {
System.out.println("value " + value + " already in tree");
} else {
tree.insert(value);
}
break;
case 'd':
value = Integer.parseInt(stringInput("delete: "), 10);
if (tree.isMember(value)) {
tree.delete(value);
} else {
System.out.println(value + " not found in tree");
}
break;
}
} while ((input.charAt(0) != 'e'));
}
private static String stringInput(String inputRequest) throws IOException {
System.out.println(inputRequest);
return reader.readLine();
}
/* +++++++++++ instance declarations +++++++++++ */
private Node root;
/**
* Creates an empty balanced tree.
*/
public BTree() {
root = null;
}
/**
* Creates a balances tree using the given node as tree root.
*/
public BTree(Node root) {
this.root = root;
}
/**
* Inserts an element into the tree.
*/
public void insert(T info) {
insert(info, root, null, false);
}
/**
* Checks whether the given element is already in the tree.
*/
public boolean isMember(T info) {
return isMember(info, root);
}
/**
* Removes an elememt from the tree.
*/
public void delete(T info) {
delete(info, root);
}
/**
* Returns a text representation of the tree.
*/
public String toString() {
return inOrder();
}
/**
* Returns all elements of the tree in in-order traversing.
*/
public String inOrder() {
return inOrder(root);
}
/**
* Returns all elements of the tree in pre-order traversing.
*/
public String preOrder() {
return preOrder(root);
}
/**
* Returns all elements of the tree in post-order traversing.
*/
public String postOrder() {
return postOrder(root);
}
/**
* Returns the height of the tree.
*/
public int getHeight() {
return getHeight(root);
}
private void insert(T info, Node node, Node parent, boolean right) {
if (node == null) {
if (parent == null) {
root = node = new Node(info, parent);
} else if (right) {
parent.right = node = new Node(info, parent);
} else {
parent.left = node = new Node(info, parent);
}
restructInsert(node, false);
} else if (info.compareTo(node.information) == 0) {
node.information = info;
} else if (info.compareTo(node.information) > 0) {
insert(info, node.right, node, true);
} else {
insert(info, node.left, node, false);
}
}
private boolean isMember(T info, Node node) {
boolean member = false;
if (node == null) {
member = false;
} else if (info.compareTo(node.information) == 0) {
member = true;
} else if (info.compareTo(node.information) > 0) {
member = isMember(info, node.right);
} else {
member = isMember(info, node.left);
}
return member;
}
private void delete(T info, Node node) throws NoSuchElementException {
if (node == null) {
throw new NoSuchElementException();
} else if (info.compareTo(node.information) == 0) {
deleteNode(node);
} else if (info.compareTo(node.information) > 0) {
delete(info, node.right);
} else {
delete(info, node.left);
}
}
private void deleteNode(Node node) {
Node eNode, minMaxNode, delNode = null;
boolean rightNode = false;
if (node.isLeaf()) {
if (node.parent == null) {
root = null;
} else if (node.isRightNode()) {
node.parent.right = null;
rightNode = true;
} else if (node.isLeftNode()) {
node.parent.left = null;
}
delNode = node;
} else if (node.hasLeftNode()) {
minMaxNode = node.left;
for (eNode = node.left; eNode != null; eNode = eNode.right) {
minMaxNode = eNode;
}
delNode = minMaxNode;
node.information = minMaxNode.information;
if (node.left.right != null) {
minMaxNode.parent.right = minMaxNode.left;
rightNode = true;
} else {
minMaxNode.parent.left = minMaxNode.left;
}
if (minMaxNode.left != null) {
minMaxNode.left.parent = minMaxNode.parent;
}
} else if (node.hasRightNode()) {
minMaxNode = node.right;
delNode = minMaxNode;
rightNode = true;
node.information = minMaxNode.information;
node.right = minMaxNode.right;
if (node.right != null) {
node.right.parent = node;
}
node.left = minMaxNode.left;
if (node.left != null) {
node.left.parent = node;
}
}
restructDelete(delNode.parent, rightNode);
}
private int getHeight(Node node) {
int height = 0;
if (node == null) {
height = -1;
} else {
height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
}
return height;
}
private String inOrder(Node node) {
String result = "";
if (node != null) {
result = result + inOrder(node.left) + " ";
result = result + node.information.toString();
result = result + inOrder(node.right);
}
return result;
}
private String preOrder(Node node) {
String result = "";
if (node != null) {
result = result + node.information.toString() + " ";
result = result + preOrder(node.left);
result = result + preOrder(node.right);
}
return result;
}
private String postOrder(Node node) {
String result = "";
if (node != null) {
result = result + postOrder(node.left);
result = result + postOrder(node.right);
result = result + node.information.toString() + " ";
}
return result;
}
private void restructInsert(Node node, boolean wasRight) {
if (node != root) {
if (node.parent.balance == '_') {
if (node.isLeftNode()) {
node.parent.balance = '/';
restructInsert(node.parent, false);
} else {
node.parent.balance = '\\';
restructInsert(node.parent, true);
}
} else if (node.parent.balance == '/') {
if (node.isRightNode()) {
node.parent.balance = '_';
} else {
if (!wasRight) {
rotateRight(node.parent);
} else {
doubleRotateRight(node.parent);
}
}
} else if (node.parent.balance == '\\') {
if (node.isLeftNode()) {
node.parent.balance = '_';
} else {
if (wasRight) {
rotateLeft(node.parent);
} else {
doubleRotateLeft(node.parent);
}
}
}
}
}
private void restructDelete(Node z, boolean wasRight) {
Node parent;
boolean isRight = false;
boolean climb = false;
boolean canClimb;
if (z == null) {
return;
}
parent = z.parent;
canClimb = (parent != null);
if (canClimb) {
isRight = z.isRightNode();
}
if (z.balance == '_') {
if (wasRight) {
z.balance = '/';
} else {
z.balance = '\\';
}
} else if (z.balance == '/') {
if (wasRight) {
if (z.left.balance == '\\') {
doubleRotateRight(z);
climb = true;
} else {
rotateRight(z);
if (z.balance == '_') {
climb = true;
}
}
} else {
z.balance = '_';
climb = true;
}
} else {
if (wasRight) {
z.balance = '_';
climb = true;
} else {
if (z.right.balance == '/') {
doubleRotateLeft(z);
climb = true;
} else {
rotateLeft(z);
if (z.balance == '_') {
climb = true;
}
}
}
}
if (canClimb && climb) {
restructDelete(parent, isRight);
}
}
private void rotateLeft(Node a) {
Node b = a.right;
if (a.parent == null) {
root = b;
} else {
if (a.isLeftNode()) {
a.parent.left = b;
} else {
a.parent.right = b;
}
}
a.right = b.left;
if (a.right != null) {
a.right.parent = a;
}
b.parent = a.parent;
a.parent = b;
b.left = a;
if (b.balance == '_') {
a.balance = '\\';
b.balance = '/';
} else {
a.balance = '_';
b.balance = '_';
}
}
private void rotateRight(Node a) {
Node b = a.left;
if (a.parent == null) {
root = b;
} else {
if (a.isLeftNode()) {
a.parent.left = b;
} else {
a.parent.right = b;
}
}
a.left = b.right;
if (a.left != null) {
a.left.parent = a;
}
b.parent = a.parent;
a.parent = b;
b.right = a;
if (b.balance == '_') {
a.balance = '/';
b.balance = '\\';
} else {
a.balance = '_';
b.balance = '_';
}
}
private void doubleRotateLeft(Node a) {
Node b = a.right;
Node c = b.left;
if (a.parent == null) {
root = c;
} else {
if (a.isLeftNode()) {
a.parent.left = c;
} else {
a.parent.right = c;
}
}
c.parent = a.parent;
a.right = c.left;
if (a.right != null) {
a.right.parent = a;
}
b.left = c.right;
if (b.left != null) {
b.left.parent = b;
}
c.left = a;
c.right = b;
a.parent = c;
b.parent = c;
if (c.balance == '/') {
a.balance = '_';
b.balance = '\\';
} else if (c.balance == '\\') {
a.balance = '/';
b.balance = '_';
} else {
a.balance = '_';
b.balance = '_';
}
c.balance = '_';
}
private void doubleRotateRight(Node a) {
Node b = a.left;
Node c = b.right;
if (a.parent == null) {
root = c;
} else {
if (a.isLeftNode()) {
a.parent.left = c;
} else {
a.parent.right = c;
}
}
c.parent = a.parent;
a.left = c.right;
if (a.left != null) {
a.left.parent = a;
}
b.right = c.left;
if (b.right != null) {
b.right.parent = b;
}
c.right = a;
c.left = b;
a.parent = c;
b.parent = c;
if (c.balance == '/') {
b.balance = '_';
a.balance = '\\';
} else if (c.balance == '\\') {
b.balance = '/';
a.balance = '_';
} else {
b.balance = '_';
a.balance = '_';
}
c.balance = '_';
}
class Node {
T information;
Node parent;
Node left;
Node right;
char balance;
public Node(T information, Node parent) {
this.information = information;
this.parent = parent;
this.left = null;
this.right = null;
this.balance = '_';
}
boolean isLeaf() {
return ((left == null) && (right == null));
}
boolean isNode() {
return !isLeaf();
}
boolean hasLeftNode() {
return (null != left);
}
boolean hasRightNode() {
return (right != null);
}
boolean isLeftNode() {
return (parent.left == this);
}
boolean isRightNode() {
return (parent.right == this);
}
}
} 这两种处理索引的数据结构的不同之处:
1.B树中同一键值不会出现多次,并且它有可能出现在叶结点,也有可能出现在非叶结点中.而B+树的键一定会出现在叶结点中,并且有可能在非叶结点中也有可能重复出现,以维持B+树的平衡.
2.因为B树键位置不定,且在整个树结构中只出现一次,虽然可以节省存储空间,但使得在插入、删除操作复杂度明显增加.B+树相比来说是一种较好的折中.
3.B树的查询效率与键在树中的位置有关,最大时间复杂度与B+树相同(在叶结点的时候),最小时间复杂度为1(在根结点的时候).而B+树的时候复杂度对某建成的树是固定的.
B+树的定义:
1.任意非叶子结点最多有M个子节点;且M>2;
2.除根结点以外的非叶子结点至少有 M/2个子节点;
3.根结点至少有2个子节点;
4.除根节点外每个结点存放至少M/2和至多M个关键字;(至少2个关键字)
5.非叶子结点的子树指针与关键字个数相同;
6.所有结点的关键字:K[1], K[2], …, K[M];且K[i] < K[i+1];
7.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树;
8.所有叶子结点位于同一层;
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
- package com.meidusa.test;
- public interface B {
- public Object get(Comparable key); //查询
- public void remove(Comparable key); //移除
- public void insertOrUpdate(Comparable key, Object obj); //插入或者更新,如果已经存在,就更新,否则插入
- }
- package com.meidusa.test;
- public interface B {
- public Object get(Comparable key); //查询
- public void remove(Comparable key); //移除
- public void insertOrUpdate(Comparable key, Object obj); //插入或者更新,如果已经存在,就更新,否则插入
- }
- package com.meidusa.test;
- import java.util.Random;
- public class BplusTree implements B {
- /** 根节点 */
- protected Node root;
- /** 阶数,M值 */
- protected int order;
- /** 叶子节点的链表头*/
- protected Node head;
- public Node getHead() {
- return head;
- }
- public void setHead(Node head) {
- this.head = head;
- }
- public Node getRoot() {
- return root;
- }
- public void setRoot(Node root) {
- this.root = root;
- }
- public int getOrder() {
- return order;
- }
- public void setOrder(int order) {
- this.order = order;
- }
- @Override
- public Object get(Comparable key) {
- return root.get(key);
- }
- @Override
- public void remove(Comparable key) {
- root.remove(key, this);
- }
- @Override
- public void insertOrUpdate(Comparable key, Object obj) {
- root.insertOrUpdate(key, obj, this);
- }
- public BplusTree(int order){
- if (order < 3) {
- System.out.print("order must be greater than 2");
- System.exit(0);
- }
- this.order = order;
- root = new Node(true, true);
- head = root;
- }
- //测试
- public static void main(String[] args) {
- BplusTree tree = new BplusTree(6);
- Random random = new Random();
- long current = System.currentTimeMillis();
- for (int j = 0; j < 100000; j++) {
- for (int i = 0; i < 100; i++) {
- int randomNumber = random.nextInt(1000);
- tree.insertOrUpdate(randomNumber, randomNumber);
- }
- for (int i = 0; i < 100; i++) {
- int randomNumber = random.nextInt(1000);
- tree.remove(randomNumber);
- }
- }
- long duration = System.currentTimeMillis() - current;
- System.out.println("time elpsed for duration: " + duration);
- int search = 80;
- System.out.print(tree.get(search));
- }
- }
- package com.meidusa.test;
- import java.util.Random;
- public class BplusTree implements B {
- /** 根节点 */
- protected Node root;
- /** 阶数,M值 */
- protected int order;
- /** 叶子节点的链表头*/
- protected Node head;
- public Node getHead() {
- return head;
- }
- public void setHead(Node head) {
- this.head = head;
- }
- public Node getRoot() {
- return root;
- }
- public void setRoot(Node root) {
- this.root = root;
- }
- public int getOrder() {
- return order;
- }
- public void setOrder(int order) {
- this.order = order;
- }
- @Override
- public Object get(Comparable key) {
- return root.get(key);
- }
- @Override
- public void remove(Comparable key) {
- root.remove(key, this);
- }
- @Override
- public void insertOrUpdate(Comparable key, Object obj) {
- root.insertOrUpdate(key, obj, this);
- }
- public BplusTree(int order){
- if (order < 3) {
- System.out.print("order must be greater than 2");
- System.exit(0);
- }
- this.order = order;
- root = new Node(true, true);
- head = root;
- }
- //测试
- public static void main(String[] args) {
- BplusTree tree = new BplusTree(6);
- Random random = new Random();
- long current = System.currentTimeMillis();
- for (int j = 0; j < 100000; j++) {
- for (int i = 0; i < 100; i++) {
- int randomNumber = random.nextInt(1000);
- tree.insertOrUpdate(randomNumber, randomNumber);
- }
- for (int i = 0; i < 100; i++) {
- int randomNumber = random.nextInt(1000);
- tree.remove(randomNumber);
- }
- }
- long duration = System.currentTimeMillis() - current;
- System.out.println("time elpsed for duration: " + duration);
- int search = 80;
- System.out.print(tree.get(search));
- }
- }
- package com.meidusa.test;
- import java.util.AbstractMap.SimpleEntry;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.Map.Entry;
- public class Node {
- /** 是否为叶子节点 */
- protected boolean isLeaf;
- /** 是否为根节点*/
- protected boolean isRoot;
- /** 父节点 */
- protected Node parent;
- /** 叶节点的前节点*/
- protected Node previous;
- /** 叶节点的后节点*/
- protected Node next;
- /** 节点的关键字 */
- protected List
- /** 子节点 */
- protected List
children; - public Node(boolean isLeaf) {
- this.isLeaf = isLeaf;
- entries = new ArrayList
- if (!isLeaf) {
- children = new ArrayList
(); - }
- }
- public Node(boolean isLeaf, boolean isRoot) {
- this(isLeaf);
- this.isRoot = isRoot;
- }
- public Object get(Comparable key) {
- //如果是叶子节点
- if (isLeaf) {
- for (Entry
- if (entry.getKey().compareTo(key) == 0) {
- //返回找到的对象
- return entry.getValue();
- }
- }
- //未找到所要查询的对象
- return null;
- //如果不是叶子节点
- }else {
- //如果key小于等于节点最左边的key,沿第一个子节点继续搜索
- if (key.compareTo(entries.get(0).getKey()) <= 0) {
- return children.get(0).get(key);
- //如果key大于节点最右边的key,沿最后一个子节点继续搜索
- }else if (key.compareTo(entries.get(entries.size()-1).getKey()) >= 0) {
- return children.get(children.size()-1).get(key);
- //否则沿比key大的前一个子节点继续搜索
- }else {
- for (int i = 0; i < entries.size(); i++) {
- if (entries.get(i).getKey().compareTo(key) <= 0 && entries.get(i+1).getKey().compareTo(key) > 0) {
- return children.get(i).get(key);
- }
- }
- }
- }
- return null;
- }
- public void insertOrUpdate(Comparable key, Object obj, BplusTree tree){
- //如果是叶子节点
- if (isLeaf){
- //不需要分裂,直接插入或更新
- if (contains(key) || entries.size() < tree.getOrder()){
- insertOrUpdate(key, obj);
- if (parent != null) {
- //更新父节点
- parent.updateInsert(tree);
- }
- //需要分裂
- }else {
- //分裂成左右两个节点
- Node left = new Node(true);
- Node right = new Node(true);
- //设置链接
- if (previous != null){
- previous.setNext(left);
- left.setPrevious(previous);
- }
- if (next != null) {
- next.setPrevious(right);
- right.setNext(next);
- }
- if (previous == null){
- tree.setHead(left);
- }
- left.setNext(right);
- right.setPrevious(left);
- previous = null;
- next = null;
- //左右两个节点关键字长度
- int leftSize = (tree.getOrder() + 1) / 2 + (tree.getOrder() + 1) % 2;
- int rightSize = (tree.getOrder() + 1) / 2;
- //复制原节点关键字到分裂出来的新节点
- insertOrUpdate(key, obj);
- for (int i = 0; i < leftSize; i++){
- left.getEntries().add(entries.get(i));
- }
- for (int i = 0; i < rightSize; i++){
- right.getEntries().add(entries.get(leftSize + i));
- }
- //如果不是根节点
- if (parent != null) {
- //调整父子节点关系
- int index = parent.getChildren().indexOf(this);
- parent.getChildren().remove(this);
- left.setParent(parent);
- right.setParent(parent);
- parent.getChildren().add(index,left);
- parent.getChildren().add(index + 1, right);
- setEntries(null);
- setChildren(null);
- //父节点插入或更新关键字
- parent.updateInsert(tree);
- setParent(null);
- //如果是根节点
- }else {
- isRoot = false;
- Node parent = new Node(false, true);
- tree.setRoot(parent);
- left.setParent(parent);
- right.setParent(parent);
- parent.getChildren().add(left);
- parent.getChildren().add(right);
- setEntries(null);
- setChildren(null);
- //更新根节点
- parent.updateInsert(tree);
- }
- }
- //如果不是叶子节点
- }else {
- //如果key小于等于节点最左边的key,沿第一个子节点继续搜索
- if (key.compareTo(entries.get(0).getKey()) <= 0) {
- children.get(0).insertOrUpdate(key, obj, tree);
- //如果key大于节点最右边的key,沿最后一个子节点继续搜索
- }else if (key.compareTo(entries.get(entries.size()-1).getKey()) >= 0) {
- children.get(children.size()-1).insertOrUpdate(key, obj, tree);
- //否则沿比key大的前一个子节点继续搜索
- }else {
- for (int i = 0; i < entries.size(); i++) {
- if (entries.get(i).getKey().compareTo(key) <= 0 && entries.get(i+1).getKey().compareTo(key) > 0) {
- children.get(i).insertOrUpdate(key, obj, tree);
- break;
- }
- }
- }
- }
- }
- /** 插入节点后中间节点的更新 */
- protected void updateInsert(BplusTree tree){
- validate(this, tree);
- //如果子节点数超出阶数,则需要分裂该节点
- if (children.size() > tree.getOrder()) {
- //分裂成左右两个节点
- Node left = new Node(false);
- Node right = new Node(false);
- //左右两个节点关键字长度
- int leftSize = (tree.getOrder() + 1) / 2 + (tree.getOrder() + 1) % 2;
- int rightSize = (tree.getOrder() + 1) / 2;
- //复制子节点到分裂出来的新节点,并更新关键字
- for (int i = 0; i < leftSize; i++){
- left.getChildren().add(children.get(i));
- left.getEntries().add(newSimpleEntry(children.get(i).getEntries().get(0).getKey(), null));
- children.get(i).setParent(left);
- }
- for (int i = 0; i < rightSize; i++){
- right.getChildren().add(children.get(leftSize + i));
- right.getEntries().add(new SimpleEntry(children.get(leftSize + i).getEntries().get(0).getKey(), null));
- children.get(leftSize + i).setParent(right);
- }
- //如果不是根节点
- if (parent != null) {
- //调整父子节点关系
- int index = parent.getChildren().indexOf(this);
- parent.getChildren().remove(this);
- left.setParent(parent);
- right.setParent(parent);
- parent.getChildren().add(index,left);
- parent.getChildren().add(index + 1, right);
- setEntries(null);
- setChildren(null);
- //父节点更新关键字
- parent.updateInsert(tree);
- setParent(null);
- //如果是根节点
- }else {
- isRoot = false;
- Node parent = new Node(false, true);
- tree.setRoot(parent);
- left.setParent(parent);
- right.setParent(parent);
- parent.getChildren().add(left);
- parent.getChildren().add(right);
- setEntries(null);
- setChildren(null);
- //更新根节点
- parent.updateInsert(tree);
- }
- }
- }
- /** 调整节点关键字*/
- protected static void validate(Node node, BplusTree tree) {
- // 如果关键字个数与子节点个数相同
- if (node.getEntries().size() == node.getChildren().size()) {
- for (int i = 0; i < node.getEntries().size(); i++) {
- Comparable key = node.getChildren().get(i).getEntries().get(0).getKey();
- if (node.getEntries().get(i).getKey().compareTo(key) != 0) {
- node.getEntries().remove(i);
- node.getEntries().add(i, new SimpleEntry(key, null));
- if(!node.isRoot()){
- validate(node.getParent(), tree);
- }
- }
- }
- // 如果子节点数不等于关键字个数但仍大于M / 2并且小于M,并且大于2
- } else if (node.isRoot() && node.getChildren().size() >= 2
- ||node.getChildren().size() >= tree.getOrder() / 2
- && node.getChildren().size() <= tree.getOrder()
- && node.getChildren().size() >= 2) {
- node.getEntries().clear();
- for (int i = 0; i < node.getChildren().size(); i++) {
- Comparable key = node.getChildren().get(i).getEntries().get(0).getKey();
- node.getEntries().add(new SimpleEntry(key, null));
- if (!node.isRoot()) {
- validate(node.getParent(), tree);
- }
- }
- }
- }
- /** 删除节点后中间节点的更新*/
- protected void updateRemove(BplusTree tree) {
- validate(this, tree);
- // 如果子节点数小于M / 2或者小于2,则需要合并节点
- if (children.size() < tree.getOrder() / 2 || children.size() < 2) {
- if (isRoot) {
- // 如果是根节点并且子节点数大于等于2,OK
- if (children.size() >= 2) {
- return;
- // 否则与子节点合并
- } else {
- Node root = children.get(0);
- tree.setRoot(root);
- root.setParent(null);
- root.setRoot(true);
- setEntries(null);
- setChildren(null);
- }
- } else {
- //计算前后节点
- int currIdx = parent.getChildren().indexOf(this);
- int prevIdx = currIdx - 1;
- int nextIdx = currIdx + 1;
- Node previous = null, next = null;
- if (prevIdx >= 0) {
- previous = parent.getChildren().get(prevIdx);
- }
- if (nextIdx < parent.getChildren().size()) {
- next = parent.getChildren().get(nextIdx);
- }
- // 如果前节点子节点数大于M / 2并且大于2,则从其处借补
- if (previous != null
- && previous.getChildren().size() > tree.getOrder() / 2
- && previous.getChildren().size() > 2) {
- //前叶子节点末尾节点添加到首位
- int idx = previous.getChildren().size() - 1;
- Node borrow = previous.getChildren().get(idx);
- previous.getChildren().remove(idx);
- borrow.setParent(this);
- children.add(0, borrow);
- validate(previous, tree);
- validate(this, tree);
- parent.updateRemove(tree);
- // 如果后节点子节点数大于M / 2并且大于2,则从其处借补
- } else if (next != null
- && next.getChildren().size() > tree.getOrder() / 2
- && next.getChildren().size() > 2) {
- //后叶子节点首位添加到末尾
- Node borrow = next.getChildren().get(0);
- next.getChildren().remove(0);
- borrow.setParent(this);
- children.add(borrow);
- validate(next, tree);
- validate(this, tree);
- parent.updateRemove(tree);
- // 否则需要合并节点
- } else {
- // 同前面节点合并
- if (previous != null
- && (previous.getChildren().size() <= tree.getOrder() / 2 || previous.getChildren().size() <= 2)) {
- for (int i = previous.getChildren().size() - 1; i >= 0; i--) {
- Node child = previous.getChildren().get(i);
- children.add(0, child);
- child.setParent(this);
- }
- previous.setChildren(null);
- previous.setEntries(null);
- previous.setParent(null);
- parent.getChildren().remove(previous);
- validate(this, tree);
- parent.updateRemove(tree);
- // 同后面节点合并
- } else if (next != null
- && (next.getChildren().size() <= tree.getOrder() / 2 || next.getChildren().size() <= 2)) {
- for (int i = 0; i < next.getChildren().size(); i++) {
- Node child = next.getChildren().get(i);
- children.add(child);
- child.setParent(this);
- }
- next.setChildren(null);
- next.setEntries(null);
- next.setParent(null);
- parent.getChildren().remove(next);
- validate(this, tree);
- parent.updateRemove(tree);
- }
- }
- }
- }
- }
- public void remove(Comparable key, BplusTree tree){
- //如果是叶子节点
- if (isLeaf){
- //如果不包含该关键字,则直接返回
- if (!contains(key)){
- return;
- }
- //如果既是叶子节点又是跟节点,直接删除
- if (isRoot) {
- remove(key);
- }else {
- //如果关键字数大于M / 2,直接删除
- if (entries.size() > tree.getOrder() / 2 && entries.size() > 2) {
- remove(key);
- }else {
- //如果自身关键字数小于M / 2,并且前节点关键字数大于M / 2,则从其处借补
- if (previous != null
- && previous.getEntries().size() > tree.getOrder() / 2
- && previous.getEntries().size() > 2
- && previous.getParent() == parent) {
- int size = previous.getEntries().size();
- Entry
- previous.getEntries().remove(entry);
- //添加到首位
- entries.add(0, entry);
- remove(key);
- //如果自身关键字数小于M / 2,并且后节点关键字数大于M / 2,则从其处借补
- }else if (next != null
- && next.getEntries().size() > tree.getOrder() / 2
- && next.getEntries().size() > 2
- && next.getParent() == parent) {
- Entry
- next.getEntries().remove(entry);
- //添加到末尾
- entries.add(entry);
- remove(key);
- //否则需要合并叶子节点
- }else {
- //同前面节点合并
- if (previous != null
- && (previous.getEntries().size() <= tree.getOrder() / 2 || previous.getEntries().size() <= 2)
- && previous.getParent() == parent) {
- for (int i = previous.getEntries().size() - 1; i >=0; i--) {
- //从末尾开始添加到首位
- entries.add(0, previous.getEntries().get(i));
- }
- remove(key);
- previous.setParent(null);
- previous.setEntries(null);
- parent.getChildren().remove(previous);
- //更新链表
- if (previous.getPrevious() != null) {
- Node temp = previous;
- temp.getPrevious().setNext(this);
- previous = temp.getPrevious();
- temp.setPrevious(null);
- temp.setNext(null);
- }else {
- tree.setHead(this);
- previous.setNext(null);
- previous = null;
- }
- //同后面节点合并
- }else if(next != null
- && (next.getEntries().size() <= tree.getOrder() / 2 || next.getEntries().size() <= 2)
- && next.getParent() == parent){
- for (int i = 0; i < next.getEntries().size(); i++) {
- //从首位开始添加到末尾
- entries.add(next.getEntries().get(i));
- }
- remove(key);
- next.setParent(null);
- next.setEntries(null);
- parent.getChildren().remove(next);
- //更新链表
- if (next.getNext() != null) {
- Node temp = next;
- temp.getNext().setPrevious(this);
- next = temp.getNext();
- temp.setPrevious(null);
- temp.setNext(null);
- }else {
- next.setPrevious(null);
- next = null;
- }
- }
- }
- }
- parent.updateRemove(tree);
- }
- //如果不是叶子节点
- }else {
- //如果key小于等于节点最左边的key,沿第一个子节点继续搜索
- if (key.compareTo(entries.get(0).getKey()) <= 0) {
- children.get(0).remove(key, tree);
- //如果key大于节点最右边的key,沿最后一个子节点继续搜索
- }else if (key.compareTo(entries.get(entries.size()-1).getKey()) >= 0) {
- children.get(children.size()-1).remove(key, tree);
- //否则沿比key大的前一个子节点继续搜索
- }else {
- for (int i = 0; i < entries.size(); i++) {
- if (entries.get(i).getKey().compareTo(key) <= 0 && entries.get(i+1).getKey().compareTo(key) > 0) {
- children.get(i).remove(key, tree);
- break;
- }
- }
- }
- }
- }
- /** 判断当前节点是否包含该关键字*/
- protected boolean contains(Comparable key) {
- for (Entry
- if (entry.getKey().compareTo(key) == 0) {
- return true;
- }
- }
- return false;
- }
- /** 插入到当前节点的关键字中*/
- protected void insertOrUpdate(Comparable key, Object obj){
- Entry
- //如果关键字列表长度为0,则直接插入
- if (entries.size() == 0) {
- entries.add(entry);
- return;
- }
- //否则遍历列表
- for (int i = 0; i < entries.size(); i++) {
- //如果该关键字键值已存在,则更新
- if (entries.get(i).getKey().compareTo(key) == 0) {
- entries.get(i).setValue(obj);
- return;
- //否则插入
- }else if (entries.get(i).getKey().compareTo(key) > 0){
- //插入到链首
- if (i == 0) {
- entries.add(0, entry);
- return;
- //插入到中间
- }else {
- entries.add(i, entry);
- return;
- }
- }
- }
- //插入到末尾
- entries.add(entries.size(), entry);
- }
- /** 删除节点*/
- protected void remove(Comparable key){
- int index = -1;
- for (int i = 0; i < entries.size(); i++) {
- if (entries.get(i).getKey().compareTo(key) == 0) {
- index = i;
- break;
- }
- }
- if (index != -1) {
- entries.remove(index);
- }
- }
- public Node getPrevious() {
- return previous;
- }
- public void setPrevious(Node previous) {
- this.previous = previous;
- }
- public Node getNext() {
- return next;
- }
- public void setNext(Node next) {
- this.next = next;
- }
- public boolean isLeaf() {
- return isLeaf;
- }
- public void setLeaf(boolean isLeaf) {
- this.isLeaf = isLeaf;
- }
- public Node getParent() {
- return parent;
- }
- public void setParent(Node parent) {
- this.parent = parent;
- }
- public List
- return entries;
- }
- public void setEntries(List
- this.entries = entries;
- }
- public List
getChildren() { - return children;
- }
- public void setChildren(List
children) { - this.children = children;
- }
- public boolean isRoot() {
- return isRoot;
- }
- public void setRoot(boolean isRoot) {
- this.isRoot = isRoot;
- }
- public String toString(){
- StringBuilder sb = new StringBuilder();
- sb.append("isRoot: ");
- sb.append(isRoot);
- sb.append(", ");
- sb.append("isLeaf: ");
- sb.append(isLeaf);
- sb.append(", ");
- sb.append("keys: ");
- for (Entry entry : entries){
- sb.append(entry.getKey());
- sb.append(", ");
- }
- sb.append(", ");
- return sb.toString();
- }