Spark Core
一、Spark Core
Apache Spark 是加州大学伯克利分校的 AMP Labs 开发的开源分布式轻量级通用计算框架。由于 Spark 基于内存设计,使得它拥有比 Hadoop 更高的性能(极端情况下可以达到 100x),并且对多语言(Scala、Java、Python)提供支持。其一栈式的设计特点使得我们的学习和维护成本大大地减少,而且其提供了很好的容错解决方案。
操作步骤
1. 主要功能
- Spark Core提供Spark最基础与最核心的功能,主要包括以下功能:
-
(1)、SparkContext:通常而言,Driver Application的执行与输出都是通过SparkContext来完成的。在正式提交Application之前,首先需要初始化SparkContext。SparkContext隐藏了网络通信、分布式部署、消息通信、存储能力、计算能力、缓存、测量系统、文件服务、Web服务等内容,应用程序开发者只需要使用SparkContext提供的API完成功能开发。SparkContext内置的DAGScheduler负责创建Job,将DAG中的RDD划分到不同的Stage,提交Stage等功能。内置的TaskScheduler负责资源的申请,任务的提交及请求集群对任务的调度等工作。
(2)、存储体系:Spark优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘IO,提升了任务执行的效率,使得Spark适用于实时计算、流式计算等场景。此外,Spark还提供了以内存为中心的高容错的分布式文件系统Tachyon供用户进行选择。Tachyon能够为Spark提供可靠的内存级的文件共享服务。
(3)、计算引擎:计算引擎由SparkContext中的DAGScheduler、RDD以及具体节点上的Executor负责执行的Map和Reduce任务组成。DAGScheduler和RDD虽然位于SparkContext内部,但是在任务正式提交与执行之前会将Job中的RDD组织成有向无环图(DAG),并对Stage进行划分,决定了任务执行阶段任务的数量、迭代计算、shuffle等过程。
(4)、部署模式:由于单节点不足以提供足够的存储和计算能力,所以作为大数据处理的Spark在SparkContext的TaskScheduler组件中提供了对Standalone部署模式的实现和Yarn、Mesos等分布式资源管理系统的支持。通过使用Standalone、Yarn、Mesos等部署模式为Task分配计算资源,提高任务的并发执行效率。
2. Spark Core子框架
- Spark的几大子框架包括:
-
(1)、Spark SQL:首先使用SQL语句解析器(SqlParser)将SQL转换为语法树(Tree),并且使用规则执行器(RuleExecutor)将一系列规则(Rule)应用到语法树,最终生成物理执行计划并执行。其中,规则执行器包括语法分析器(Analyzer)和优化器(Optimizer)。
(2)、Spark Streaming:用于流式计算。Spark Streaming支持Kafka、Flume、Twitter、MQTT、ZeroMQ、Kinesis和简单的TCP套接字等多种数据输入源。输入流接收器(Receiver)负责接入数据,是接入数据流的接口规范。Dstream是Spark Streaming中所有数据流的抽象,Dstream可以被组织为Dstream Graph。Dstream本质上由一系列连续的RDD组成。
(3)、GraphX:Spark提供的分布式图计算框架。GraphX主要遵循整体同步并行(bulk Synchronous parallel,BSP)计算模式下的Pregel模型实现。GraphX提供了对图的抽象Graph,Graph由顶点(Vertex),边(Edge)及继承了Edge的EdgeTriplet三种结构组成。GraphX目前已经封装了最短路径,网页排名,连接组件,三角关系统计等算法的实现,用户可以选择使用。
(4)、MLlib:Spark提供的机器学习框架。机器学习是一门设计概率论、统计学、逼近论、凸分析、算法复杂度理论等多领域的交叉学科。MLlib目前已经提供了基础统计、分析、回归、决策树、随机森林、朴素贝叶斯、保序回归、协同过滤、聚类、维数缩减、特征提取与转型、频繁模式挖掘、预言模型标记语言、管道等多种数理统计、概率论、数据挖掘方面的数学算法。
3. Spark架构
Spark采用了分布式计算中的Master-Slave模型。Master作为整个集群的控制器,负责整个集群的正常运行;Worker是计算节点,接受主节点命令以及进行状态汇报;Executor负责任务(Tast)的调度和执行;Client作为用户的客户端负责提交应用;Driver负责控制一个应用的执行。

Spark集群启动时,需要从主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver是应用的逻辑执行起点,运行Application的main函数并创建SparkContext,DAGScheduler把对Job中的RDD有向无环图根据依赖关系划分为多个Stage,每一个Stage是一个TaskSet, TaskScheduler把Task分发给Worker中的Executor;Worker启动Executor,Executor启动线程池用于执行Task。

4. Spark计算模型
RDD:弹性分布式数据集,是一种内存抽象,可以理解为一个大数组,数组的元素是RDD的分区Partition,分布在集群上;在物理数据存储上,RDD的每一个Partition对应的就是一个数据块Block,Block可以存储在内存中,当内存不够时可以存储在磁盘上。
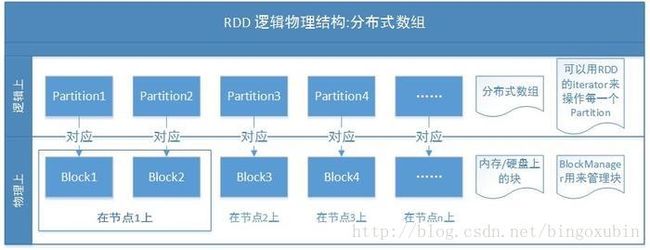
RDD逻辑物理结构
- Hadoop将Mapreduce计算的结果写入磁盘,在机器学习、图计算、PageRank等迭代计算下,重用中间结果导致的反复I/O耗时过长,成为了计算性能的瓶颈。为了提高迭代计算的性能和分布式并行计算下共享数据的容错性,伯克利的设计者依据两个特性而设计了RDD:
-
1、数据集分区存储在节点的内存中,减少迭代过程(如机器学习算法)反复的I/O操作从而提高性能。
2、数据集不可变,并记录其转换过程,从而实现无共享数据读写同步问题、以及出错的可重算性。
Operations:算子
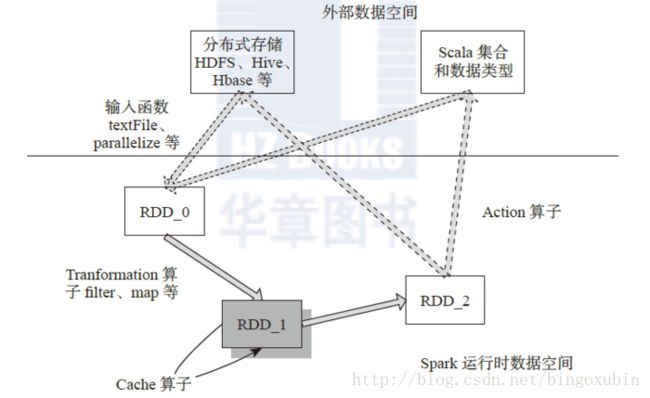
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。如下图,Spark从外部空间(HDFS)读取数据形成RDD_0,Tranformation算子对数据进行操作(如fliter)并转化为新的RDD_1、RDD_2,通过Action算子(如collect/count)触发Spark提交作业。
如上的分析过程可以看出,Tranformation算子并不会触发Spark提交作业,直至Action算子才提交作业,这是一个延迟计算的设计技巧,可以避免内存过快被中间计算占满,从而提高内存的利用率。
下图是算子的列表,分三大类:Value数据类型的Tranformation算子;Key-Value数据类型的Tranformation算子;Action算子。

Lineage Graph:血统关系图
下图的第一阶段生成RDD的有向无环图,即是血统关系图,记录了RDD的更新过程,当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。DAGScheduler依据RDD的依赖关系将有向无环图划分为多个Stage,一个Stage对应着一系列的Task,由TashScheduler分发给Worker计算。

二、组件
1. 介绍
spark生态系统中,Spark Core,包括各种Spark的各种核心组件,它们能够对内存和硬盘进行操作,或者调用CPU进行计算。
spark core定义了RDD、DataFrame和DataSet
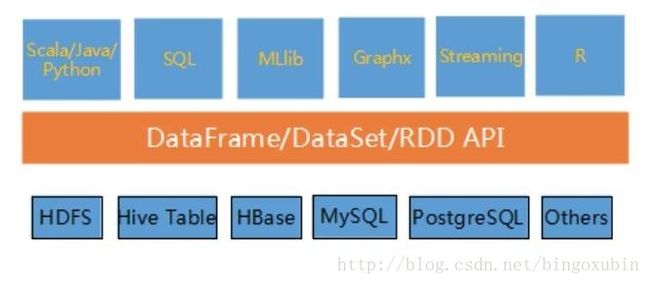
spark最初只有RDD,DataFrame在Spark 1.3中被首次发布,DataSet在Spark1.6版本中被加入。
2. RDD
RDD:Spark的核心概念是RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
- 优点:
-
编译时类型安全
编译时就能检查出类型错误
面向对象的编程风格
直接通过类名点的方式来操作数据 - 缺点:
-
序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化.
GC的性能开销
频繁的创建和销毁对象, 势必会增加GC
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
object Run {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val sqlContext = new SQLContext(sc)
/**
* id age
* 1 30
* 2 29
* 3 21
*/
case class Person(id: Int, age: Int)
val idAgeRDDPerson = sc.parallelize(Array(Person(1, 30), Person(2, 29), Person(3, 21)))
// 优点1
// idAge.filter(_.age > "") // 编译时报错, int不能跟String比
// 优点2
idAgeRDDPerson.filter(_.age > 25) // 直接操作一个个的person对象
}
}
3. DataFrame
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
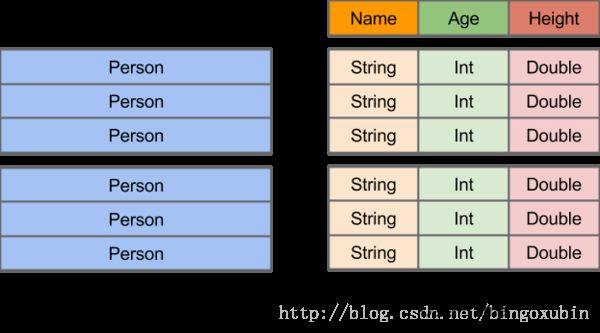
DataFrame引入了schema和off-heap
schema : RDD每一行的数据, 结构都是一样的.
这个结构就存储在schema中。 Spark通过schame就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据,而结构的部分就可以省略了。 off-heap : 意味着JVM堆以外的内存,这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中,当要操作数据时,就直接操作off-heap内存。由于Spark理解schema,所以知道该如何操作。off-heap就像地盘,schema就像地图, Spark有地图又有自己地盘了, 就可以自己说了算了, 不再受JVM的限制,也就不再收GC的困扰了。通过schema和off-heap,DataFrame解决了RDD的缺点,但是却丢了RDD的优点。 DataFrame不是类型安全的, API也不是面向对象风格的。
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object Run {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val sqlContext = new SQLContext(sc)
/**
* id age
* 1 30
* 2 29
* 3 21
*/
val idAgeRDDRow = sc.parallelize(Array(Row(1, 30), Row(2, 29), Row(4, 21)))
val schema = StructType(Array(StructField("id", DataTypes.IntegerType), StructField("age", DataTypes.IntegerType)))
val idAgeDF = sqlContext.createDataFrame(idAgeRDDRow, schema)
// API不是面向对象的
idAgeDF.filter(idAgeDF.col("age") > 25)
// 不会报错, DataFrame不是编译时类型安全的
idAgeDF.filter(idAgeDF.col("age") > "")
}
}
4. DataSet
Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]
Dataset是“懒惰”的,只在执行行动操作时触发计算。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。当执行行动操作时,Spark的查询优化程序优化逻辑计划,并生成一个高效的并行和分布式物理计划。
DataSet结合了RDD和DataFrame的优点,,并带来的一个新的概念Encoder 当序列化数据时,Encoder产生字节码与off-heap进行交互,能够达到按需访问数据的效果, 而不用反序列化整个对象。 Spark还没有提供自定义Encoder的API,但是未来会加入。
下面看DataFrame和DataSet在2.0.0-preview中的实现
下面这段代码, 在1.6.x中创建的是DataFrame
// 上文DataFrame示例中提取出来的
val idAgeRDDRow = sc.parallelize(Array(Row(1, 30), Row(2, 29), Row(4, 21)))
val schema = StructType(Array(StructField("id", DataTypes.IntegerType), StructField("age", DataTypes.IntegerType)))
val idAgeDF = sqlContext.createDataFrame(idAgeRDDRow, schema)
但是同样的代码在2.0.0-preview中, 创建的虽然还叫DataFrame
// sqlContext.createDataFrame(idAgeRDDRow, schema) 方法的实现, 返回值依然是DataFrame
def createDataFrame(rowRDD: RDD[Row], schema: StructType): DataFrame = {
sparkSession.createDataFrame(rowRDD, schema)
}
但是其实却是DataSet, 因为DataFrame被声明为Dataset[Row]
package object sql {
// ...省略了不相关的代码
type DataFrame = Dataset[Row]
}
因此当我们从1.6.x迁移到2.0.0的时候, 无需任何修改就直接用上了DataSet.
下面是一段DataSet的示例代码
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("test").setMaster("local") // 调试的时候一定不要用local[*]
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val idAgeRDDRow = sc.parallelize(Array(Row(1, 30), Row(2, 29), Row(4, 21)))
val schema = StructType(Array(StructField("id", DataTypes.IntegerType), StructField("age", DataTypes.IntegerType)))
// 在2.0.0-preview中这行代码创建出的DataFrame, 其实是DataSet[Row]
val idAgeDS = sqlContext.createDataFrame(idAgeRDDRow, schema)
// 在2.0.0-preview中, 还不支持自定的Encoder, Row类型不行, 自定义的bean也不行
// 官方文档也有写通过bean创建Dataset的例子,但是我运行时并不能成功
// 所以目前需要用创建DataFrame的方法, 来创建DataSet[Row]
// sqlContext.createDataset(idAgeRDDRow)
// 目前支持String, Integer, Long等类型直接创建Dataset
Seq(1, 2, 3).toDS().show()
sqlContext.createDataset(sc.parallelize(Array(1, 2, 3))).show()
}
}
5. RDD和DataFrame比较

DataFrame与RDD相同之处,都是不可变分布式弹性数据集。不同之处在于,DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。
DataFrame的设计是为了让大数据处理起来更容易。DataFrame允许开发者把结构化数据集导入DataFrame,并做了higher-level的抽象; DataFrame提供特定领域的语言(DSL)API来操作你的数据集。上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
6. RDD和DataSet比较
DataSet以Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting、shuffle等操作。
DataSet创立需要一个显式的Encoder,把对象序列化为二进制,可以把对象的scheme映射为Spark SQl类型,然而RDD依赖于运行时反射机制。
通过上面两点,DataSet的性能比RDD的要好很多
7. DataFrame和DataSet比较
- Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
-
1.DataSet可以在编译时检查类型
2.是面向对象的编程接口。用wordcount举例:
3.后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
DataFrame和DataSet可以相互转化, df.as[ElementType]这样可以把DataFrame转化为DataSet,ds.toDF()这样可以把DataSet转化为DataFrame。
//DataFrame
// Load a text file and interpret each line as a java.lang.String
val ds = sqlContext.read.text("/home/spark/1.6/lines").as[String]
val result = ds
.flatMap(_.split(" ")) // Split on whitespace
.filter(_ != "") // Filter empty words
.toDF() // Convert to DataFrame to perform aggregation / sorting
.groupBy($"value") // Count number of occurences of each word
.agg(count("*") as "numOccurances")
.orderBy($"numOccurances" desc) // Show most common words first
//DataSet,完全使用scala编程,不要切换到DataFrame
val wordCount =
ds.flatMap(_.split(" "))
.filter(_ != "")
.groupBy(_.toLowerCase()) // Instead of grouping on a column expression (i.e. $"value") we pass a lambda function
.count()
8. 应用场景
- 什么时候用RDD?使用RDD的一般场景:
-
你需要使用low-level的transformation和action来控制你的数据集;
你得数据集非结构化,比如,流媒体或者文本流;
你想使用函数式编程来操作你得数据,而不是用特定领域语言(DSL)表达;
你不在乎schema,比如,当通过名字或者列处理(或访问)数据属性不在意列式存储格式;
你放弃使用DataFrame和Dataset来优化结构化和半结构化数据集
RDD在Apache Spark 2.0中惨遭抛弃?
答案当然是 NO !
通过后面的描述你会得知:Spark用户可以在RDD,DataFrame和Dataset三种数据集之间无缝转换,而是只需使用超级简单的API方法。 - 什么时候使用DataFrame或者Dataset?
-
你想使用丰富的语义,high-level抽象,和特定领域语言API,那你可DataFrame或者Dataset;
你处理的半结构化数据集需要high-level表达, filter,map,aggregation,average,sum ,SQL 查询,列式访问和使用lambda函数,那你可DataFrame或者Dataset;
你想利用编译时高度的type-safety,Catalyst优化和Tungsten的code生成,那你可DataFrame或者Dataset;
你想统一和简化API使用跨Spark的Library,那你可DataFrame或者Dataset;
如果你是一个R使用者,那你可DataFrame或者Dataset;
如果你是一个Python使用者,那你可DataFrame或者Dataset;
你可以无缝的把DataFrame或者Dataset转化成一个RDD,只需简单的调用 .rdd:
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)