volatile关键字的底层原理
一、volatile的官方定义
Java语言规范第三版中对volatile的定义如下:Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供了Volatile,在某些情况比synchronized更方便。如果一个变量被声明为volatile的,java内存模型确保所有线程看到这个变量的值是一致的。
二、volatile的作用
2.1从java内存模型解释下可见性
在 JDK1.2 之前,Java的内存模型实现总是从主存(即共享内存)读取变量,是不需要进行特别的注意的。
而在当前的 Java 内存模型下,线程可以把变量保存本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。线程在获取锁后可以在自己的工作内存中操作共享变量,操作完成之后将工作内存中的副本回写到主内存。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。
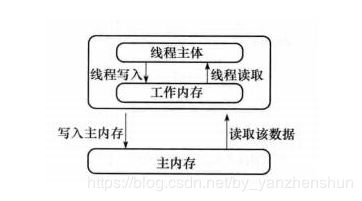
要解决这个问题,就需要把变量声明为volatile,这就指示 JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。
2.2防止指令重排
2.2.1 .什么是指令重排
指令重排是指JVM在编译代码的时候,或者CPU在执行字节码文件时,为了在不改变程序执行结果的前提下,提高程序执行的性能,编译器和执行器(处理器)通常会对指令做一些优化(重排序)。
例:
① ini a = 3;
② int b = 3;
③ int c = a * b;
从例子中可以看出,③的计算依赖于步骤①与②的赋值过程,但是步骤①和步骤②没有依赖关系。
as-if-serial语义是指:不管如何重排序(编译器与处理器为了提高并行度),(单线程)程序的结果不能被改变。这是编译器、Runtime、处理器必须遵守的语义。
所以在单线程的时候,可以① ->happensbefore ->②,②->happensbefore ->③,但是计算①②③和②①③,对最后③****的结果没有影响,所以JVM在编译或者cpu执行字节码文件的时候,可以根据情况进行指令重排。
2.2.2. 指令重排的时机
- 编译器重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
- 处理器(运行时)重排序。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
2.2.3. 指令重排带来的问题
例子1:A指令重排导致B出错
boolean inited = false
线程A:
context = loadContext();
inited = true;
线程B:
while(!inited ){ //根据线程A中对inited变量的修改决定是否使用context变量
sleep(100);
}
doSomethingwithconfig(context);
假设线程A中发生了指令重排序:
inited = true;
context = loadContext();
那么B中很可能就会拿到一个尚未初始化或尚未初始化完成的context,从而引发程序错误。
例子2:用懒加载+double check实现单例模式
public class Singleton {
private static instance = null;
private Singleton() { }
private static Singleton getSingleton() {
if(instance == null) {
synchronized(Singleton.class){
if(instance == null) {
instance = new Singleton*(}
}
}
return instance;
}
}
看似简单的一段赋值语句:instance= new Singleton(),但是很不幸它并不是一个原子操作,其实际上可以抽象为下面几条JVM指令:
memory =allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance =memory; //3:设置instance指向刚分配的内存地址
上面操作2依赖于操作1,但是操作3并不依赖于操作2,所以JVM是可以针对它们进行指令的优化重排序的,经过重排序后如下:
memory =allocate(); //1:分配对象的内存空间
instance =memory; //3:instance指向刚分配的内存地址,此时对象还未初始化
ctorInstance(memory); //2:初始化对象
可以看到指令重排之后,instance指向分配好的内存放在了前面,而这段内存的初始化被排在了后面。
在线程A执行这段赋值语句,在初始化分配对象之前就已经将其赋值给instance引用,恰好另一个线程进入方法判断instance引用不为null,然后就将其返回使用,导致出错。
2.2.4 防止指令重排
volatile关键字通过提供“内存屏障”的方式来防止指令被重排序,为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
(1) 什么是内存屏障
内存屏障也称为内存栅栏或栅栏指令,是一种屏障指令,它使CPU或编译器对屏障指令之前和之后发出的内存操作执行一个排序约束。 这通常意味着在屏障之前发布的操作被保证在屏障之后发布的操作之前执行。
(1) 内存屏障共分为四种类型:
①LoadLoad屏障:
抽象场景:Load1; LoadLoad; Load2
Load1 和 Load2 代表两条读取指令。在Load2要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
②StoreStore屏障:
抽象场景:Store1; StoreStore; Store2
Store1 和 Store2代表两条写入指令。在Store2写入执行前,保证Store1的写入操作对其它处理器可见
LoadStore屏障:
③抽象场景:Load1; LoadStore; Store2
在Store2被写入前,保证Load1要读取的数据被读取完毕。
④StoreLoad屏障:
抽象场景:Store1; StoreLoad; Load2
在Load2读取操作执行前,保证Store1的写入对所有处理器可见。StoreLoad屏障的开销是四种屏障中最大的。
volatile做了什么?
在一个变量被volatile修饰后,JVM会为我们做两件事:
1.在每个volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障。
2.在每个volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障。
或许这样说有些抽象,我们看一看刚才线程A代码的例子:
boolean contextReady = false;
在线程A中执行:
context = loadContext();
contextReady = true;
我们给contextReady 增加volatile修饰符,会带来什么效果呢?

由于加入了StoreStore屏障,屏障上方的普通写入语句 context = loadContext() 和屏障下方的volatile写入语句 contextReady = true 无法交换顺序,从而成功阻止了指令重排序。

三、volatile和synchronized的区别
- volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
- 多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
- volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
- volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性
四、volatiled的使用场景
happen-before的第三条规则提到“volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作”,也就是说;一个volatile变量的写操作对后续对读操作可见。说白了就是每次写完volatile变量,都会将值从工作内存写回到主存中去,每次读取volatile变量,工作内存必须从主存中刷新下自己的值。如此的话,volatile就是为了解决多个线程共享数据的可见性问题。但是不是任何数据共享场景都可以使用volatile,必须满足以下两种情景才行。
1.多个线程不依赖原值的情况下进行读写操作
2.一个线程依赖原值进行写操作,多个线程进行读操作
在我看来,除了这两种情况外,无非是多个线程依赖原值进行运算,这样子倒不是说volatile可见性不起作用了,而是无法保证读取原值和运算是一个原子操作!举个简单的例子,多个线程执行i++;i是一个共享变量,由于读取i的值和i自增不是一个原子操作,所以i最终会丢失掉一部分自增过程。代码如下,最终i输出的结果是一个小于1000的整数。
/**
* Created by chenqimiao on 17/8/23.
*/
public class Testv {
public static volatile int i = 0;
public static void main(String args[]){
for (int i =0;i<1000;i++){
new Thread(){
public void run(){
Thread.yield();
Testv.i++;
}
}.start();
}
System.out.println(Testv.i);
}
}
要满足以上这种需求,我们还必须赋予代码原子性,最常用的肯定是锁操作了,一个字稳,性能可观,同时保证原子性和可见性。如果想操作一波的话,还可以考虑使用一些无锁操作,如CAS,象java.util.concurrent包下的一些原子类就是利用了CAS来做到原子性,但原子性并不能保证可见性,这个时候,还需要配合volatile