游戏引擎多线程
最 近一直在做项目优化,可是由于项目引擎历史原因,不能去砍掉某些功能而去优化项目,项目开发到这种程度,只能在这个基础上去提升整个引擎的效率,常规的 CPU和GPU上的优化(美术资源上的缩减,CPU上耗费地方和GPU耗费地方的优化等)基本上都做了。当然每个人都希望自己的游戏跑的越快越好,现在大 部分机器都已经至少是双核的,如果能发挥多核优势,游戏的速度会大幅提升。
这里只是谈游戏引擎的多线程,至于游戏逻辑和游戏引擎这面关联不大。
游戏中大部分线程一个是用来每帧更新,一个是资源加载。资源加载本文不谈,但下面设计的多线程架构会考虑多线程加载的情况,让多线程加载无缝对接。
多线程模型下 面一共想了2种多线程框架,这2种都不是那种无休止的那种让每个线程都疯狂的运行,这样处理起来会有很多棘手的问题,为了简化问题,需要每帧都去同步一次 这些线程,这样在提升效率的同时也简化问题的复杂程度(其实这2种模型原理基本一样,实现细节不同,因为一个是渲染,一个是纯引擎更新)。
游戏引擎一把流程分成下面这几部:
流程1.游戏物体的update
流程2.Cull阶段,这个阶段包括相机对物体的裁剪
流程3.对可见物体的渲染分类
流程4.那些可见并且依赖相机更新的物体进行更新。
流程5.渲染
可能不同游戏引擎流程处理和上面不太一样,但大多数都差不多。
这里面每一个过程都是相互依赖的,上一个流程输出,是下一个流程输入,一般只要是相互依赖的,要想做多线程处理,每一帧去同步的话,都要有2个 buffer,上一个流程用一个buffer把上一帧的结果记录下来,下一个流程去取另一个buffer进行出来,然后帧末或者帧前交换2个 buffer。如果每个流程都去这么做,随着流程越多,本来是延迟一帧的做法,随着流程的增多,会延迟很多帧,并且,好多东西都是不固定的,buffer 来存放也是很棘手的问题。
现在为了避免这些问题,提出2种多线程模型,虽然不能让每个流程去多线程出来,但也可以尽量发挥多个CPU的能力,总之比单一线程来跑还是快的。
模型1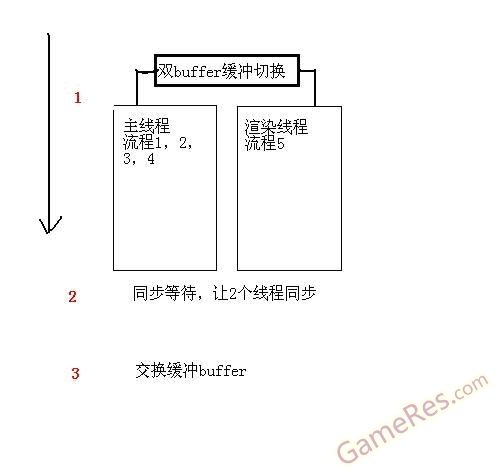
模型1的机制其实很简单,把渲染部分单独拿出来,但由于渲染部分和上面流程是相互依赖的,这个时候必须用双缓冲buffer,做延后一帧处理。也就是上面 说过的,一个buffer是给主线程用来填充的渲染数据,另一个是用来给渲染线程来渲染的,然后再步骤2的时候同步2个线程
模型2

模型2比模型1的改进就是把流程1分解成多个线程处理,一般游戏里比较消耗的更新就是骨骼动画和粒子的更新。如果更新是没有依赖关系的,就可以把它放到一 个单独线程里来出来,如果update m 和update n 有依赖关系,但update m 和update n的集合和其他没有依赖关系,那么就 把他们放到一个里面去更新。要把这个划分出来除了设计上就要考虑最小依赖,还要去考虑依赖程序,才能准确划分。
举个例子,有些粒子是绑定到骨头上的,骨头的更新后才能粒子更新,因为粒子要跟随的,如果再无其他更新依赖那么就可以把它们弄到一个线程去。有些粒子不绑定到骨头上,而且这样就可以把它弄到一个线程去。
游戏世界中每一个Actor的更新保持独立性,这种独立性是需要制约的,因为我们很难保证Actor的独立性,要保证独立性并不是太难,需要做一些额外的工作。
我举个例子比如,场景 中有2个物体,一个游乐场里面的旋转木马和一个人,默认情况下,人不在车上,并且旋转木马还在转,人的更新和木马的更新是毫无依赖关系的,他们每一个都可 以单独放到一个线程去更新。这个时候如果人上了旋转木马,人就要跟随着旋转木马来动,简单的只是位置变,复杂的可能人被绑定到旋转木马的骨头上,跟着骨头 走。这个时候你就不能把他们分别放到一个线程去更新,你要把他们放到同一个线程去更新,把他们看做一个整体。
一般情况下,每个 Actor只是逻辑数据,它的实际渲染数据作为一个node封装在Actor里面,因为我们考虑的是引擎的多线程,不考虑逻辑层面,当人和旋转木马独立的 时候,人和旋转木马的node都attach在引擎里的world,而人和旋转木马的actor都在逻辑层面的world,
如果要想很好解决这个 问题,我们就要让直接attach 引擎world 里面 node 都是独立的,那个node 不独立于另一个,则这个node 必须detach 下来,在重新attach 到另一个node上。就刚才的例子,人的node要想上旋转木马,必须从引擎world上detach下来,然后再重新attach木马的node上,这 样引擎world只剩下一个旋转木马node,当旋转木马node更新的时候,人的node作为子节点,去更新。这就保证了直接attach 引擎world 里面 node 都是独立的,而逻辑层面还是没有变。
还有一种方法就是,你在更新前,把所有相互依赖的归类,这个相对引擎而言,改动是比较小的,需要添加代码就可以/
还有一种就是把骨骼动画,粒子独立出来。但这种方法,需要考虑的因素可能会很多,粒子和骨头都有可能一个绑在另一个上,谁先更新呢?这个你又要多费劲,去想方设法的改你架构分几种情况,而且有可能还要做帧同步等等,十分麻烦。
其实流程2也可以独立出来做多线程,因为场景里面会有多个相机,把每个相机的更新仍给一个线程,但必须等流程1所有都更新完毕,只需要同步一次即可。然后等所有流程2更新完毕,再同步一次,再去做流程3,4.。
这里只是说了大体架构和方法,其实模型2和渲染是没有关系的,但相对渲染来讲是很简单的,如果渲染多线程处理好了,非渲染上的多线程很好处理,所以这里只给出了原理,没有去实现。
还有实现的时候,对于更新开辟一个线程就可以了,毕竟CPU核心是有限的,你是目的是让你的CPU跑满,而不是让它喘不过气,所以尽量不要用线程池。但如果你更新要用多线程,裁剪又要多线程,他们不可能同时运行,这个时候你就可以设计一个好的线程池,不去浪费线程资源。
在做多线程渲染之前,确实做了好多准备工作。
以前没有做过多线程的 大量的代码,只是些过一些小的DEMO,大学里面学的《操作系统》确实给了最主要帮助,我还清晰记得PV操作是《操作系统》课程的一个核心章节,虽然 windows编程里面有了event概念,但原理其实都是一样的,而且无论是关键区,互斥量,信号量,其实它们都是《操作系统》课程的信号量。再一个要 提的就是“原语”,指的就是在执行过程中是不可以打断的,例如j= i +1这个变成汇编指令根据硬件的不同可能是1条指令,也可能是2条指令(至少要一个add指令 和一个 mov 指令)如果2条以上指令,那么它就是 可以被操作系统打断,它所在线程挂起,这里之所以提及这个,就是因为,有时候,你设计认为它没有被打断,它运行其实不对,其实它是被打断的,如果运行对 了,那是你运气好。
上面只是最基础的东 西,多线程渲染比较复杂在,它和D3D要打交道,自己以前也想过怎么处理各种复杂的情况,上网查过很多资料,也看过别人写的多线程的demo。不得不说, 有些确实可以解决多线程渲染问题,但集成复杂度太高,一种情况做一种处理,这肯定要累死你,还有的只给理论没有任何细节的东西,更别说demo,这种能不 能做成其实都很让人去怀疑。
归类始终是解决问题最好的办法,找到问题相似点,然后统一处理,但这个相似点似乎不是那么难找到。
unreal的出现, 问题有了起色,但只能说起色,因为这种方法好多地方其实都在用,只不过unreal 编码方式和特别,用宏封装了起来,还有一个最重要的方式,它把执行的代码包装到了类成员的成员函数(好多用类似 commad 的多线程,都用函数指针了,其实那种方式很乱,参数都都自己做了一个栈传来传去的)。更更重要的是,它把多线程渲染实现了,而且还用到大型项目里面,这其 实是最有说服力的,因为有时候一个理论提出来,你没有大规模应用,别人肯定会怀疑你的理论,而你一旦实现了,他不会怀疑你的理论而是怀疑自己的脑子了。
Unreal这种方法虽然好,但集成复杂度很高,你需要了解你自己现在引擎很多东西,而且还要考虑线程安全问题,后面我会说道这些问题。
多线程渲染
为了简化问题,不可能 让主线程和渲染线程毫无次序的运行,所以采用帧同步,让他们每帧去同步一次。主线程提交数据,渲染线程处理数据,当然这很容易就想到生产者和消费者的模 式,这种模式需要有数据存放的地方,如果使用一个buffer存放数据,这个buffer的所有操作要用异步处理,防止2个线程同时对它进行操作,主线程 有数据就放到这个buffer中,buffer里面只要有数据渲染线程就不停的处理。还有一种是用2个buffer,一个是主线程提交数据的 buffer,一个是渲染线程处理数据的buffer,每帧结束后,交换2个buffer。使用2个buffer会多一些存储空间,但不会因为异步访问阻 塞任何一个线程运行,而且只要渲染数据资源本身不是需要额外的空间,其实是不会浪费很多存储空间的,而且设计的好坏也会避免这样问题出现。
大体的框架就是:每帧 开始的时候,主线程唤起渲染线程,2个线程一起运行,渲染线程处理完所有数据后会激活用来同步的的event,然后进入无限循环的状态,主线程去wait 这个event,如果渲染线程处理完了所有数据,主线程就不会被wait卡住,如果主线程先提交完数据,就会被wait卡住。一旦主线程通过wait 就挂起渲染线程,然后处理同步信息,包括交换2个buffer等。
接下来是细节问题,这个处理数据buffer要怎么设计。
采用unreal render command 作为buffer的基本成员,把每个要处理的数据封装成命令的形式,实际上就是一个类的实例,根据不同类型的要处理的数据,创建不同的类,然后实例化这个 类,加入这个buffer中。为了简化这个过程,unreal用一系列宏来封装了起来,提升了开发速度。
#define ENQUEUE_RENDER_COMMAND(TypeName,Params) \
{ \
check(IsInGameThread()); \
if(GIsThreadedRendering) \
{ \
FRingBuffer::AllocationContext AllocationContext(GRenderCommandBuffer,sizeof(TypeName)); \
if(AllocationContext.GetAllocatedSize()< sizeof(TypeName))\
{ \
check(AllocationContext.GetAllocatedSize()>= sizeof(FSkipRenderCommand));\
new(AllocationContext) FSkipRenderCommand(AllocationContext.GetAllocatedSize());\
AllocationContext.Commit(); \
new(FRingBuffer::AllocationContext(GRenderCommandBuffer,sizeof(TypeName))) TypeNameParams; \
} \
else \
{ \
new(AllocationContext) TypeNameParams; \
} \
} \
else \
{ \
TypeNameTypeName##CommandParams; \
TypeName##Command.Execute();\
} \
}
#define ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER(TypeName,ParamType1,ParamName1,ParamValue1,Code) \
class TypeName : public FRenderCommand \
{ \
public: \
typedef ParamType1 _ParamType1;\
TypeName(const _ParamType1&In##ParamName1):\
ParamName1(In##ParamName1) \
{} \
virtual UINT Execute()\
{ \
Code;\
return sizeof(*this); \
} \
virtual const TCHAR* DescribeCommand() \
{ \
return TEXT( #TypeName); \
} \
private: \
ParamType1 ParamName1; \
}; \
ENQUEUE_RENDER_COMMAND(TypeName,(ParamValue1));
我只列出带一个参数的宏,通过ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER这个名字可以看出来,还有没 有参数的,2个和3个的,其实只需要无参数和1个参数就足够,大多数参数封装到一个结构体里面作为一个整体,当作一个参数。
#defineENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER(TypeName,ParamType1,ParamName1,ParamValue1,Code)
其实把你要用的代码展会后这个宏什么意思一目了然。这个宏是定义了一个类,有一个参数,有个构造函数,同过外部的变量来赋值给里面的类成员变量。Execute() 这个是你要执行的代码,Code这个也是从宏传过来的。
j = j + 1;
ENQUEUE_UNIQUE_RENDER_COMMAND_ONEPARAMETER(Add,int,i,j,i++;)
Class Add : public FRenderCommand
{
public:
typedef int _ParamType1;
Add (const _ParamType1& Ini): :i(Ini)
{
}
virtual UINTExecute()
{
i++;
return sizeof(*this);
}
virtual constTCHAR* DescribeCommand()
{
return TEXT( “Add”);
}
private:
int i;
}
在写宏的时候有一个变量j,在创建实例的时候,这个j就是构造函数的参数。
#define ENQUEUE_RENDER_COMMAND(TypeName,Params) \
这个宏是用来创建这个类的实例,然后把这个实例放入渲染队列,这可以看出这个如果是多线程渲染,则在一个内存空间中来创建这个实例,加入渲染队列,空间大小不够则加大空间爱你,大体意思就是这样,如果不是多线程,则创建完实例直接运行。
这里就出现一个很大的问题,这个东西要怎么使用,什么时候去使用,使用的时候要注意什么。
继续上面的例子ENQUEUE_RENDER_COMMAND(Add,j);我这里就不全展开了,你展开就会得到实例化的代码。
他的本意是把这些要处 理的都扔到渲染线程去计算,先来看看unreal是怎么使用的,你搜索这个宏,可以看到,unreal在这上面的使用貌似没有什么成型的规范,大到整个裁 减渲染,小到一个buffer copy 都被扔到渲染线程,唯一有点共性的就是这些都或多或少,或深或浅的和D3D有些关系,但这么说有点牵强,整个引擎都和D3D有关系,它也整个可以扔到渲染 线程,如果你组织合理的话,确实是可以的,但效率能不能保证是另一个马事。
再看下一个问题,使用这个宏的时候,要让使用者必须对封装的代码及其了解,因为这些要扔到渲染线程,必须要注意,这里面很可能有些数据是要被主线程使用,就可能涉及到线程安全问题,导致出各种诡异的问题。
举一个例子:处理模型 的骨骼问题,在渲染之前,要先更新骨架,把层级数据算好,把蒙皮信息的矩阵都要算好,渲染的时候把蒙皮的矩阵给VERTEX SHADER,这个时候就涉及到线程安全问题,这个存放蒙皮矩阵的地方,你要单独拷贝出来,存放然后让渲染线程来使用,这样才不会有线程安全的问题,保证 渲染的时候这个数据不会被破坏。看看unreal是如何做的,展开它的rendercommand 宏 他的成员变量用来存放这个蒙皮信息矩阵的是一个array,构造实例的时候,会把主线的array传到构造函数,来构造这个rendercommand 实例,可能你一个地方这么用还好,如果大量这么用,数组之间的构造赋值,开辟空间,等这个command执行完后要析构,数组释放等等,这里会牺牲很多速 度
可以看到使用这个东西的时候,存在很多让人纠结的地方,就现在may引擎,你把那里代码扔到渲染线程里面,这个你要思考好多,还要主线线程安全,更改到多线程渲染,按照unreal方式是一个很耗费工程。
好的多线程的设计,应该是在引擎层和D3D层再有一层,这一层让使用引擎处理渲染问题时候去规避这些多线程风险。
这个中间层,封装所有D3D,然后涉及到多线程的问题都在这一层处理,同时让引擎很容易就集成这种效果。
Low level renderCommand,只是相对于highlevel render command 提出的,我把只封装D3D函数并且不涉及其他的都叫做lowlevel render command ,那么其余都叫做high level render command。有些时候我需要一些组合D3D函数来达到效果,比如设置一个rendertarget ,通常调用这个D3D函数的人,不会只调用它,还会先get 当前render target,保存住,然后在end render target 的时候你还要恢复回去,这个时候你要多个D3D函数集合成 来达到。
这样看来unreal 里面基本上都是high level 的,至于D3D资源的创建,主线程创建就可以了,因为采用Low level render Command 你只有创建出来才会调用它,传递给渲染线程(这里还有资源创建和使用多线程问题,后面会详细说明)。
如果只用上面的方法, 集成到引擎中,基本不需要架构修改,只需要添加代码即可,但用Low level render command 不能处理所有问题,就是D3D资源的LOCK问题,这个东西要和引擎层打交道,引擎更新的数据,要传到D3D资源 LOCK的buffer 中,如果想让使用引擎者对于lock是安全的,你就要封装lock 里面再做多线程安全处理。有2种方法
1.lock的时候挂起渲染线程,unlock的时候唤醒渲染线程
2.创建双D3D资源。
无论那种方法,只有资源是动态资源才会出现这种情况,如果开启多线程渲染,并且是动态资源,中间层都能处理。
第一种方法实现最简单,但效率很低,对于粒子等大规模这种lock。当然你可以分类,统一集中一起处理,把所有动态资源都放到一起,这就增加了管理成本,本身挂起渲染线程就已经减少了效率,在这个过程之间,你的渲染线程不会进行任何数据处理,只能等到unlock结束后。
第二种方法封装d3d资源的时候创建双D3D资源,每帧同步交换2个buffer,经验来讲这里占用多处理的存储空间不会是你内存瓶颈,速度还很快。
第一种方法如果把动态资源分类的话,实现起来最简单的,虽然有速度损失,但也比单个线程跑快。分类的话,就需要有一个管理这些资源的系统。
第二种方法需要在封装D3D资源设计上做点考究了,架构上必然要去修改。
速度块,改动小的方法,就是用high level render command,但这打破所有的都有一个中间层来规避线程安全的问题,引擎只需要把lock 相关的代码封装进去就可以。
到现在为止还有一个问 题没有解决,就是render command 线程无关的数据存放问题,unreal是用类成员变量来弄的,上面说过这个确实有很多问题。所以再管理command 同时再去管理一个内存分配问题,这个空间是事先分配好的,不够可以自动增长,无论render command 还是在这个过程中涉及到线程安全的都在这里面分配,每一个处理数据buffer都包含以一个这样的空间。
还是刚才骨骼蒙皮的问题,我可以在当前buffer里面分配空间,封装rendercommand 时候记录和这个空间的所有信息,比如起始地址,结束地址等等。
上面这些基本可以解决所有问题,可以根据你自己引擎需要来改动。怎么样才改动方便。
我除了实现上面几种方 法外,还是实现一种dynamic mesh 的,这个也是一种mesh 它封装了 vb ib 只和模型有关的信息,然后有二个 内存空间,用来存放顶点数据,二个内存空间存放索引数据,说简单点,就是处理多线程时候,D3D资源只有一份,2份内存资源来缓冲的,也是线程帧同步的时 候交换这2个缓冲。这个dynamic mesh 分成4种,1.动态顶点,动态索引的(现在may引擎中的 debug draw 内部实现就是这种类型),2.动态顶点,静态索引(比如morph)3动态顶点无索引的 4静态顶点,动态索引(地形lod 模型lod等) 这4种情况在游戏中都可以用到,不过这几种情况用high level render command 都可以实现,只不过用了这个可以封装出中间层,不用考虑线程安全问题。
实际开发中遇到的问题
实战,理论归理论,实现归实现,在真正实现中,还是遇到大量的问题
1. 首先有几个大方面的,第一就是自己不是多线编程高手,有时候多线程的并发,会有很多预想不到问题,你自己都想不到,有时候单CPU并行运行 不会有问题,多个CPU并发就会出问题。死锁,饥饿,运行不对等是经常出现的。第二,对于这种自己没有经验的编程挑战,没有可以参考单元测试用例 (unreal 那种是大游戏不是demo,所以细节部分有时候很难参考),最好先在小的单元测试上进行,否则直接在当前游戏上进行修改,问题很难跟踪,最后就只能以失败 而告终。现在基本考虑了所有情况,在单元测试里面,即便说考虑到所有情况,也是相对的,在游戏里面出现问题还是有可能,但毕竟风险降低到最低了,所以你的 测试用例尽量要覆盖所有情况。
2再 说细节的方面,刚写完这个测试的时候就出现死锁,退出的时候游戏退不出去,还好,这个时候只是涉及到线程架构问题,没有涉及到内部render command问题,还比较好查。后来用了一个模型,来测试发现了线程架构的一个不同步问题,就因为一行代码写错位置,导致了这个问题。这种问题一般很难 查,要求你对你写代码逻辑十分缜密,那些代码过程另一个线程也是可以在运行的要了如指掌(window 所有 阻塞和唤醒的内核对象,都是可以唤醒多次的,也就是说它里面引用计数是累加的,比如我event 激活它一次,如果你再调用一次激活,实际上你要调用2次reset 才可以,到不激活状态,内部不会判断如果已经是激活状态,让你不激活不作用)。
3封 装render command 问题,大部分封装只要追寻上面的原则是没有问题的,我在封装set render target的时候 出现了一个问题,就是你要先get 当前render target ,然后你再处理其他的,当时写代码的时候 按照单线程处理以为它已经获取到了,实际上只不过是交给了渲染线程队列里面,并没有再这里执行,所以根本就没有获取到。render target D3D debug 调试还给了错误信息,查了出来,depth scitencl buffer 没有给出错误信息,时候来打log比对才发现的。
还有个问题就是处理和视点有关的更新,本来更新和可见就是一个矛盾体,也就是说,更新了它不可见,则下一帧它就不更新,如果它可见了,就更新。这个 时候用high level render command 时候如果考虑不好多线问题 就会出现图像跳变,在单线程可能延后一针没有问题,再多线程下可能就会有问题,例如在做地形LOD的时候,渲染数据可能和要渲染的个数没有匹配上,如果想 差特别大,虽然只是一帧,也会有跳变,所以high level render command是给很高的多线程缜密思维的人用的,但它却是对引擎集成降低难度,真是很难取舍的一个东西。
4最 后一个就是创建D3D设备的时候要用多线程标志,这个我刚开始知道有它,但文档上说它有效率损耗,总觉得这个方案的设计可以规避所有多线程问题,所以不使 用这个标志也可以。这个在我自己家里的机器上测试没问题,可是公司的机器就是死锁,还有奔溃,而且没有堆栈。只怪自己不了解D3D内部怎么实现的了,只能 用这个标志位了。后来发现,问题出现在资源创建和lock的地方,因为资源创建是在主线程创建的,lock是在渲染线程lock,虽然创建和lock不是 同一个资源,但发现同时跑D3D会有问题,创建资源是用的D3D device
接口函数,Lock 资源是用资源的接口函数,本来不应该有什么冲突,可能是D3D里面做什么处理,要访问同一个东西,而导致问题。如果你的资源在渲染线程之前或者同步2个线 程的时候都创建好,就不会有这个问题(事先创建好),但如果你做异步加载把创建资源扔到渲染线程,就可能要多考虑些问题了。我建议,游戏中无论怎么加线 程,主线程还是作为一个中转站的作用,这样可以减少问题复杂程度。总之开了这个标志位会有性能损耗,但只要你创建资源不是始终都在和渲染线程并排的跑,应 该问题不大,即使始终并排跑这种很少性能的减少,却可以规避设计复杂问题,也是值得的。
5还 有一个问题就是一旦主线程资源删除,而渲染线程还在用到这个资源,如果用智能指针去管理,首先智能指针要具备线程安全性,第二,如果渲染线程这个时候 ref为1,这个command执行完后,要析构才能让这个资源删除,否则不析构永远无法删除,这里有个潜在问题,如果资源析构的时候调用了主线程的函数 (例如资源管理中,析构后要从资源管理中删除等),这个时候线程安全性就无法保证,这里就太多不可确定。
所以做一个资源GC功能很有必要,从这个资源ref为1(默认资源管理要保留一份,所以没人用的时候ref是1)的时候开始计时,这个时候没有其他在用, 所以渲染肯定也不可见的,所以就不会进入渲染线程,到一定时间就可以把他GC掉,如果又有其他重新指向这个资源,那么把计时清0.
6.最后一个就是分辨率切换,窗口切换,涉及到的设备丢失问题。这个问题处理就是一旦检测到窗口切换和设备丢失(这个检测都是在主线程来响应的),马上就不要跑主线程的添加render command 和渲染线程,而是把2个缓冲buffer全都清空,去处理设备丢失问题。
代码说明和运行效果说了这么多,对程序员来说,看到代码和实现效果比什么都是重要的,上面提到的问题以及方法,都被我实现过了。
主多线程渲染架构
//如果设备不丢失,这里检测设备丢失,如果丢失先device lost 处理 然后返回false,下一帧在进这个函数后,再做device reset
if(VSRenderer::ms_pRenderer->CooperativeLevel())
{
VSRenderThreadSys::ms_pRenderTreadSys->Begin();//通知渲染线程启动
if (VSSceneManager::ms_pSceneManager)
{
VSSceneManager::ms_pSceneManager->Update(fTime);
}
//下面过程是添加render command
VSRenderer::ms_pRenderer->BeginRendering();
if (VSSceneManager::ms_pSceneManager)
{
VSSceneManager::ms_pSceneManager->Draw(fTime);
}
VSRenderer::ms_pRenderer->EndRendering();
if (VSRenderThreadSys::ms_pRenderTreadSys && VSResourceManager::ms_bRenderThread)
{
VSRenderThreadSys::ms_pRenderTreadSys->ExChange();//同步渲染线程,并交换buffer
}
else
{
//清空所有渲染render command
if (VSRenderThreadSys::ms_pRenderTreadSys)
{
VSRenderThreadSys::ms_pRenderTreadSys->Clear();
}
}
//GC功能
VSResourceManager::GC();
void VSRenderThreadSys::Begin()
{
//设置一个准备填render command buffer
m_RenderThread.SetRender(m_RenderBuffer);
//启动渲染线程
m_RenderThread.Start();
}
//渲染线程运行,只要不触发被迫停止,它就会一直运行下去,如果render command buffer的所有数据都处理完毕,马上提醒主线程,不再等待
void VSRenderThread::Run()
{
while(!IsStopTrigger())
{
if (m_pRenderBuffer)
{
m_pRenderBuffer->Excuce();
m_pRenderBuffer = NULL;
m_Event.Trigger();
}
}
}
void VSRenderThreadSys::ExChange()
{
//主线程等待渲染线程完毕
m_RenderThread.m_Event.Wait();
//挂起渲染线程
m_RenderThread.Suspend();
m_RenderBuffer->Clear();
//交换2个buffer
Swap(m_UpdateBuffer,m_RenderBuffer);
//有些资源有双D3D 资源的 进行多线程的,要交换buffer
for (unsignedint i = 0 ; i < VSBind::ms_DynamicTwoBindArray.GetNum() ;i++)
{
VSBind::ms_DynamicTwoBindArray->ExChange();
}
}
RenderCommand 说明
//这里封装了D3D SetRenderState
bool VSDX9Renderer::SetRenderState(D3DRENDERSTATETYPEState,DWORDValue)
{
struct VSDx9RenderStatePara
{
D3DRENDERSTATETYPE State;
DWORD Value;
};
HRESULT hResult = NULL;
VSDx9RenderStatePara RenderStatePara;
RenderStatePara.State = State;
RenderStatePara.Value = Value;
ENQUEUE_UNIQUE_RENDER_COMMAND_TWOPARAMETER(VSDx9SetRenderStateCommand,
VSDx9RenderStatePara,RenderStatePara,RenderStatePara,LPDIRECT3DDEVICE9,m_pDevice,m_pDevice,
{
HRESULT hResult = NULL;
hResult = m_pDevice->SetRenderState(RenderStatePara.State,RenderStatePara.Value);
VSMAC_ASSERT(!FAILED(hResult));
})
hResult = m_pDevice->SetRenderState(RenderStatePara.State,RenderStatePara.Value);
ENQUEUE_UNIQUE_RENDER_COMMAND_END
VSMAC_ASSERT(!FAILED(hResult));
return !FAILED(hResult);
}
这里的宏和unreal内部实现不太一样,我做修改,基本意思就是如果开启了多线程渲染,则把命令提交到buffer中,如果不是则直接运行。
所以你会看到2个hResult = m_pDevice->SetRenderState(RenderStatePara.State,RenderStatePara.Value);
其实第一个构建render command 的类的 里面运行代码,第二是如果没开启多线程的话直接就运行。
再来看这个宏,你要是仔细读前面unreal的,你就知道里面嵌套了一个宏,只有嵌套的不一样
#define ENQUEUE_RENDER_COMMAND(TypeName,Params)\
if(VSResourceManager::ms_bRenderThread) \
{ \
TypeName * pCommand = (TypeName*)VSRenderThreadSys::ms_pRenderTreadSys->AssignCommand
VS_NEW(pCommand)TypeNameParams; \
} \
else \
{
如果是多线程的话,就构建实例,加入队列,如果不是,则直接运行代码
#define ENQUEUE_UNIQUE_RENDER_COMMAND_END}
再看一个
bool VSDX9Renderer::SetVertexShaderConstant(unsignedint uiStartRegister,void * pDate,
unsignedint RegisterNum,unsigned int uiType)
{
struct VSDx9VertexShaderConstantPara
{
unsigned int uiStartRegister;
void * pDate;
unsigned int RegisterNum;
unsigned int uiType;
};
HRESULT hResult = NULL;
VSDx9VertexShaderConstantPara VertexShaderConstantPara;
VertexShaderConstantPara.uiStartRegister = uiStartRegister;
VertexShaderConstantPara.RegisterNum = RegisterNum;
VertexShaderConstantPara.uiType = uiType;
if (VSResourceManager::ms_bRenderThread)
{
VertexShaderConstantPara.pDate = VSRenderThreadSys::ms_pRenderTreadSys->Assign(uiType,RegisterNum);
VSMemcpy(VertexShaderConstantPara.pDate,pDate,RegisterNum* sizeof(VSREAL)* 4);
}
else
{
VertexShaderConstantPara.pDate = pDate;
}
ENQUEUE_UNIQUE_RENDER_COMMAND_TWOPARAMETER(VSDx9SetVertexShaderConstantCommand,
VSDx9VertexShaderConstantPara,VertexShaderConstantPara,VertexShaderConstantPara,LPDIRECT3DDEVICE9,m_pDevice,m_pDevice,
{
HRESULT hResult = NULL;
if(VertexShaderConstantPara.uiType == VSUserConstant::VT_BOOL)
{
hResult = m_pDevice->SetVertexShaderConstantB(VertexShaderConstantPara.uiStartRegister,(const BOOL*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else if(VertexShaderConstantPara.uiType== VSUserConstant::VT_FLOAT)
{
hResult = m_pDevice->SetVertexShaderConstantF(VertexShaderConstantPara.uiStartRegister,(const float*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else if(VertexShaderConstantPara.uiType== VSUserConstant::VT_INT)
{
hResult = m_pDevice->SetVertexShaderConstantI(VertexShaderConstantPara.uiStartRegister,(const int*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else
{
VSMAC_ASSERT(0);
}
})
if(VertexShaderConstantPara.uiType == VSUserConstant::VT_BOOL)
{
hResult = m_pDevice->SetVertexShaderConstantB(VertexShaderConstantPara.uiStartRegister,(const BOOL*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else if(VertexShaderConstantPara.uiType== VSUserConstant::VT_FLOAT)
{
hResult = m_pDevice->SetVertexShaderConstantF(VertexShaderConstantPara.uiStartRegister,(const float*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else if(VertexShaderConstantPara.uiType== VSUserConstant::VT_INT)
{
hResult = m_pDevice->SetVertexShaderConstantI(VertexShaderConstantPara.uiStartRegister,(const int*)VertexShaderConstantPara.pDate,VertexShaderConstantPara.RegisterNum);
VSMAC_ASSERT(!FAILED(hResult));
}
else
{
VSMAC_ASSERT(0);
}
ENQUEUE_UNIQUE_RENDER_COMMAND_END
VSMAC_ASSERT(!FAILED(hResult));
return !FAILED(hResult);
return 1;
}
这个封装了D3D 设置vshader的函数,参数也是在buffer里面分配的,这里记录了,分配的地址和长度。
运行效果
这里运行了2个 CLOD 地形,一个是用四叉树地形,一个是ROAM地形,还有个25个带骨骼的,带diffuse normal specular贴图的模型,用了双视口,加了一个黑白的后期处理效果。
画骨骼模型是为了展示基本的lowlevel render command ,四叉树地形用的是high level render command,ROAM地形用的是双D3D index buffer 切换的,画骨头的那个是用的我提到的dynamic mesh 。

把后期去掉
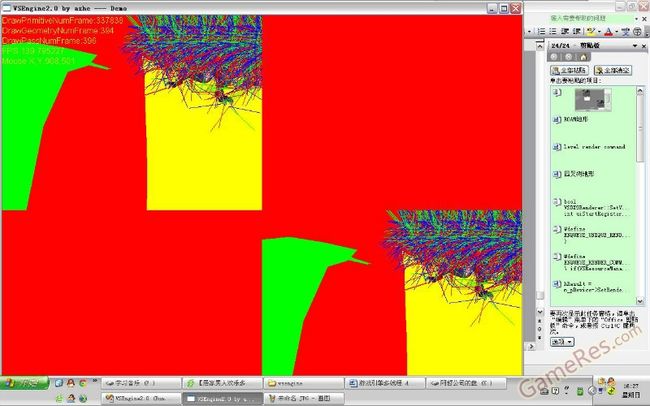
把讨厌的画骨头去掉
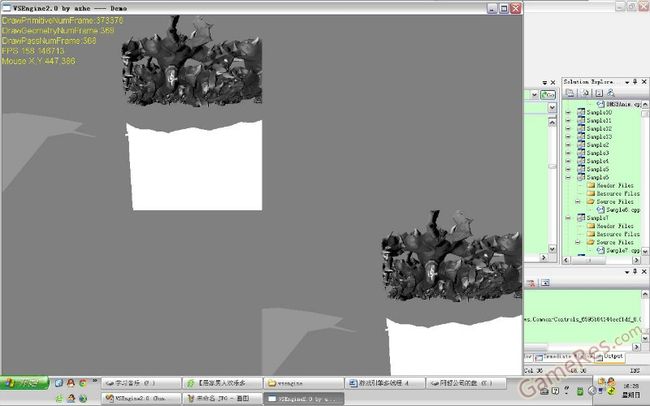
去掉后期

来个线框模式

专门看看四叉树地形lod
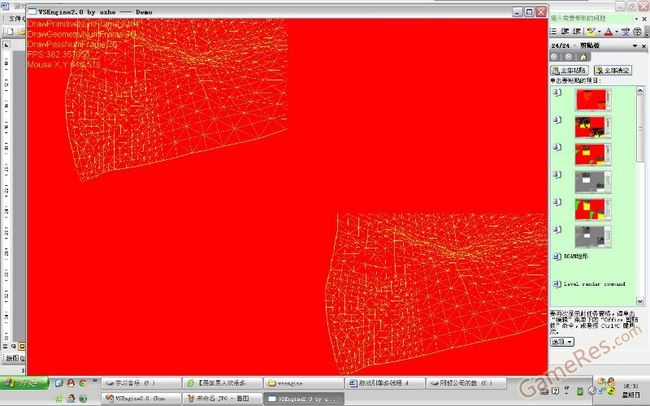
ROAM 地形lod
切换个分辨率
