自研DCI网络路由交换协议DCIP-白牌交换机时代的企业网络
一转眼从听华为3Com的路由交换课程到现在已经13年有余了,依稀记得第一节课的时候我带着老婆去听的课(老婆是日语系的,那时还是女朋友,并不懂网络,只是跟着我去上课的),抢了个头排,讲师宋岩老师提问了一个问题:“为什么要学习网络?”然后看没人回答就要点名,可能是宋老师对漂亮的女生感兴趣吧,直接点名了我老婆...然后就尴尬了,不过没想到老婆回答的还真不错。自那以后,我也就开始了对网络的兴趣,对网络设备的兴趣,路由和交换这门课总体学的还不错。不过,后来我成了程序员,也就没有机会去触摸那些设备了,也算是遗憾。
我深深知道程序员和网管之间有个鸿沟,但我就是无法填掉它,有时这道鸿沟就在我自己的心里。如今,我依然是个程序员,以往我一向喜欢说自己是比较懂网络但是编程编的不好的程序员,以此展示一下我心中的那道鸿沟,SDN的时代来临,软件定义网络,那道鸿沟可以填补了,网络不再是网管的专利,而是程序员编码的一个程序。
在《 网络虚拟化(SDN,NFV..)和企业骨干网的演化》一文中,我的观点比较原始且传统,我描述的企业骨干网是一个AS,通过IGP互联,比如OSPF,这显得企业骨干就是一个IP骨干网。但是,事实上真有这个必要在企业网部署IGP吗?我们看一下企业骨干网的典型结构:
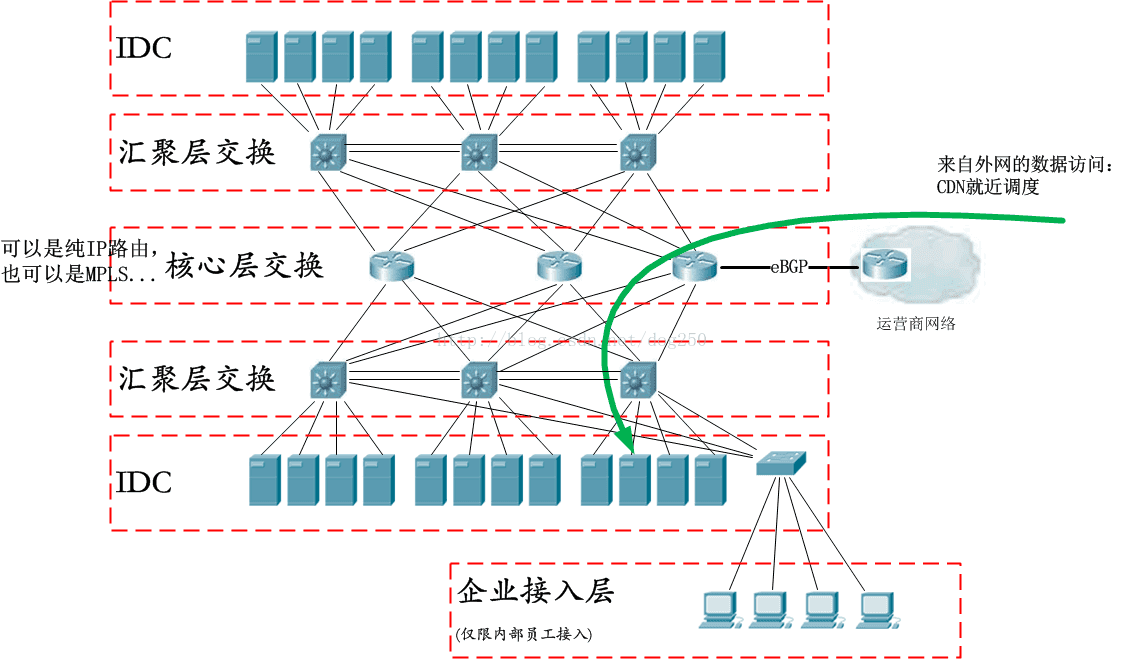
企业骨干网特别是互联网公司的骨干网其实更大意义上是一个数据网而不是一个通信网。它的目的是数据的调度,而不是让不同的节点互联互通,这是企业骨干网与运营商骨干网的很重要的区别。
基于这个区别,我们便可以优化企业网的路由系统了。
仔细观察企业网的层级结构,就会发现它是一个基于胖树的典型CLOS交换结构,之所以可以规划成这种规则的结构,源自于以下的事实:
1.企业网互联的节点一般都是数据中心而不是接入点,而数据本来就是分层的;
2.企业的数据中心可以自己规划的,节点固定,稳定。
所以说,完全没必要在这些数据中心之间运行OSPF这类路由协议,而应该将企业网做成真正交换型的网络。
我来给出一个拍脑袋想出来的简单的”交换协议“来替代复杂的IGP路由协议为企业骨干网打通脉络,在给出这个协议之前,我得先来解释一下路由和交换的区别。在我这里,路由指的是需要复杂计算的寻路过程,主要包括两方面的计算开销,一方面是动态路由协议的计算开销(如果你是静态配置的路由,那么这部分开销由你的脑力替代),另一方面是为数据包查找路由表的开销,这部分计算主要消耗在最长前缀匹配中。现在看看什么是交换,交换在我这里指的是一个转发动作,这个动作的计算开销必须尽可能的小,比如只需要固定几步这种,像CPU的MMU执行的那种转换操作那样,所以交换应该非常容易用硬件实现,在交换网络中,数据的转发动作开销是极小且固定的,基本不需要进行运算,而这些固定的步骤是如何做到数据的正确转发的呢?交换机怎么知道数据包该转往那个端口呢?转发信息来源于两种机制,一种机制是交换机自己学习,另外一种是依靠路由表来生成。
如果转发交换表是路由表生成的,那么这种设备可以看作是高端路由器,交换表便可视为路由表项的Cache,依照这种方式设计出来的硬件早就不知道跑了多少年了,不管是路由Cache,还是那种类似Cisco CEF机制,背后的原则都是一次路由,多次转发,只不过CEF的转发表是主动生成的,而不是等到数据包到达的时候才生成的。所以说,这种方式实乃一种传统的方式。
如果转发交换表是自己学习生成的,那么这种设备在常识上就是真正的交换机。比如以太网交换机,靠MAC/Port映射表来转发数据,比如MPLS交换机,靠标签/Port映射表来转发数据,不管哪种交换机,其映射表都是学习获得的,比如以太网交换机有从帧头学习MAC/Port映射的能力,而MPLS交换机则可以通过标签交换协议来生成映射。此外还有更多的交换机,比如ATM交换机,也是有自己的虚电路协议的,已经快被淘汰了,故不多谈。
我前面说过,要把数据中心连成一个交换网络而不是一个IP路由网络,那么使用那种交换机呢?是以太网交换机,还是MPLS交换机呢?其实,数据中心完全可以承载在一张MPLS网上,那简直比IP网要好太多,不过要是那样,也就没有本文了。本文的意思是,自己设计一种交换机,不需要任何现有的协议交换机!
这怎么可能?如果在十几年前,这种思路也只能停留在大学或者Cisco,华为之类设备商的实验室里,然而在SDN时代,出现了叫做裸交换机和白牌交换机的东西,这些交换机说白了就是可以任意编程。这样任何公司都可以自研定制的交换机了!自研交换机可以更贴合自己的网络,可谓是高端定制。SDN时代是彻底结束了厂商垄断的时代,SDN将网络开放给了程序员,CCIE将不再牛逼!
开始我的协议。
首先介绍一下网络中每一台设备里的转发表是什么样子:
之所以可以构建这个位图,就是因为全交叉连线的胖树在每一个节点都有三个走向:
往树叶方向:如果目标端口位于源端口的一个方向,那么这就是最近的路径,当然是首选;
往平行方向:不同目标ToR的最优选择或者树叶方向不可达时的次优选择;
往树根方向:树叶方向,平行方向均无路可走时的默认选择,类似默认路由。
那么下一个问题,这个转发交换表是怎么生成的呢?
首先,我们要定义边缘设备,在这种设备上,源IP地址和目标IP地址被转换成源端口和目标端口,这样在数据包进入这个网络后,就可以用端口来交换了,这就避开了用最长前缀匹配计算的开销,完全用端口这个确定的一维数据来作为交换的依据,这个思路和MPLS是一致的,和MPLS不同的是,我这里的网络拓扑是确定的CLOS结构,这就让内部的交换结构更加简单,每个节点的三个固定走向分属三个不同的优先级意义也正在此。IP地址和端口之间的映射方式有很多种,我首选的是HASH映射,这样比较简单并且高效。
下面说下节点的端口学习,最简单的方法往往是最高效的方法。在网络初启的时候,从每一个边缘设备发起以自己的端口ID为内容的Flood,每一个Flood数据包传遍全网,这样所有的设备就可以学习到特定端口的方向信息,这个和以太网交换机是一致的。不同的是,以太网交换机是带内学习的,以太网本身就是一个广播网络,查询映射表项失败的情况下可以用广播来发送数据,而我这里的协议交换机则是带外学习的,因为我的目的是在数据传输之前就构建好每一台设备的交换表,旨在快速转发。
最后一个问题,这个交换网络该怎么维护呢?如果有一条线缆断掉了,或者一台设备宕机了,如何通知其它设备更新转发交换表呢?这就需要一个新的协议。非常简单,仅仅需要往上游和平行两个方向传播链路状态变更即可,不需要向叶子节点传播,因为向上游转发总是最后的不得已的选择。为什么可以如此简单?因为这是一棵棵树组合而成的胖树CLOS结构! 认识到这个特征,很多设计都可以非常简单。
理解了转发交换表是怎么生成的,最终的效果应该是下面这样:
我这个自研交换协议确实是拍脑袋的产物,由于我个人并非做这一块业务的,仅仅是兴趣使然,不然也不会占周末的时间去搞这么一个可能永远也用不起来的东西。
之前像腾讯这种巨头企业也设计过这种自研的协议,比如下面连接里介绍的SRP: 腾讯-SRP。然后,在弯曲评论上被喷了,在别的地方感兴趣的也不多,只是在某本吹水的SDN书籍上提到过。其实,在厂商垄断的时代,再牛逼的互联网企业也只能停留在做业务编程的水准,评论里说腾讯做网络外行,我想在厂商垄断的年代,确实很外行,真正的内行只有Cisco,华为做核心交换的那帮人,再牛逼的编程者面对真正网络技术而言,都是外行。我自己在2013年的时候,也说过腾讯的网络技术就是堆概念,拿着一大堆新的网络技术胡来。比如业内推出了SDN,赶紧就部署,Cisco的协议在腾讯的机房都能看到,里面的人也能把这些概念背得滚瓜烂熟,但是做出来的网络真真就是四不像,表面上看牛逼的样子,其实就是拿名词吓人的。以我现在的观念来看,当时确实苛求腾讯这种非网络厂商了,只要不是网络厂商的人,谁都做不好,别说腾讯,换家美国的互联网公司也一样,要想做好网络,好办,买Cisco或者华为的方案即可,然后他们派个工程队帮你实现了,全程不用你插手。知道网管多牛逼了吧,我常常搞不懂为什么网吧的小混混网管怎么可以这么牛逼哄哄,难道因为他们是混混吗?后来见了外资银行那些不纹身但穿西装的网管也同样牛逼哄哄的时候,我才明白,原来人家玩的是垄断,我能碰的东西,你们不能碰。
上学时老师就讲过,网络切分为资源子网和通信子网,互联网公司的技术局限在资源子网,而通信子网几乎垄断在设备厂商的手中,他们就像网吧纹身的小混混网管一样,屌的很。在互联网公司看来,所谓的网络技术就是TCP,如果提到路由和交换,他们是不屑的,互联网公司想当然地认为TCP能解决一切问题,如果说再深入一些,无奈很吃力地在IP协议上做点文章,搞搞网卡驱动,至于说数据出了网卡,他们真真的没辙...我想我看到了程序员和网管之间分歧的本质了。
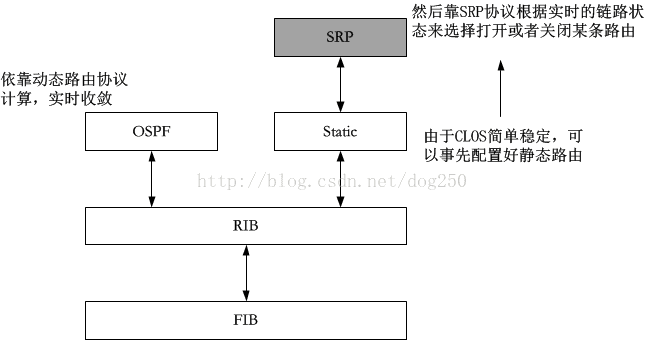
回到腾讯的SRP,从技术上评价它,其最大的败笔就是明明已经触到了交换核心概念的边缘,却又回到了路由!搞那么复杂但高效的交换矩阵,到头来就是为了设置路由!注意,是路由啊。已经触碰到了成功的边缘却还是没能突破边界,所以遗憾。路由仅仅是概念并非标准,否则,MPLS就不会被发明出来了。我们在乎的是找一个出口把数据包发出去,而这件事为什么非得靠路由来做呢?更何况,设备的控制权已经不在厂商手里了,已经完全交给了程序员。人家都是那路由表生成交换表,腾讯的SRP却反其道而行,设计出一个还不错的链路状态更新协议却只是为了生成路由表...
从弯曲评论里的那个PDF中搞出一个SRP的结构图:
来看看我本文里设计的协议,姑且叫它DCIP(DCI Protocol)协议吧,其根本意义在重新映射了数据平面,实际上就是一种Overlay,它的图示如下:
能如此设计DCIP有个前提,那就是交换机是裸交换机或者白牌交换机。顺便说一下,就是因为有了这种交换机,才会有越来越多的厂商声称自己的交换机是自研交换机,当然,自研的水平参差不齐,毕竟现在网络技术研发才刚刚开放,以后所有公司的自研设备水平都会提高的,就跟业务编程一样简单。
...
以前我们听说过一般企业网会部署OSPF,而ISP会部署IS-IS,以后,在设备的控制权掌握在自己手中之后,越来越多的企业网将会自研交换协议,而不再使用标准的路由协议,迫于这种客户将脱缰的压力,设备厂商不得已而为之,也陆续将设备的编程接口逐步开放,比如推出I2RS标准,让客户可以折腾自己已经购买的设备,这样鉴于大厂商的口碑,客户依然会购买大厂的设备而不会流失掉。
我深深知道程序员和网管之间有个鸿沟,但我就是无法填掉它,有时这道鸿沟就在我自己的心里。如今,我依然是个程序员,以往我一向喜欢说自己是比较懂网络但是编程编的不好的程序员,以此展示一下我心中的那道鸿沟,SDN的时代来临,软件定义网络,那道鸿沟可以填补了,网络不再是网管的专利,而是程序员编码的一个程序。
在《 网络虚拟化(SDN,NFV..)和企业骨干网的演化》一文中,我的观点比较原始且传统,我描述的企业骨干网是一个AS,通过IGP互联,比如OSPF,这显得企业骨干就是一个IP骨干网。但是,事实上真有这个必要在企业网部署IGP吗?我们看一下企业骨干网的典型结构:
基于这个区别,我们便可以优化企业网的路由系统了。
仔细观察企业网的层级结构,就会发现它是一个基于胖树的典型CLOS交换结构,之所以可以规划成这种规则的结构,源自于以下的事实:
1.企业网互联的节点一般都是数据中心而不是接入点,而数据本来就是分层的;
2.企业的数据中心可以自己规划的,节点固定,稳定。
所以说,完全没必要在这些数据中心之间运行OSPF这类路由协议,而应该将企业网做成真正交换型的网络。
我来给出一个拍脑袋想出来的简单的”交换协议“来替代复杂的IGP路由协议为企业骨干网打通脉络,在给出这个协议之前,我得先来解释一下路由和交换的区别。在我这里,路由指的是需要复杂计算的寻路过程,主要包括两方面的计算开销,一方面是动态路由协议的计算开销(如果你是静态配置的路由,那么这部分开销由你的脑力替代),另一方面是为数据包查找路由表的开销,这部分计算主要消耗在最长前缀匹配中。现在看看什么是交换,交换在我这里指的是一个转发动作,这个动作的计算开销必须尽可能的小,比如只需要固定几步这种,像CPU的MMU执行的那种转换操作那样,所以交换应该非常容易用硬件实现,在交换网络中,数据的转发动作开销是极小且固定的,基本不需要进行运算,而这些固定的步骤是如何做到数据的正确转发的呢?交换机怎么知道数据包该转往那个端口呢?转发信息来源于两种机制,一种机制是交换机自己学习,另外一种是依靠路由表来生成。
如果转发交换表是路由表生成的,那么这种设备可以看作是高端路由器,交换表便可视为路由表项的Cache,依照这种方式设计出来的硬件早就不知道跑了多少年了,不管是路由Cache,还是那种类似Cisco CEF机制,背后的原则都是一次路由,多次转发,只不过CEF的转发表是主动生成的,而不是等到数据包到达的时候才生成的。所以说,这种方式实乃一种传统的方式。
如果转发交换表是自己学习生成的,那么这种设备在常识上就是真正的交换机。比如以太网交换机,靠MAC/Port映射表来转发数据,比如MPLS交换机,靠标签/Port映射表来转发数据,不管哪种交换机,其映射表都是学习获得的,比如以太网交换机有从帧头学习MAC/Port映射的能力,而MPLS交换机则可以通过标签交换协议来生成映射。此外还有更多的交换机,比如ATM交换机,也是有自己的虚电路协议的,已经快被淘汰了,故不多谈。
我前面说过,要把数据中心连成一个交换网络而不是一个IP路由网络,那么使用那种交换机呢?是以太网交换机,还是MPLS交换机呢?其实,数据中心完全可以承载在一张MPLS网上,那简直比IP网要好太多,不过要是那样,也就没有本文了。本文的意思是,自己设计一种交换机,不需要任何现有的协议交换机!
这怎么可能?如果在十几年前,这种思路也只能停留在大学或者Cisco,华为之类设备商的实验室里,然而在SDN时代,出现了叫做裸交换机和白牌交换机的东西,这些交换机说白了就是可以任意编程。这样任何公司都可以自研定制的交换机了!自研交换机可以更贴合自己的网络,可谓是高端定制。SDN时代是彻底结束了厂商垄断的时代,SDN将网络开放给了程序员,CCIE将不再牛逼!
开始我的协议。
首先介绍一下网络中每一台设备里的转发表是什么样子:
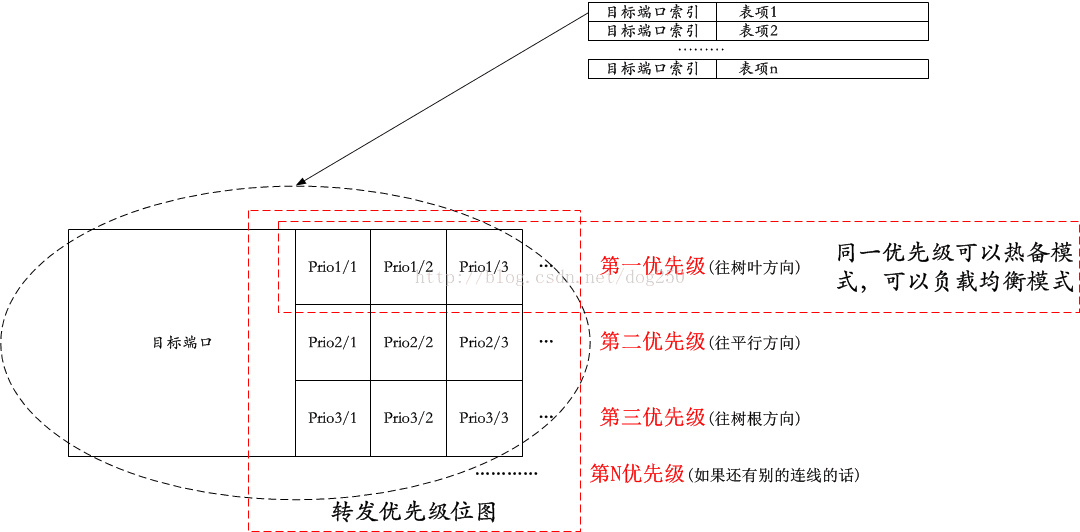
之所以可以构建这个位图,就是因为全交叉连线的胖树在每一个节点都有三个走向:
往树叶方向:如果目标端口位于源端口的一个方向,那么这就是最近的路径,当然是首选;
往平行方向:不同目标ToR的最优选择或者树叶方向不可达时的次优选择;
往树根方向:树叶方向,平行方向均无路可走时的默认选择,类似默认路由。
那么下一个问题,这个转发交换表是怎么生成的呢?
首先,我们要定义边缘设备,在这种设备上,源IP地址和目标IP地址被转换成源端口和目标端口,这样在数据包进入这个网络后,就可以用端口来交换了,这就避开了用最长前缀匹配计算的开销,完全用端口这个确定的一维数据来作为交换的依据,这个思路和MPLS是一致的,和MPLS不同的是,我这里的网络拓扑是确定的CLOS结构,这就让内部的交换结构更加简单,每个节点的三个固定走向分属三个不同的优先级意义也正在此。IP地址和端口之间的映射方式有很多种,我首选的是HASH映射,这样比较简单并且高效。
下面说下节点的端口学习,最简单的方法往往是最高效的方法。在网络初启的时候,从每一个边缘设备发起以自己的端口ID为内容的Flood,每一个Flood数据包传遍全网,这样所有的设备就可以学习到特定端口的方向信息,这个和以太网交换机是一致的。不同的是,以太网交换机是带内学习的,以太网本身就是一个广播网络,查询映射表项失败的情况下可以用广播来发送数据,而我这里的协议交换机则是带外学习的,因为我的目的是在数据传输之前就构建好每一台设备的交换表,旨在快速转发。
最后一个问题,这个交换网络该怎么维护呢?如果有一条线缆断掉了,或者一台设备宕机了,如何通知其它设备更新转发交换表呢?这就需要一个新的协议。非常简单,仅仅需要往上游和平行两个方向传播链路状态变更即可,不需要向叶子节点传播,因为向上游转发总是最后的不得已的选择。为什么可以如此简单?因为这是一棵棵树组合而成的胖树CLOS结构! 认识到这个特征,很多设计都可以非常简单。
理解了转发交换表是怎么生成的,最终的效果应该是下面这样:
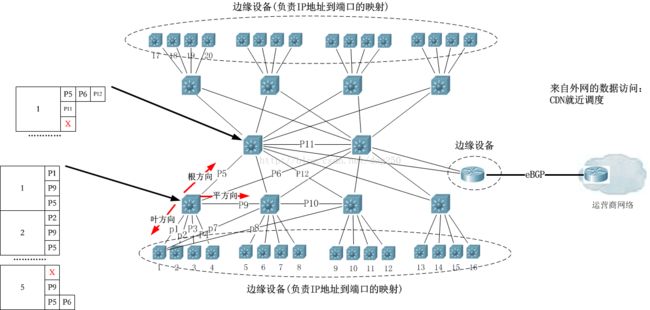
我这个自研交换协议确实是拍脑袋的产物,由于我个人并非做这一块业务的,仅仅是兴趣使然,不然也不会占周末的时间去搞这么一个可能永远也用不起来的东西。
之前像腾讯这种巨头企业也设计过这种自研的协议,比如下面连接里介绍的SRP: 腾讯-SRP。然后,在弯曲评论上被喷了,在别的地方感兴趣的也不多,只是在某本吹水的SDN书籍上提到过。其实,在厂商垄断的时代,再牛逼的互联网企业也只能停留在做业务编程的水准,评论里说腾讯做网络外行,我想在厂商垄断的年代,确实很外行,真正的内行只有Cisco,华为做核心交换的那帮人,再牛逼的编程者面对真正网络技术而言,都是外行。我自己在2013年的时候,也说过腾讯的网络技术就是堆概念,拿着一大堆新的网络技术胡来。比如业内推出了SDN,赶紧就部署,Cisco的协议在腾讯的机房都能看到,里面的人也能把这些概念背得滚瓜烂熟,但是做出来的网络真真就是四不像,表面上看牛逼的样子,其实就是拿名词吓人的。以我现在的观念来看,当时确实苛求腾讯这种非网络厂商了,只要不是网络厂商的人,谁都做不好,别说腾讯,换家美国的互联网公司也一样,要想做好网络,好办,买Cisco或者华为的方案即可,然后他们派个工程队帮你实现了,全程不用你插手。知道网管多牛逼了吧,我常常搞不懂为什么网吧的小混混网管怎么可以这么牛逼哄哄,难道因为他们是混混吗?后来见了外资银行那些不纹身但穿西装的网管也同样牛逼哄哄的时候,我才明白,原来人家玩的是垄断,我能碰的东西,你们不能碰。
上学时老师就讲过,网络切分为资源子网和通信子网,互联网公司的技术局限在资源子网,而通信子网几乎垄断在设备厂商的手中,他们就像网吧纹身的小混混网管一样,屌的很。在互联网公司看来,所谓的网络技术就是TCP,如果提到路由和交换,他们是不屑的,互联网公司想当然地认为TCP能解决一切问题,如果说再深入一些,无奈很吃力地在IP协议上做点文章,搞搞网卡驱动,至于说数据出了网卡,他们真真的没辙...我想我看到了程序员和网管之间分歧的本质了。
回到腾讯的SRP,从技术上评价它,其最大的败笔就是明明已经触到了交换核心概念的边缘,却又回到了路由!搞那么复杂但高效的交换矩阵,到头来就是为了设置路由!注意,是路由啊。已经触碰到了成功的边缘却还是没能突破边界,所以遗憾。路由仅仅是概念并非标准,否则,MPLS就不会被发明出来了。我们在乎的是找一个出口把数据包发出去,而这件事为什么非得靠路由来做呢?更何况,设备的控制权已经不在厂商手里了,已经完全交给了程序员。人家都是那路由表生成交换表,腾讯的SRP却反其道而行,设计出一个还不错的链路状态更新协议却只是为了生成路由表...
从弯曲评论里的那个PDF中搞出一个SRP的结构图:
来看看我本文里设计的协议,姑且叫它DCIP(DCI Protocol)协议吧,其根本意义在重新映射了数据平面,实际上就是一种Overlay,它的图示如下:

能如此设计DCIP有个前提,那就是交换机是裸交换机或者白牌交换机。顺便说一下,就是因为有了这种交换机,才会有越来越多的厂商声称自己的交换机是自研交换机,当然,自研的水平参差不齐,毕竟现在网络技术研发才刚刚开放,以后所有公司的自研设备水平都会提高的,就跟业务编程一样简单。
...
以前我们听说过一般企业网会部署OSPF,而ISP会部署IS-IS,以后,在设备的控制权掌握在自己手中之后,越来越多的企业网将会自研交换协议,而不再使用标准的路由协议,迫于这种客户将脱缰的压力,设备厂商不得已而为之,也陆续将设备的编程接口逐步开放,比如推出I2RS标准,让客户可以折腾自己已经购买的设备,这样鉴于大厂商的口碑,客户依然会购买大厂的设备而不会流失掉。
曾经,网络技术水平取决于你花钱的水平,花钱干什么呢?花钱来培训,考证,学习配置命令,学习Cisco之类公司的私有协议,由于钱是最硬的门槛,所以网络专家一般都是精英。现在呢,网络技术水平完全取决于你的编程水平,买来裸机,编写程序,你就有了自研的协议...知道谁是精英了吗?程序员!
Google公司是SDN持续进化的推动力之一,它本身作为一家互联网公司并不生产网络设备,但是它遍布全球的服务器却需要强大的网络技术支撑,所以自研肯定是最经济的选择,在SDN还是纸面概念的时候,Google就率先拿B4作为其试验田,让SDN成为了现实,紧随其后,各大互联网公司均开始引入SDN的思想...
... 明天有时间且有新内容的话再继续