最好还是先卸载掉openjdk,在安装sun公司的jdk.
yum -y remove java java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.x86_64
-rwxrw-rw-. 1 root root 85414670 Jul 10 11:32 jdk-7u25-linux-x64.rpm
-rwxrw-rw-. 1 root root 85414670 Jul 10 11:32 jdk-7u25-linux-x64.rpm
Preparing... ########################################### [100%]
1:jdk ########################################### [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
1、检测ssh是否启动,命令如下:
[root@hadoopmaster home]# service sshd status
openssh-daemon is stopped
2、查看sshd是否已经是系统服务:
[root@hadoopslaver ~]# chkconfig --list |grep sshd
sshd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
3、使用如下命令设置sshd服务自动启动:
[root@hadoopslaver ~]# chkconfig --level 5 sshd on
[root@hadoopslaver ~]# chkconfig --list |grep sshd
sshd 0:off 1:off 2:off 3:off 4:off 5:on 6:off
2、启动ssh,
[root@hadoopmaster home]# service sshd start
Generating SSH1 RSA host key: [ OK ]
Generating SSH2 RSA host key: [ OK ]
Generating SSH2 DSA host key: [ OK ]
Starting sshd: [ OK ]
3、在master主机生成密钥并配置ssh无密码登入主机,步骤:
# cd /root/
#cd .ssh/ (如果没有.ssh目录则创建一个:mkdir .ssh)
1) 生成密钥:
[root@hadoopmaster .ssh]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
ec:d5:cd:e8:91:e2:c3:f9:6f:33:9e:63:3a:3e:ac:42 root@hadoopmaster
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| . . = |
| S o = o |
| .E+ + . |
| .. =.. |
| . o+ *. |
| ..o+O++ |
+-----------------+
[root@hadoopmaster .ssh]# ll
total 12
-rw-------. 1 root root 1675 Jul 10 16:16 id_rsa
-rw-r--r--. 1 root root 399 Jul 10 16:16 id_rsa.pub
2) 将id_rsa.pub 拷贝到.ssh目录下,并重新命名为authorized_keys,便可以使用密钥方式登录。
[root@hadoopmaster .ssh]# cp id_rsa.pub authorized_keys
3) 修改密钥权限:
[root@hadoopmaster .ssh]# chmod go-rwx authorized_keys
[root@hadoopmaster .ssh]# ll
total 16
-rw-------. 1 root root 399 Jul 10 16:20 authorized_keys
-rw-------. 1 root root 1675 Jul 10 16:16 id_rsa
-rw-r--r--. 1 root root 399 Jul 10 16:16 id_rsa.pub
4) 测试:
[root@hadoopmaster .ssh]# ssh myhadoopm
The authenticity of host 'myhadoopm (192.168.80.144)' can't be established.
RSA key fingerprint is 2a:c0:f5:ea:6b:e6:11:8a:47:8a:de:8d:2e:d2:97:36.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'myhadoopm,192.168.80.144' (RSA) to the list of known hosts.
这样即可无密码进行登录。
5) 远程拷贝密钥到slaver节点服务器:
[root@hadoopmaster .ssh]# scp authorized_keys root@myhadoops:/root/.ssh
The authenticity of host 'myhadoops (192.168.80.244)' can't be established.
RSA key fingerprint is d9:63:3d:6b:16:99:f5:3c:67:fd:ed:86:96:3d:27:f7.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'myhadoops,192.168.80.244' (RSA) to the list of known hosts.
root@myhadoops's password:
authorized_keys 100% 399 0.4KB/s 00:00
6) 测试master无密码登录slaver上:
[root@hadoopmaster .ssh]# ssh hadoopslaver
[root@hadoopslaver ~]# exit
logout
Connection to hadoopslaver closed.
[root@hadoopmaster .ssh]#
第五步:Hadoop 集群部署
试验集群的部署结构:

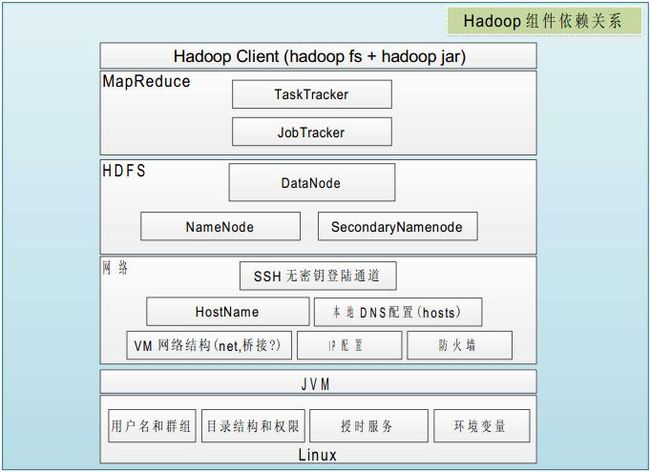
系统和组建的依赖关系:
1、下载hadoop安装文件 hadoop-1.1.2.tar.gz,并将文件复制到hadoop安装文件夹
#cp hadoop-1.1.2.tar.gz /opt/modules/hadoop
解压hadoop安装文件,
#cd /opt/modules/hadoop
#tar –xzvf hadoop-1.1.2.tar.gz
目录路径为:
/opt/modules/hadoop/hadoop-1.1.2
2、配置conf/hadoop-env.sh文件
#vi hadoop-env.sh 默认是被注释的,去掉注释,把JAVA_HOME 改成现有java 安装目录:

3、修改core-site.xml:
fs.default.name
hdfs://hadoopmaster:9000
hadoop.tmp.dir
/tmp/hadoop-root
1)fs.default.name是NameNode的URI。hdfs://主机名:端口/
2)hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
4、HDFSNameNode,DataNode组建配置hdfs-site.xml
Vi /opt/modules/hadoop/hadoop-1.1.2/conf/hdfs-site.xml
dfs.name.dir
/opt/data/hadoop/hdfs/name,/opt/data1/hadoop/hdfs/name
dfs.data.dir
/opt/data/hadoop/hdfs/data,/opt/data1/hadoop/hdfs/data
dfs.http.address
hadoopmaster:50070
dfs.secondary.http.address
hadoopmaster:50090
dfs.replication
2
dfs.datanode.du.reserved
1073741824
5、#配置MapReduce-JobTrackerTaskTracker 启动配置
Vi /opt/modules/hadoop/hadoop-1.1.2/conf/mapred-site.xml
mapred.job.tracker
hadoopmaster:9001
mapred.local.dir
/opt/data/hadoop/mapred/mrlocal
true
mapred.system.dir
/opt/data/hadoop/mapred/mrsystem
true
mapred.tasktracker.map.tasks.maximum
2
true
mapred.tasktracker.reduce.tasks.maximum
1
true
io.sort.mb
32
true
mapred.child.java.opts
-Xmx64M
mapred.compress.map.output
true
6、配置masters和slaves主从结点:
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。
vi masters:
输入:
hadoopmaster
vi slaves:
输入:
hadoopmaster
hadoopslaver
配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
scp –r /opt/modules/hadoop/hadoop-1.1.2 root@myhadoops:/opt/modules/hadoop/
7、#创建master(hadoopmaster)上的mapreduce
mkdir -p /opt/data/hadoop/mapred/mrlocal
mkdir -p /opt/data/hadoop/mapred/mrsystem
mkdir -p /opt/data/hadoop/hdfs/name
mkdir -p /opt/data/hadoop/hdfs/data
mkdir -p /opt/data/hadoop/hdfs/namesecondary
8、#创建slaver(hadoopslaver)上的mapreduce
mkdir -p /opt/data1/hadoop/mapred/mrlocal
mkdir -p /opt/data1/hadoop/mapred/mrsystem
mkdir -p /opt/data1/hadoop/hdfs/name
mkdir -p /opt/data1/hadoop/hdfs/data
9、格式化hadoop :hadoop namenode –format
[root@hadoopmaster bin]# ./hadoop namenode -format
13/07/11 14:35:44 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoopmaster/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.1.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013
************************************************************/
13/07/11 14:35:44 INFO util.GSet: VM type = 64-bit
13/07/11 14:35:44 INFO util.GSet: 2% max memory = 19.33375 MB
13/07/11 14:35:44 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/07/11 14:35:44 INFO util.GSet: recommended=2097152, actual=2097152
13/07/11 14:35:45 INFO namenode.FSNamesystem: fsOwner=root
13/07/11 14:35:45 INFO namenode.FSNamesystem: supergroup=supergroup
13/07/11 14:35:45 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/07/11 14:35:45 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/07/11 14:35:45 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/07/11 14:35:45 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/07/11 14:35:46 INFO common.Storage: Image file of size 110 saved in 0 seconds.
13/07/11 14:35:46 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/opt/data/hadoop/hdfs/name/current/edits
13/07/11 14:35:46 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/opt/data/hadoop/hdfs/name/current/edits
13/07/11 14:35:47 INFO common.Storage: Storage directory /opt/data/hadoop/hdfs/name has been successfully formatted.
13/07/11 14:35:47 INFO common.Storage: Image file of size 110 saved in 0 seconds.
13/07/11 14:35:47 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/opt/data1/hadoop/hdfs/name/current/edits
13/07/11 14:35:47 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/opt/data1/hadoop/hdfs/name/current/edits
13/07/11 14:35:47 INFO common.Storage: Storage directory /opt/data1/hadoop/hdfs/name has been successfully formatted.
13/07/11 14:35:47 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoopmaster/127.0.0.1
************************************************************/
[root@hadoopmaster bin]#
查看输出保证分布式文件系统格式化成功
执行完后可以到master(hadoopmaster)机器上看到/opt/data/hadoop/hdfs/name和/opt/data1/hadoop/hdfs/name两个目录。在主节点master(hadoopmaster)上面启动hadoop,主节点会启动所有从节点的hadoop。
10.启动hadoop服务:
在hadoopmaster上,进入handoop安装目录下的bin目录:
[root@hadoopmaster bin]# ./start-all.sh
starting namenode, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-namenode-hadoopmaster.out
hadoopmaster: starting datanode, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-datanode-hadoopmaster.out
hadoopslaver: starting datanode, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-datanode-hadoopslaver.out
hadoopmaster: starting secondarynamenode, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-secondarynamenode-hadoopmaster.out
starting jobtracker, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-jobtracker-hadoopmaster.out
hadoopslaver: starting tasktracker, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-tasktracker-hadoopslaver.out
hadoopmaster: starting tasktracker, logging to /opt/modules/hadoop/hadoop-1.1.2/libexec/../logs/hadoop-root-tasktracker-hadoopmaster.out
[root@hadoopmaster bin]# jps
3303 DataNode
3200 NameNode
3629 TaskTracker
3512 JobTracker
3835 Jps
3413 SecondaryNameNode
[root@hadoopmaster bin]#
hadoopslaver机器上查看进程:
[root@hadoopslaver ~]# jps
3371 Jps
3146 DataNode
3211 TaskTracker
[root@hadoopslaver ~]#
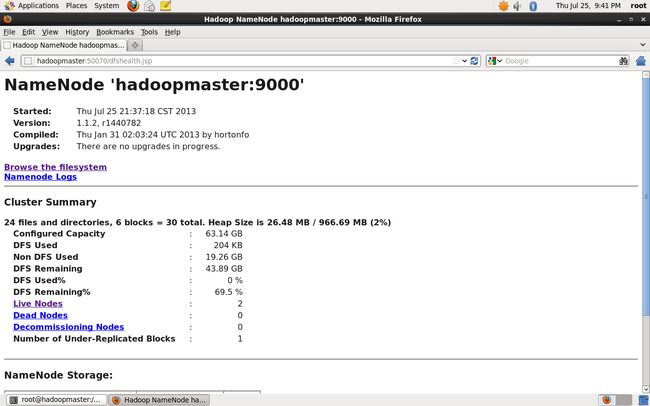
安装成功后访问管理页面:
错误解决:
1、出现“PiEstimator_TMP_3_141592654 already exists. Please remove it first.”错误
[root@hadoopmaster bin]# ./hadoop jar /opt/modules/hadoop/hadoop-1.1.2/hadoop-examples-1.1.2.jar pi 20 50
Number of Maps = 20
Samples per Map = 50
java.io.IOException: Tmp directory hdfs://myhadoopm:9000/user/root/PiEstimator_TMP_3_141592654 already exists. Please remove it first.
at org.apache.hadoop.examples.PiEstimator.estimate(PiEstimator.java:270)
at org.apache.hadoop.examples.PiEstimator.run(PiEstimator.java:342)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.hadoop.examples.PiEstimator.main(PiEstimator.java:351)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:68)
at org.apache.hadoop.util.ProgramDriver.driver(ProgramDriver.java:139)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:64)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:156)
解决办法:
[root@hadoopmaster bin]# ./hadoop fs -rmr hdfs://myhadoopm:9000/user/root/PiEstimator_TMP_3_141592654
Deleted hdfs://myhadoopm:9000/user/root/PiEstimator_TMP_3_141592654
[root@hadoopmaster bin]#
