【语义分割系列】一图讲解FCN16s实现过程。对照着pytorch代码讲解的。
新人。有错误欢迎大佬指出。这个是自己的学习笔记,怕忘。哈哈 感觉非常适合新手 将理论和代码能够结合到一起看还是很舒服的。
看了下fcn的代码和理论。这里就以FCN16s为例讲解,16s清晰了 32s 8s 只是在此基础上减,加而已了。
我看的代码是一VGG16为主干网络。关键步骤的解释在下图中已标记清晰,对照其他主干网络代码看也都能看的通。
FCN16s说白了就是 将 1/32图的预测结果做反卷积,变成1 /16图。然后再将1 /16图池化结果做预测,并与前的1/32图
结果做加法。最终得到的是加强版的1/16预测结果,再将其反卷积获得原图大小得到最终结果。
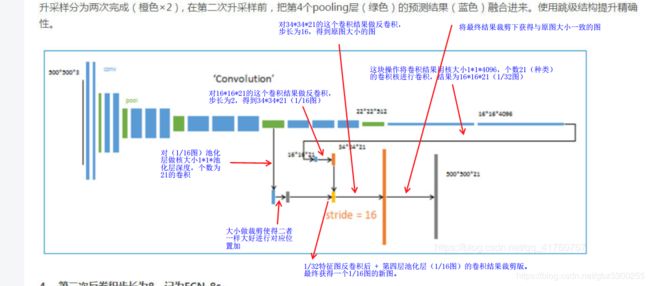
这个过程是看代码才把这个图理顺清楚。所以啊,理解什么算法,最重要的还是看代码 看代码 看代码。
下面把代码贴出来一起看得了。
先来个vgg16网络的结构图
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)#缩放一次
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
然后贴一段fcn16S的代码。
class FCN16(nn.Module):
def __init__(self, num_classes):
super().__init__()
feats = list(models.vgg16(pretrained=True).features.children())
self.feats = nn.Sequential(*feats[0:16])#卷积加池化和relu进行了三次 得到的是1 /8的池化图
self.feat4 = nn.Sequential(*feats[17:23])#卷积好几次池化一次 变成1/16的池化图
self.feat5 = nn.Sequential(*feats[24:30])#卷积好几次池化一次变成1/32的池化图
self.fconn = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.score_fconn = nn.Conv2d(4096, num_classes, 1)
self.score_feat4 = nn.Conv2d(512, num_classes, 1)
def forward(self, x):#前向传播过程
feats = self.feats(x)#1/8池化图 上面图左往右数第3个绿色块 感觉这块没啥用 因为直接用的1/16
feat4 = self.feat4(feats)#1/16池化图 左往右数第4个绿色块
feat5 = self.feat5(feat4)#1/32池化图 左往右数第5个绿色块
fconn = self.fconn(feat5)#对应最后两次卷积 最后一个绿色块左侧的两个蓝色块
score_feat4 = self.score_feat4(feat4)#将1/16池化结果做卷积 卷积核个数为分类数
score_fconn = self.score_fconn(fconn)#将最后的卷积结果再做次卷积 卷积核个数为分类数
score = F.upsample_bilinear(score_fconn, score_feat4.size()[2:])# 1/32图的反卷积
score += score_feat4#上述结果与1/16图加法 对应图 黄色的
return F.upsample_bilinear(score, x.size()[2:])#最后一次反卷积 将其放缩到原图大小