基于深度学习的点云分类--PointNet(代码结构+环境Ubuntu16.04+CUDA9+tensorflow1.9.0)
希望跟大家共同讨论、进步。
我的公众号:
https://mp.weixin.qq.com/s?__biz=MzU2MzcxMjE3MQ==&mid=2247483897&idx=1&sn=7a39c0be672dcdd35a421926291cfde6&chksm=fc57583dcb20d12b0efbe57fb7060eb5ecc953f7f30e0a95545c56c929fff177bc055e7a6fc2&token=71175244&lang=zh_CN#rd
pointnet--第一个提出直接将点云作为神经网络输入来进行点云分类,是CVPR 2017论文。
没有其他引言,直接贴上pointnet git地址 : https://github.com/charlesq34/pointnet
本文大纲:
一、环境搭建
二、分类模型训练
三、模型评估(本文没有涉及,放到下一篇)
一、环境搭建
需要安装:
1、python ,我用的版本是Python3.5
2、tensorflow ,我用的版本是1.9.0
![]()
3、cuda,我用的版本是cuda 9.0
4、cuDNN ,我用的版本是7.1
安装以上4个,参考了知行合一2018的https://blog.csdn.net/davidhopper/article/details/81206673 。该博文写得非常详细具体,在此不重复叙述。
只是下载安装包的过程十分缓慢,经常挂掉,后来找了运维帮忙,加了个,才下好。
5、 h5py
安装指令为:
sudo apt-get install libhdf5-devsudo pip install h5py
二、分类模型训练
先提一下pointnet的结构,在根目录下,有三个.py文件,分别为:
evaluate.py
provider.py
train.py
其中,如单词本身的意思所示,train.py为训练代码,evaluate.py为验证代码,而provider.py涉及到数据集的相关操作。
2.1 数据准备,private.py的结构
这里介绍一下private.py的结构:
2.1.1、首先,download作者提供的数据集
在文件 private.py中,首先检查是否已经有数据集,如果没有,则Download dataset for point cloud classification。
代码如下
DATA_DIR = os.path.join(BASE_DIR, 'data')if not os.path.exists(DATA_DIR):os.mkdir(DATA_DIR)if not os.path.exists(os.path.join(DATA_DIR, 'modelnet40_ply_hdf5_2048')):www = 'https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip'zipfile = os.path.basename(www)os.system('wget %s; unzip %s' % (www, zipfile))os.system('mv %s %s' % (zipfile[:-4], DATA_DIR))os.system('rm %s' % (zipfile))
这个数据集不大,只有416M,所以不需要等太长时间。
2.1.2、打乱数据和标签
def shuffle_data(data, labels)Input:
data: B,N,... numpy array
label: B,... numpy array
Return:
被打乱之后的data[idx, ...], labels[idx], idx
2.1.3、随机旋转点云,作数据集增强。
def rotate_point_cloud(batch_data)Input:
BxNx3 array, original batch of point clouds
Return:
BxNx3 array, rotated batch of point clouds
2.1.4、基于一个确定角度的点云旋转
def rotate_point_cloud_by_angle(batch_data, rotation_angle)Input:
BxNx3 array, original batch of point clouds
Return:
BxNx3 array, rotated batch of point clouds
2.1.5、对每个点云做随机抖动,同样属于数据增强的一部分。
def jitter_point_cloud(batch_data, sigma=0.01, clip=0.05):Input:
BxNx3 array, original batch of point clouds
Return:
BxNx3 array, jittered batch of point clouds
2.1.6、加载数据及标签部分
getDataFiles(list_filename)load_h5(h5_filename)loadDataFile(filename)load_h5_data_label_seg(h5_filename)load_h5_data_label_seg(h5_filename)
2.2开始训练,train.py结构
2.2.1训练
在终端输入下列指令,运行训练代码
python train.py程序执行前有错误,报错AttributeError: module 'scipy.misc' has no attribute 'imread'。
但是我是已经安装了scipy的。后来发现是scipy的版本问题, 降级到scipy==1.2.1就解决了。
降级指令为:
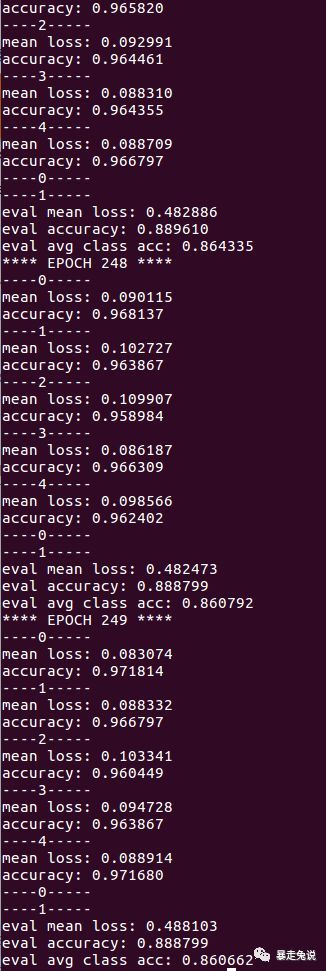
pip install scipy==1.2.12.2.2训练过程截图
(第35次的截图)
2.2.3训练过程中的可视化
可以利用tensorflow自带的可视化工具tensboard来实时关注训练状态
启动tensboard的指令为:
tensorboard --logdir=/你的log的路径然后把终端提示的链接,复制到浏览器打开。就可以实时查看训练状态了。
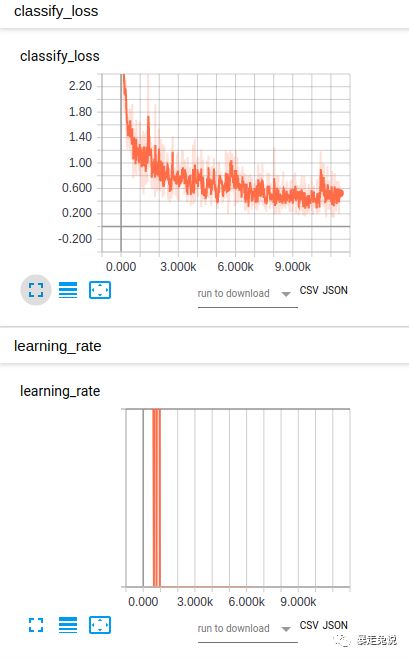
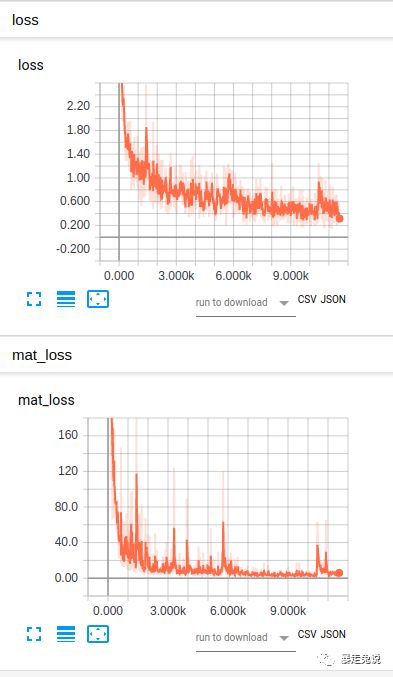

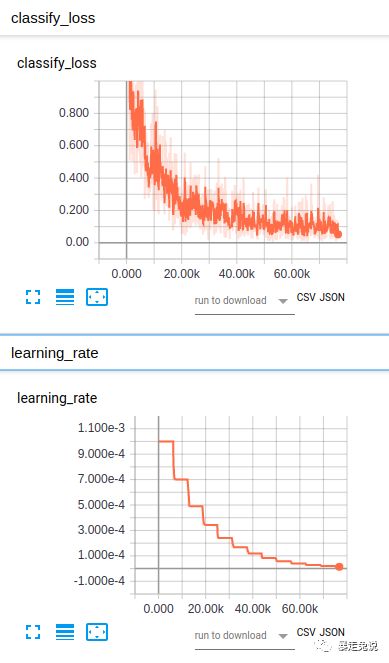
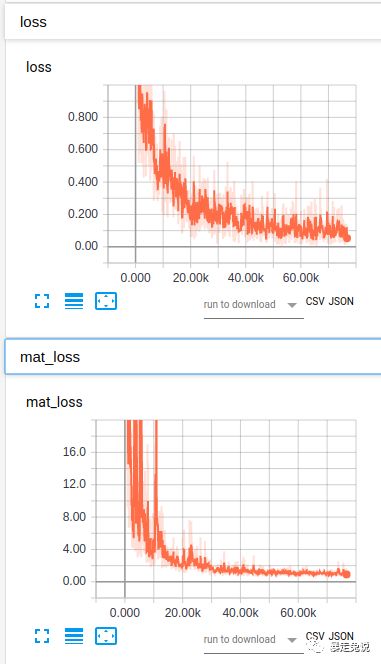

2.2.4代码结构分析
首先,解析命令行参数,用到的是argparse模块,
# DEFAULT SETTINGS
-
parser = argparse.ArgumentParser() parser.add_argument('--gpu', type=int, default=1, help='GPU to use [default: GPU 0]') parser.add_argument('--batch', type=int, default=32, help='Batch Size during training [default: 32]') parser.add_argument('--epoch', type=int, default=200, help='Epoch to run [default: 50]') parser.add_argument('--point_num', type=int, default=2048, help='Point Number [256/512/1024/2048]') parser.add_argument('--output_dir', type=str, default='train_results', help='Directory that stores all training logs and trained models') parser.add_argument('--wd', type=float, default=0, help='Weight Decay [Default: 0.0]')FLAGS = parser.parse_args()
在读取各个指令参数(比如路径、是cpu还是gpu,学习率等)后,主要有以下几个函数,其功能分别为
| 函数名 | 功能简介 |
| deflog_string(out_str) | 日志记录 |
| def get_learning_rate(batch) | 计算指数衰减的学习率。训练时学习率最好随着训练衰减。 |
| def get_bn_decay(batch) | 计算衰减的Batch Normalization 的 decay |
| def train() | 训练函数。 其中: model.py定义了分类网和分割网,它们共享公共的全局特征提取器网络。在model.get_loss中,作者将总损失定义为分类损失和细分损失的加权总和。 在这里,只训练细分网络。权重设置为1.0。 |
| def train_one_epoch(sess, ops, train_writer) | log_string('mean loss: %f' % (loss_sum / float(num_batches))) log_string('accuracy: %f' % (total_correct / float(total_seen))) 分别记录平均loss,以及平均accuracy。 |
| def eval_one_epoch(sess, ops, test_writer) | 用来在测试集上评估evaluate。 |
这个数据集较小,训练了200多次结束,截图如下: