好文收藏:哔哩哔哩大数据采集服务—Lancer系统设计与实践
哔哩哔哩(以下简称B站)的日志采集肩负了B站的所有业务的日志收集并传输,提供离线数据和实时数据以满足离线或实时计算以及业务方订阅的需求。B站日志收集系统是基于Flume设计和搭建而成的。
数据采集是大数据的基石,近几年随着业务的高速增长,产生的数据量越来越大,并且会持续快速增长。因而对采集系统的实时性,稳定性以及可靠性也提出了更高的要求。
本文主要介绍了日志采集系统Lancer的整体架构包括各组件设计及优化。
B站原有的大数据采集服务存在的问题包括:
1) 系统支撑能力不足
-
原生Flume坑多,性能较差
-
异构系统较多,支持比较困难,缺乏统一的协议层标准
-
早期资源不足的情况下,应用的部署也不是很合理,没有做到应用的物理隔离
2) 埋点接入混乱
-
埋点错埋、漏埋、随意埋
-
数据无保障,易丢失、出现问题难以排查和恢复
-
缺乏自动化接入流程,业务方接入过程耗时耗力
-
缺乏一套完整的数据监控体系对数据流链路进行监控
3) 数据覆盖不完全
-
终端覆盖率不足
-
业务场景覆盖不够全面
架构
基于这些问题的存在,我们确立了新数据采集系统的整体设计目标,首先,性能上要做到高吞吐和低延时;其次,质量上要保证数据的安全性和时效性;最后,要做到系统高可用,提供数据灾备,保证数据零丢失。在这样的系统设计目标之下,我们按照如下结构设计了系统:
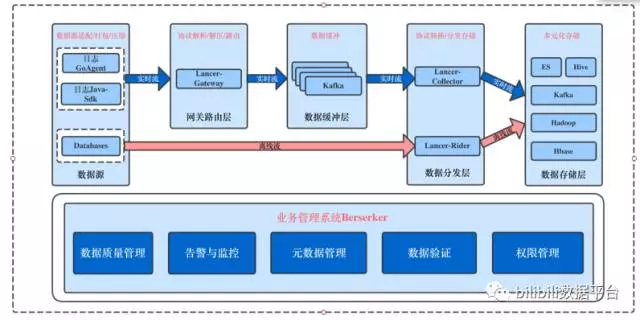
图一 Lancer系统整体架构
从系统架构中可以看出,该系统主要有两种数据流向,分别是实时流和离线流,前者对应流式埋点数据的上报,数据产生并实时上报至网关层;后者对应批量数据的同步,例如从数据库批量的对数据进行同步操作。
以实时流数据为例,数据源包括服务端以及客户端,服务端日志可以通过统一上报模块SDK以Tcp/Udp/LogStream(基于Tcp实现的私有协议,可以获得更高的传输效率)进行数据的收集并上报,而客户端通过客户端数据采集SDK以Http(s)根据不同的网络环境按一定策略将压缩后的数据进行上报。之后由统一的网关层Lancer-Gateway接收上报的数据,并写入到数据缓冲层(Kafka),最后由数据分发层将数据从数据缓冲层中拉取,将数据写入到数据存储层(包括HDFS、HIVE、ES、HBASE等),提供给后续的数据仓库、实时计算或者其他业务部门自订阅和消费。
离线流基于Sqoop,实现了数据库数据的批量同步功能,并支持分发到不同终端的功能,关于离线流的讨论本文不做展开。
基于Flume的数据网关层和分发层的实现方案
Flume是由Cloudera软件公司产出的可分布式日志收集系统,后于2009年被捐赠了apache软件基金会,现已成为apache top项目之一。它是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase,kafka等)的能力 。
Flume以agent为最小的独立运行单位,单agent由Source,Channel和Sink三大组件组成,而Event作为数据在Flume中传递的单位。

图二 原生Flume数据流
Flume的数据流由事件(Event)贯穿始终。Event是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有header头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
1) 网关层 — Lancer-Gateway 系统架构
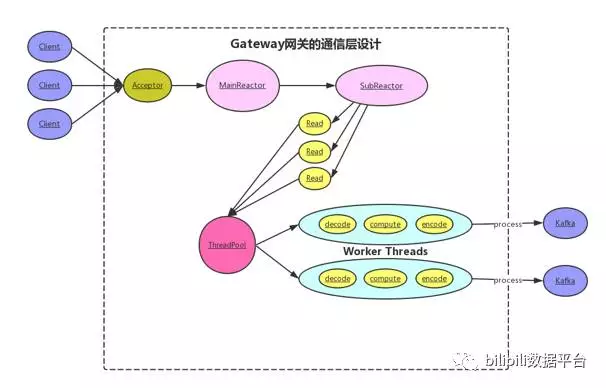
图三 网关层Lancer-Gateway系统设计
网关层Lancer-Gateway提供了LogStreamSource、SysLogUdpSource、SysLogTcpSource、NetSource等,可以接收不同协议层的数据上报。
Socket模型利用了Reactor主从NIO线程模型:
1. 从主线程池中随机选择一个Reactor线程作为Acceptor线程,用于绑定监听端口,接收客户端连接;
2. Acceptor线程接收客户端连接请求之后创建新的SocketChannel,将其注册到主线程池的其它Reactor线程上,由其负责接入认证,握手等操作;
3. 步骤2完成之后,业务层的链路正式建立,将SocketChannel从主线程池的Reactor线程的多路复用器上摘除,重新注册到Sub线程池的线程上,用于处理I/O的读写操作;
4. 在每个Sub线程上配置私有线程池,并发地执行数据的编解码操作并写入到Channel中,由后续的KafkaSink将数据写入到数据缓冲层(Kafka)中。
针对实践过程中实现的优化点:
1. 将flume1.7中使用的netty3升级为netty4, netty4相较于netty3优化了线程模型,提出了串行化设计理念,而线程模型在很大程度上决定了框架的性能, netty4新特性可以参看http://netty.io/wiki/new-and-noteworthy-in-4.0.html#wiki-h2-34
2. 提供了对私用协议LogStream的支持,协议的选择不同,性能模型也不同。相比于公有协议,内部私有协议的性能通常可以被设计的更优。 LogStream基于Tcp实现,减少了不必要的数据传输,定义的格式更利于内部处理。
PS:该系统中使用kafka作为数据缓冲层,而没有直接对采集的数据进行处理和写入数据持久层的原因在于考虑到数据分发端可能存在写入瓶颈问题及消费端消费能力不足而导致数据将Channel阻塞,最终影响整条数据链路的数据传输。将数据线缓存在中间Kafka中,数据会被持久化,保证了异常情况下数据的不丢失,同时kafka中的消息采用pull机制而不是push机制,使系统分发端可以根据消费能力去拉取数据进行处理,不至于拉取过多数据无法处理,造成Channel阻塞,并发生处理异常。
2) 分发层 — Lancer-Collector 系统架构
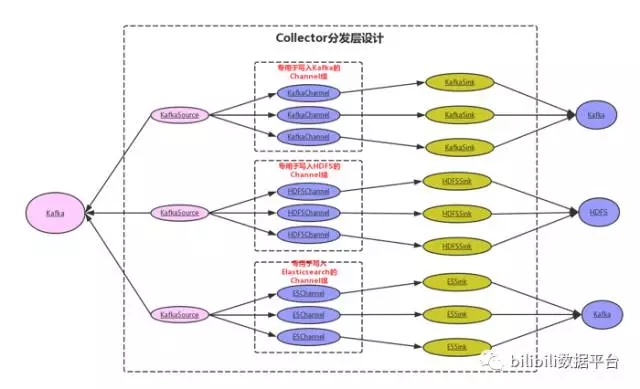
图四 分发层Lacner-Collector系统设计
同样是基于Flume的一个Agent设计,包含了KafkaSource,用于从数据缓冲层拉取数据,根据分发端的不同写入到不同的Channel中,每个Channel挂靠一个Sink,用于执行不同数据分发端的数据写入
针对实践过程中实现的优化点:
1. 不同业务的数据对于分发端来说属于不同的事件,需要执行不同的处理逻辑,以及根据分发端的不同写入不同的分发端中,考虑到不同的数据持久层(包括HDFS、KAFKA、MYSQL等)写入性能并不一致,使用相同的流式处理会产生木桶效应,系统整体取决于数据写入最慢的分发端链路,所以需要根据分发端的不同实现物理上的隔离。
解决方法:在网关层Lancer-Gateway判断该事件的分发端类型,使用单独的kafka topic写入到kafka缓冲层,在不同的物理器上部署分发层Lancer-Collector,订阅单独的kafka topic进行消费,分发至对应的数据持久层。
2. 不同埋点数据其数据量不同,有时会相差很大,由于我们采用的是多Channel的数据分发策略,如果塞入到某个Channel的数据量比较大,会导致对应的Sink率先达到Hdfs的Flush阈值,而会造成整体的数据Flush操作,过多的Flush操作会导致性能的下降。
解决方法:针对Channel做负载均衡操作,将事件尽量均匀的投放到每个Channel中,同时检测Channel中的水位,实时调整将数据写入到相对空闲的Channel中;调大MemoryChannel的capacity,尽量利用MemoryChannel快速的处理能力;调大HdfsSink的batchSize,增加吞吐量,减少hdfs的flush次数。
数据可靠性保证
1)利用了GoAgent等SDK进行数据上报,数据会被先持久化在本地,如果上报网络异常,数据不会丢失
2)数据缓冲层使用Kafka保证了分发端异常情况下数据不丢失
3)利用Flume对数据可靠性的支持,保证了数据在Agent传输中的数据不丢失
1. 首先由一个Channel Queue用于存储整个Channel的Event数据;
2. 每个事务都有一个Take Queue和Put Queue分别用于存储事务相关的取数据和放数据,等事务提交时才完全同步到Channel Queue,或者失败把取数据回滚到Channel Queue。MemoryChannel设计时考虑了两个容量:Channel Queue容量和事务容量,而这两个容量涉及到了数量容量和字节数容量。另外因为多个事务要操作Channel Queue,还要考虑Channel Queue的动态扩容问题,因此MemoryChannel使用了锁来实现,而容量问题则使用了信号量来实现。
图五 Flume Channel的事务性保证
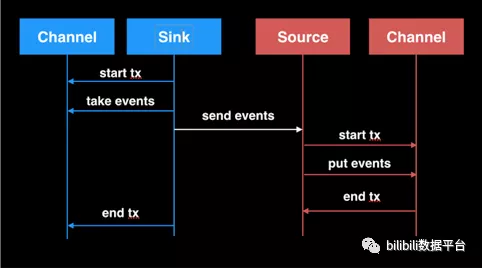
图六 Agent中的数据交换
数据质量性保证
1)没有监控,一切优化都是空谈。实现了单独监控系统,提供了细粒度的监控指标,对数据传输的各个环节进行监控,例如对丢失率、延时率、数据采集量及字节数、模块处理耗时等进行可视化监控
2)全方位的告警机制,数据链路异常会及时通过告警通知相应负责开发同学,快速响应
3)每日统计各类业务数据的日量级和条数,以及产出同比环比报告,方便观察每日线上业务埋点数据情况
4)数据上报样例查看,方便接入的业务方查看自己数据上报格式和数据是否正确

图八 数据上报实时监控
图九 数据同环比监控
监控模块整体架构如下:

图十 Lancer监控模块整体架构
关于具体监控模块的具体设计,不在本文的讨论之中,之后会专门介绍。
未来发展
截止目前,Lancer系统提供了一个高可用,高可靠,可扩展的分布式服务,接入了超过200类数据采集任务,每天处理各类数据超过400亿条,数据量级在20T以上,每秒300W条的处理速度,有效地支持了B站的日志数据收集和分发工作。
后续,我们将在如下方面继续研究:
-
系统的优化:随着业务的不断增长,对系统的要求会越来越高,有更多优化的空间需要去完善;
-
日志管理系统:对日志收集系统Lancer提供图形化的展示和控制,方便管理和配置;
-
拥抱开源:专注数据集成问题方案的思考和解决。
出处:https://mp.weixin.qq.com/s/QXf3iol1WNsXhhi7j-VDtQ
荣誉推荐:www.ya-jing.cn 亚晶投资 www.bn016.com宝牛