人体行为识别:SlowFast Networks for Video Recognition
参考文献:https://arxiv.org/abs/1812.03982
代码实现:https://github.com/facebookresearch/SlowFast
SlowFast Networks for Video Recognition
摘要
我们提出了用于视频识别的SlowFast网络,模型包括:(i)以低帧速率的慢速路径来捕获空间语义;(ii)以高帧速率的快速路径来捕获精细时间分辨率的运动。快速路径可以通过减少通道容量而变得非常轻量级,并且可以学习有用的时间信息用于视频识别。我们的模型在视频中的行为分类和检测方面都取得了很好的性能,并且我们的SlowFast概念也有很大的改进。我们在没有使用任何预训练的情况下,得到Kinetics数据集的准确率为79.0%,AVA数据集的mAP为28.2%。
1 引言
在图像识别I(x,y)中,通常对两个空间维度x和y进行对称处理。这通过自然图像的统计数据证明是合理的,自然图像是各向同性的,即所有方向都是相同的,并且是位移不变的[41,26]。但是视频信号I(x,y,t)呢?运动是方向的时空对应物[2],但所有时空方向的可能性并不相同,慢速动作比快速动作更有可能发生(事实上,我们看到的大多数世界都在某个特定时刻处于静止状态),这一点在贝叶斯描述人类如何感知运动刺激时得到了利用[58]。例如,如果我们看到一个孤立的移动边缘,我们认为它是垂直于自身移动的,即使在原则上它也可能有一个与自身相切的任意运动分量(光流中的孔径问题)。特别是对于慢速动作,这个感知是合理的。
如果所有时空方向的可能性都不一样,那么我们就没有理由像基于时空卷积的视频识别方法(理解:用三维卷积核处理视频的3-Dimensional Convolution方法)所隐含的那样,对称地对待空间和时间。相反,我们可以将架构进行“分解”以单独处理空间结构和时间事件。具体来说,让我们从认知的角度来研究这个问题。一方面,视觉内容的分类空间语义通常发展缓慢,例如,在挥手动作的范围内,挥手不会改变其作为“手”的身份,即使一个人可以从步行过渡到跑步,他/她也始终属于“人”类别。因此分类语义(以及它们的颜色、纹理、光照等)的识别可以相对缓慢地刷新。另一方面,正在执行的动作可以比其主体身份更快的发展,比如拍手、挥手、摇晃、行走或跳跃,可以期望使用快速刷新帧(高时间分辨率)来有效地建模潜在的快速变化运动。
基于这一直觉,我们提出了一个用于视频识别的双路径SlowFast模型(图1)。其中一条路径被设计用来捕获图像或少量稀疏帧所提供的语义信息,它以较低的帧速率和较低的刷新速度运行。相反,另一条路径负责捕捉快速变化的运动,它以快速刷新速度和高时间分辨率运行。尽管该路径的时间速率很高,但它非常轻量级,大约占总计算量的20%。这是因为该路径被设计为具有较少的通道和较弱的处理空间信息的能力,而语义信息可以由第一路径以较少冗余的方式提供。我们称第一个为慢速路径,第二个为快速路径,由它们不同的时间速度驱动,这两条路径通过横向连接而融合。

我们的概念构思可以为视频模型提供灵活有效的设计。快速路径由于其轻量级的特性,不需要执行任何temporal pooling,它可以在所有中间层的高帧速率上操作并保持时间保真度。同时,由于慢速路径具有较低的时间速率,可以更集中于空间域和语义。通过以不同的时间速率处理原始视频,我们的方法允许这两条路径在视频建模方面有自己的专长。
另一种众所周知的视频识别体系结构是双流法[44],与本文相比提供了概念上的不同视角。双流法[44]没有探索不同时间速度的潜力,这是我们方法中的一个关键概念。双流法对两个流采用相同的主干结构,而我们的快速路径更轻。我们的方法不计算光流,因此,我们的模型是从原始数据端到端学习的。在我们的实验中,我们观察到SlowFast网络在经验上更有效。
我们的方法受到灵长类动物视觉系统中视网膜神经节细胞的生物学研究的启发[27,37,8,14,51],尽管这种类比是粗糙和过时的。研究发现,在这些细胞中,大约80%是细小细胞(P细胞),大约15-20%是大细胞(M细胞)。M细胞在高时间频率下工作,对快速时间变化有反应,但对空间细节或颜色不敏感。P细胞提供精细的空间细节和颜色,但时间分辨率较低,对刺激反应缓慢。我们的框架类似于:(i)我们的模型有两条分别在低时间分辨率和高时间分辨率下工作的路径;(ii)我们的快速路径被设计成捕捉快速变化的运动,但空间细节较少,类似于M细胞;(iii)我们的快速路径很轻,类似于M细胞的小比例。我们希望这些关系能启发更多的计算机视觉模型用于视频识别。
我们在Kinetics-400[30]、Kinetics-600[3]、Charades[43]和AVA[20]数据集上评估了我们的方法。我们在Kinetics行为分类数据集上的消融研究证明了SlowFast的有效性。SlowFast网络为所有数据集设置了一个新的技术状态,与文献中以前的系统相比有了显著的提高。
2 相关工作
时空滤波
动作可以表示为时空对象,并通过时空中的定向滤波来捕获,如HOG3D[31]和 cuboids[10]所做的。3D ConvNets[48,49,5]将2D图像模型[32,45,47,24]扩展到时空域,以类似的方式处理空间和时间维度。还有一些相关的方法关注使用时间步长的长期滤波和池[52、13、55、62],以及将卷积分解为单独的2D空间和1D时间滤波器[12、50、61、39]。
除了时空滤波或可分离版本,我们的工作还通过使用两种不同的时间速度来更全面地分离建模专业知识。
用于视频识别的光流
基于光流的手工制作的时空特征是一个经典的研究分支,这些方法包括流动直方图[33]、运动边界直方图[6]和轨迹图[53],在深度学习盛行之前,已经显示出了在动作识别方面的竞争性能。
在深度神经网络的背景下,双流法[44]通过将光流视为另一种输入模式来利用光流。该方法已成为文献〔12, 13, 55〕中许多竞争性结果的基础。然而,由于光流是一种手工设计的特征,并且两种流方法往往不能端到端地学习,因此在方法上并不令人满意。
3 SlowFast网络
SlowFast网络可以被描述为以两种不同帧速率工作的单流架构,但是我们使用路径的概念来源于与生物小细胞和大细胞的类比。我们的通用架构有一个慢速路径(Sec. 3.1)和快速路径(Sec. 3.2),连接组成了SlowFast网络(Sec. 3.3),见图1。
3.1 慢速路径
慢速路径可以是任何卷积模型(例如[12、49、5、56]),它以时空卷的形式在视频剪辑上工作。慢速路径的关键概念是输入帧上的大时间步长 τ τ τ,即它只处理 τ τ τ帧中的一个。我们研究的 τ τ τ的典型值是16。对于30 fps的视频,刷新速度大约为每秒采样2帧。将慢速路径采样的帧数表示为 T T T,原始剪辑长度为 T × τ T×τ T×τ帧。
3.2 快速路径
与慢速路径平行,快速路径是另一个具有以下性质的卷积模型。
高帧速率
我们的目标是在时间维度上有一个很好的表示。我们的快速路径工作在一个小的时间步长 τ / α τ/α τ/α,其中 α > 1 α>1 α>1是快慢路径之间的帧速率比。两条路径在同一个原始片段上操作,因此快速路径采样 α T αT αT帧, α α α是慢速路径的密度的一倍,在我们的实验中的典型值是 α = 8 α=8 α=8。
α是SlowFast概念的关键(图1,时间轴),它明确指出了这两条路径在不同时间速度下工作,从而驱动实例化这两条路径的两个子网的专业知识。
高时间分辨率特征
我们的快速路径不仅具有高帧速率,而且在整个网络层次结构中追求高时间分辨率特性。在我们的实例中,我们在整个快速路径中没有使用时间下采样层(既没有时间池也没有时间步卷积),直到分类之前的全局池层。因此,我们的特征张量总是沿着时间维度有 α T αT αT帧,尽可能地保持时间保真度。
低通道容量
我们的快速路径还与现有模型的区别在于,它可以使用显著更低的通道容量来实现SlowFast模型的良好准确性,具有轻量级。
简而言之,我们的快速路径是一个类似于慢速路径的卷积网络,但具有慢速路径的 β ( β < 1 ) β(β<1) β(β<1)通道的比率。在我们的实验中,典型值是 β = 1 / 8 β=1/8 β=1/8。注意,公共层的计算(浮点数运算或FLOPs)通常是通道缩放比率的二次方,这就是为什么快速路径比慢速路径更具计算效率。在我们的实例中,快速路径通常占总计算量的20%。有趣的是,正如Sec 1.所提到的,有证据表明灵长类动物视觉系统中15-20%的视网膜细胞是M细胞(对快速运动敏感,但对颜色或空间细节不敏感)。
低通道容量也可以解释为表示空间语义的能力较弱。从技术上讲,我们的快速路径在空间维度上没有特殊处理,因此它的空间建模能力应该低于慢速路径,因为通道较少。模型的良好结果表明,在增强快速路径的时间建模能力的同时,削弱快速路径的空间建模能力是一个理想的折衷方案。
基于这种解释,我们还探索了在快速路径中削弱空间容量的不同方法,包括降低输入空间分辨率和去除颜色信息。我们将通过实验证明,这些版本都能提供很好的准确性,这表明可以使具有较小空间容量的轻量级快速通道变得有益。
3.3 横向连接
这两条路径的信息是融合的,因此一条路径需要知道另一条路径所学习的表示。我们通过横向连接来实现这一点,这种连接已被用于融合基于光流的双流网络[12,13]。在图像目标检测中,横向连接[35]是融合不同层次空间分辨率和语义的常用技术。
与[12,35]类似,我们在每个“阶段”的两条路径之间附加一个横向连接(图1)。特别是对于ResNets[24],这些连接位于 p o o l 1 pool_1 pool1、 r e s 2 res_2 res2、 r e s 3 res_3 res3和 r e s 4 res_4 res4之后。这两条路径有不同的时间维度,因此横向连接执行一个转换以匹配它们(详见Sec. 3.4)。我们使用单向连接,将快速路径的特征融合到慢速路径中(图1)。我们进行了双向融合实验,发现了相似的结果。
最后,对每个路径的输出执行全局平均池,将两个合并的特征向量作为全连接分类器层的输入。
3.4 实例化
我们的SlowFast思想是通用的,它可以用不同的骨干网络(例如[45,47,24])和实现细节来实例化。在本小节中,我们将描述网络体系结构的实例。
表1中展示了一个示例的SlowFast模型,我们用 T × S 2 T×S^2 T×S2表示时空尺寸,其中 T T T是时间长度, S S S是高度和宽度,下面将描述详细信息。

慢速路径
表1中的慢速路径是从文献[12]修改得到的时间跨度3D ResNet。它有 T = 4 T=4 T=4帧作为网络输入,从具有时间步幅 τ = 16 τ=16 τ=16的 64 64 64帧原始剪辑中稀疏采样。我们在这个实例中不执行时间下采样,因为这样做在输入步幅较大时是有害的。
与典型的C3D/I3D模型不同,我们仅在 r e s 4 res_4 res4和 r e s 5 res_5 res5中使用non-degenerate时间卷积(时间核大小>1,在表1中加下划线); c o n v 1 conv_1 conv1到 r e s 3 res_3 res3的所有滤波器本质上都是该路径中的2D卷积核。这是基于我们的实验观察,在早期层使用时间卷积会降低准确性。我们认为,这是因为当物体快速移动且时间步幅较大时,除非空间感受野足够大(即在后面的层中),否则时间感受野几乎没有相关性。
快速路径
表1显示了 α = 8 α=8 α=8和 β = 1 / 8 β=1/8 β=1/8的快速路径的示例,它具有更高的时间分辨率(绿色)和更低的通道容量(橙色)。
快速路径在每个block中都有non-degenerate时间卷积。这是因为快速路径具有很好的时间分辨率,能够利用时间卷积捕捉详细的运动。此外,快速路径没有时间下采样层。
横向连接
我们的横向连接融合快速通道和慢速通道,它需要在融合之前匹配特征的大小,慢速路径的特征尺寸为{ T , S 2 , C T,S^2,C T,S2,C},快速路径的特征尺寸为{ α T , S 2 , β C αT,S^2,βC αT,S2,βC}。我们在横向连接中尝试以下转换:
(i) 通道到时间:我们将{ α T , S 2 , β C αT,S^2,βC αT,S2,βC}变形为{ T , S 2 , α β C T,S^2,αβC T,S2,αβC},这意味着我们将所有 α α α帧打包到一个帧的通道中。
(ii)时间跨度采样:我们只需对每个 α α α帧中的一个进行采样,因此{ α T , S 2 , β C αT,S^2,βC αT,S2,βC}变为{ T , S 2 , β C T,S^2,βC T,S2,βC}。
(iii)时间跨度卷积:我们用输出通道 2 β C 2βC 2βC, s t r i d e = α stride=α stride=α, 5 × 1 2 5×1^2 5×12核进行三维卷积。
横向连接的输出通过求和或串联融合到慢速路径中。
4 实验:动作分类
我们使用标准评估协议对四个视频识别数据集进行评估。对于本节中的动作分类实验,我们考虑了广泛使用的Kinetics-400[30]、最近的Kinetics-600[3]和Charades[43]。对于Sec. 5中的动作检测实验,我们使用具有挑战性的AVA数据集[20]。
Kinetics数据集不涉及肢体冲突行为,略……
5 实验:AVA 动作检测
数据集
AVA数据集[20]专注于人类行为的空间和时间定位(简称时空)。数据来自于437部电影,每秒提供一帧时空标签,每个人都用一个边界框和动作(可能是多个动作)进行注释。AVA数据集的难点在于动作检测,而动作定位的挑战性较小[20]。我们使用的AVA v2.1中有211k个训练和57k个验证视频片段,遵循标准协议[20]对60个类进行评估(见图3),性能指标是60个类别的平均精度(mAP),使用0.5的帧级IoU阈值。
检测体系结构
我们的检测器类似于 Faster R-CNN[40],只需对视频进行最小的修改。我们使用SlowFast网络或其变体作为骨干网络,将 r e s 5 res_5 res5的空间步幅设置为1(而不是2),并对其过滤器使用dilation等于2,使得 r e s 5 res_5 res5的空间分辨率提高2倍,在 r e s 5 res_5 res5的最后一个特征图上提取感兴趣区域(RoI)[17]。我们首先通过沿时间轴方向复制每个帧上的2D RoI,将其扩展为3D RoI,类似于[20]中提出的方法。随后,我们通过RoIAlign[22]在空间上计算RoI特征,并在时间上计算全局平均池。最后,对RoI特征进行max-pooled,输入到每个类基于sigmoid的分类器中进行多标签预测。
我们像以前的工作[20,46,29]那样使用预先计算的区域建议,我们的区域建议由现成的人员检测器计算,也就是说,它没有与动作检测模型联合训练。采用Detectron训练的人员检测模型[18],它是一个以ResNeXt-101-FPN[60,35]为骨干网络的Faster R-CNN,在ImageNet和COCO人类关键点图像上预先训练[36]。我们对AVA数据集上的检测器进行微调,以便进行人员检测。人员检测器在AVA验证集上实现93.9 AP@50,能够检测出置信度大于0.8、召回率为91.1%、准确率为90.7%的人员框作为动作检测的区域建议。
训练
我们从Kinetics-400分类模型中初始化网络权重。我们使用step-wise学习率,当验证误差饱和时,学习率降低10倍。我们训练了14k次iterations(68个epochs,大约211k数据),前1k次iterations执行学习率线性warm-up[19]。我们使用 1 0 − 7 10^{-7} 10−7的权重衰减。所有其他超参数与Kinetics实验相同。Ground-truth boxes作为训练样本。输入是大小为224×224的特定于实例的 α T × τ αT×τ αT×τ帧。
推理
我们对单个剪辑的 α T × τ αT×τ αT×τ帧进行推理。我们调整空间维度的大小,使其较短的边为256像素。骨干特征提取器是完全卷积,如标准的Faster R-CNN[40]。
5.1 主要结果
我们方法与之前方法在AVA数据集下的比较见表7。一个有趣的观察是使用光流具有潜在的好处(见表7中的“flow”列),现有的工作已经得到轻微的改进,文献[20]中I3D增长+1.1 mAP,文献[29]中ATR增长+1.7 mAP。相比之下,我们的baseline通过快速路径提高了+5.2 mAP(见下一节消融实验中的表9)。此外,双流法存在的两种流使得计算成本加倍,而我们的快速路径是轻量级的。
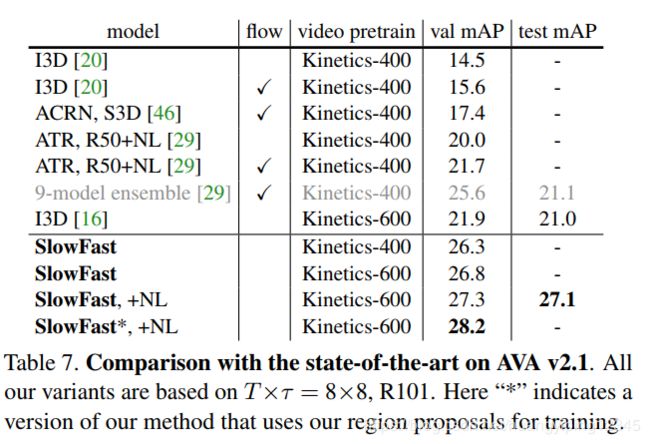
作为系统级比较,我们的SlowFast模型在仅仅使用Kinetics-400预训练下,只有26.3 mAP。这比先前方法的最佳值(ATR[29]中的21.7,单模型)高5.6 mAP,比不使用光流的情况(表7)高7.3 mAP。
文献[16]在更大的Kinetics-600预训练模型上进行训练,达到21.9 mAP。为了进行公平的比较,我们观察到使用Kinetics-600预训练模型时从26.3 mAP改进到26.8 mAP。在SlowFast上增加NL blocks[56]增加到27.3 mAP,我们在train+val上训练这个模型(并延长1.5倍),在AVA v2.1 test下测试[34]达到27.1 mAP。
以预测方案与ground-truth boxes重叠IoU>0.9为衡量标准,获得28.2 mAP,是AVA的最新技术。
使用AVA v2.2数据集(它提供了更一致的注释)可以将这个数字提高到29.0 mAP(表8)。The longer-term SlowFast, 16×8 model得到29.8 mAP,并利用多个空间尺度和水平翻转进行测试,这个数字增加到30.7 mAP。

最后,我们创建了7个模型的集成,并将其提交给2019年ActivityNet挑战赛的官方测试服务器[1]。如表8所示,(SlowFast++,ensemble)在测试集上达到34.3 mAP,在2019年AVA动作检测挑战赛中排名第一。有关我们获胜解决方案的更多详细信息,请参见相应的技术报告[11]。
5.2 消融实验
表9比较了SlowFast的Slow-only基线和SlowFast,以及图3所示的每类AP。我们的方法从19.0提高到24.2,提高了5.2 mAP(相对28%)。


从分类的角度来看(图3),我们的SlowFast模型比Slow-only基线模型改进了60个分类中的57个。“拍手”(+27.7 AP)、“游泳”(+27.4 AP)、“跑步/慢跑”(+18.8 AP)、“跳舞”(+15.9 AP)和“吃饭”(+12.5 AP)的绝对收益最大。我们还观察到“跳跃/跳跃”、“挥手”、“放下”、“投掷”、“击中”或“切割”的相对增加。SlowFast模型只在3个类别中更差:“接听电话”(-0.1 AP)、“撒谎/睡觉”(-0.2 AP)、“射击”(-0.4 AP),与其他类别相比,它们的下降幅度相对较小。
6 结论
时间轴是一个特殊的维度,本文设计了慢速路径和快速路径融合的SlowFast网络,实现了最先进的视频动作分类和检测精度。
附录
略……