基于Django的个人博客系统开发
文章目录
- 1.创建虚拟环境
- 2.pycharm创建django项目:
- 3.创建静态文件,配置settings.py,配置模板
- 4.django中配置日志器
- 5.网站的基本信息配置
- 6.数据库的设计
- 7.Django Models的设计和使用,配置mysql.
- 8. admin的配置
- 9.增加富文本编辑器
- 10.上传文件
- 11.模板的规划和设计
- 12.分页器
- 13.django执行sql语句
- 14.自定义Manager管理器
- 15.代码的重构
- 16.部署上线
1.创建虚拟环境
1)conda create -n project_blog python=2.7
2)激活环境:activate project_blog,然后安装django
pip install django

2.pycharm创建django项目:

设置项目名称和app名称:

安装相关库:

3.创建静态文件,配置settings.py,配置模板


在static目录下粘贴前端界面文件(网上找的前端文件):

在templates下粘贴index.html文件(网上找的资料文件):

配置urls.py文件,views.py文件
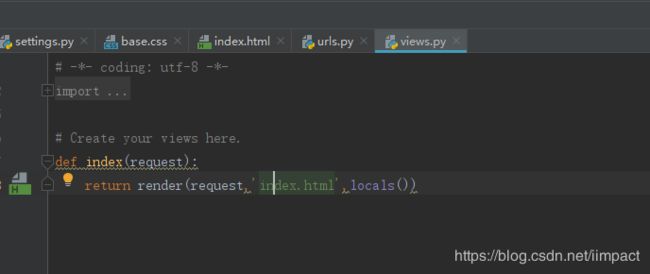

4.django中配置日志器
在settings.py中加入如下文件:
# 自定义日志输出信息
LOGGING = {
'version': 1,
'disable_existing_loggers': True,
'formatters': {
'standard': {
'format': '%(asctime)s [%(threadName)s:%(thread)d] [%(name)s:%(lineno)d] [%(module)s:%(funcName)s] [%(levelname)s]- %(message)s'} #日志格式
},
'filters': {
},
'handlers': {
'mail_admins': {
'level': 'ERROR',
'class': 'django.utils.log.AdminEmailHandler',
'include_html': True,
},
'default': {
'level':'DEBUG',
'class':'logging.handlers.RotatingFileHandler',
'filename': 'log/all.log', #日志输出文件
'maxBytes': 1024*1024*5, #文件大小
'backupCount': 5, #备份份数
'formatter':'standard', #使用哪种formatters日志格式
},
'error': {
'level':'ERROR',
'class':'logging.handlers.RotatingFileHandler',
'filename': 'log/error.log',
'maxBytes':1024*1024*5,
'backupCount': 5,
'formatter':'standard',
},
'console':{
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'standard'
},
'request_handler': {
'level':'DEBUG',
'class':'logging.handlers.RotatingFileHandler',
'filename': 'log/script.log',
'maxBytes': 1024*1024*5,
'backupCount': 5,
'formatter':'standard',
},
'scprits_handler': {
'level':'DEBUG',
'class':'logging.handlers.RotatingFileHandler',
'filename':'log/script.log',
'maxBytes': 1024*1024*5,
'backupCount': 5,
'formatter':'standard',
}
},
'loggers': {
'django': {
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': False
},
'django.request': {
'handlers': ['request_handler'],
'level': 'DEBUG',
'propagate': False,
},
'scripts': {
'handlers': ['scprits_handler'],
'level': 'INFO',
'propagate': False
},
'blog.views': {
'handlers': ['default', 'error'],
'level': 'DEBUG',
'propagate': True
},
}
}
新建log目录:
日志器使用实例:在views.py中添加代码

运行上述程序或者在浏览器访问网站后,会在log目录下生成错误日志文件。
5.网站的基本信息配置
在settings.py中加入以下代码:

在views.py中加入如下代码:

在settings.py中加入以下代码:
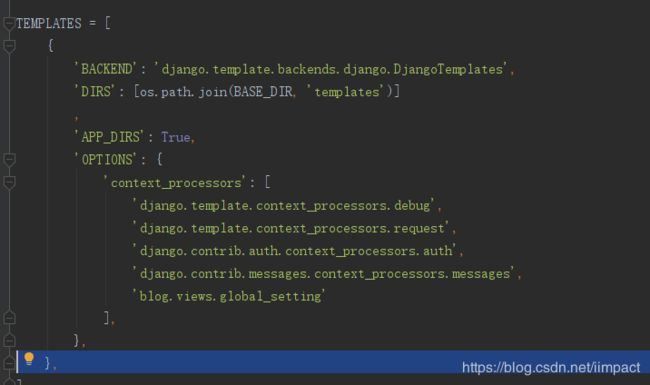
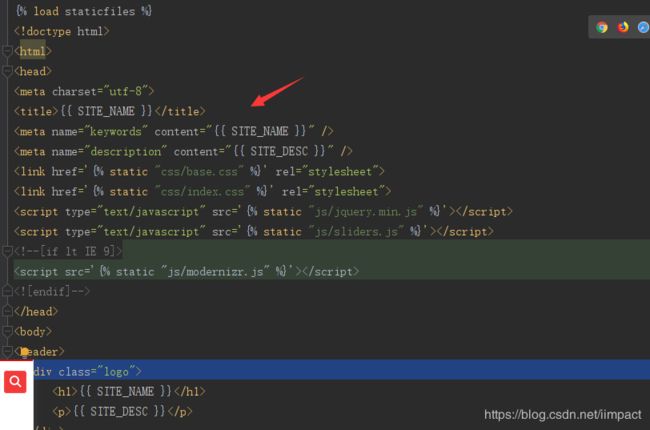
上面的配置信息就成了全局变量,可以在任意一处如index.html中引用
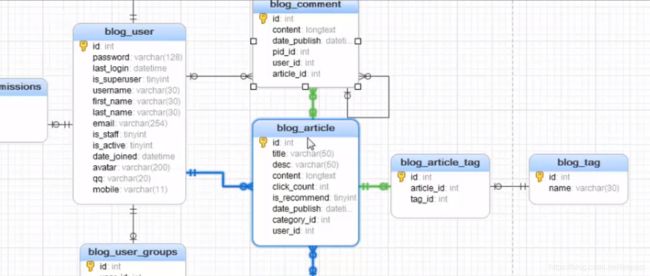
6.数据库的设计
1)数据库的设计主要是针对一个特定的环境,为了能够满足有效的数据存储和处理等要求,
需要构造最优的数据库模式来建立数据库及其对应系统。
7.Django Models的设计和使用,配置mysql.
编写models.py如下:
# -*- coding: utf-8 -*-
from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
# 用户模型.
# 第一种:采用的继承方式扩展用户信息(本系统采用)
# 扩展:关联的方式去扩展用户信息
class User(AbstractUser):
avatar = models.ImageField(upload_to='avatar/%Y/%m', default='avatar/default.png', max_length=200, blank=True, null=True, verbose_name='用户头像')
qq = models.CharField(max_length=20, blank=True, null=True, verbose_name='QQ号码')
mobile = models.CharField(max_length=11, blank=True, null=True, unique=True, verbose_name='手机号码')
url = models.URLField(max_length=100, blank=True, null=True, verbose_name='个人网页地址')
class Meta:
verbose_name = '用户'
verbose_name_plural = verbose_name
ordering = ['-id']
def __unicode__(self):
return self.username
# tag(标签)
class Tag(models.Model):
name = models.CharField(max_length=30, verbose_name='标签名称')
class Meta:
verbose_name = '标签'
verbose_name_plural = verbose_name
def __unicode__(self):
return self.name
# 分类
class Category(models.Model):
name = models.CharField(max_length=30, verbose_name='分类名称')
index = models.IntegerField(default=999,verbose_name='分类的排序')
class Meta:
verbose_name = '分类'
verbose_name_plural = verbose_name
ordering = ['index', 'id']
def __unicode__(self):
return self.name
# 自定义一个文章Model的管理器
# 1、新加一个数据处理的方法
# 2、改变原有的queryset
class ArticleManager(models.Manager):
def distinct_date(self):
distinct_date_list = []
date_list = self.values('date_publish')
for date in date_list:
date = date['date_publish'].strftime('%Y/%m文章存档')
if date not in distinct_date_list:
distinct_date_list.append(date)
return distinct_date_list
# 文章模型
class Article(models.Model):
title = models.CharField(max_length=50, verbose_name='文章标题')
desc = models.CharField(max_length=50, verbose_name='文章描述')
content = models.TextField(verbose_name='文章内容')
click_count = models.IntegerField(default=0, verbose_name='点击次数')
is_recommend = models.BooleanField(default=False, verbose_name='是否推荐')
date_publish = models.DateTimeField(auto_now_add=True, verbose_name='发布时间')
user = models.ForeignKey(User, verbose_name='用户')
category = models.ForeignKey(Category, blank=True, null=True, verbose_name='分类')
tag = models.ManyToManyField(Tag, verbose_name='标签')
objects = ArticleManager()
class Meta:
verbose_name = '文章'
verbose_name_plural = verbose_name
ordering = ['-date_publish']
def __unicode__(self):
return self.title
# 评论模型
class Comment(models.Model):
content = models.TextField(verbose_name='评论内容')
username = models.CharField(max_length=30, blank=True, null=True, verbose_name='用户名')
email = models.EmailField(max_length=50, blank=True, null=True, verbose_name='邮箱地址')
url = models.URLField(max_length=100, blank=True, null=True, verbose_name='个人网页地址')
date_publish = models.DateTimeField(auto_now_add=True, verbose_name='发布时间')
user = models.ForeignKey(User, blank=True, null=True, verbose_name='用户')
article = models.ForeignKey(Article, blank=True, null=True, verbose_name='文章')
pid = models.ForeignKey('self', blank=True, null=True, verbose_name='父级评论')
class Meta:
verbose_name = '评论'
verbose_name_plural = verbose_name
def __unicode__(self):
return str(self.id)
# 友情链接
class Links(models.Model):
title = models.CharField(max_length=50, verbose_name='标题')
description = models.CharField(max_length=200, verbose_name='友情链接描述')
callback_url = models.URLField(verbose_name='url地址')
date_publish = models.DateTimeField(auto_now_add=True, verbose_name='发布时间')
index = models.IntegerField(default=999, verbose_name='排列顺序(从小到大)')
class Meta:
verbose_name = '友情链接'
verbose_name_plural = verbose_name
ordering = ['index', 'id']
def __unicode__(self):
return self.title
# 广告
class Ad(models.Model):
title = models.CharField(max_length=50, verbose_name='广告标题')
description = models.CharField(max_length=200, verbose_name='广告描述')
image_url = models.ImageField(upload_to='ad/%Y/%m', verbose_name='图片路径')
callback_url = models.URLField(null=True, blank=True, verbose_name='回调url')
date_publish = models.DateTimeField(auto_now_add=True, verbose_name='发布时间')
index = models.IntegerField(default=999, verbose_name='排列顺序(从小到大)')
class Meta:
verbose_name = u'广告'
verbose_name_plural = verbose_name
ordering = ['index', 'id']
def __unicode__(self):
return self.title
改写settings.py中数据库配置:

删除原来的db.sqlite3数据库。
在settings.py中加一行:

安装mySQL5.6:下载地址
创建blogdb数据库:
mysql> CREATE DATABASE blogdb DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;

安装mysql-python包:

点击tools->run mange命令生成数据库:

执行下面的命令:

结果:

执行migrate命令映射表:

执行createsuperuser命令创建管理员账号。

8. admin的配置
1)Django的管理员模块是Django的标准库django.contrib的一部分,
contrib下还包括django.contrib.auth,django.contrib.sessions和
django.contrib.comments模块等,django.contrib.admin
2)配置步骤
在INSTALLED_APPS中添加django.contrib.admin
配置urls.py :url(r’^admin/’, include(admin.site.urls))
在admin注册的Model,(默认方式和自定义方式),注意model中关于admin的一些配置
3) 执行migrate admin命令。
2.登陆进admin界面:
在admins.py下添加如下代码:
# -*- coding:utf-8 -*-
from django.contrib import admin
from models import *
# Register your models here.
class ArticleAdmin(admin.ModelAdmin):
list_display = ('title', 'desc', 'click_count',)
list_display_links = ('title', 'desc', )
list_editable = ('click_count',)
fieldsets = (
(None, {
'fields': ('title', 'desc', 'content', 'user', 'category', 'tag', )
}),
('高级设置', {
'classes': ('collapse',),
'fields': ('click_count', 'is_recommend',)
}),
)
class Media:
js = (
'/static/js/kindeditor-4.1.10/kindeditor-min.js',
'/static/js/kindeditor-4.1.10/lang/zh_CN.js',
'/static/js/kindeditor-4.1.10/config.js',
)
admin.site.register(User)
admin.site.register(Tag)
admin.site.register(Article, ArticleAdmin)
admin.site.register(Category)
admin.site.register(Comment)
admin.site.register(Links)
admin.site.register(Ad)
刷新网页,出现model内容:

9.增加富文本编辑器
1.下载kineditor,解压拷贝进项目中:
2.定义ModelAdmin的媒体文件
增加admin.py代码:

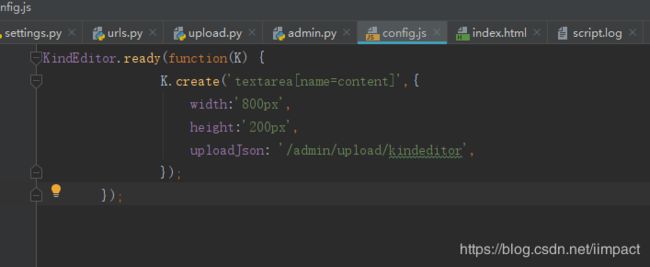
3.修改kineditor的配置文件
新建config.js输入以下内容:
KindEditor.ready(function(K) {
K.create('textarea[name=content]',{
width:'800px',
height:'200px',
uploadJson: '/admin/upload/kindeditor',
});
});

10.上传文件
1.新建uploads目录,在settings.py中配置MEDIA_URL和MEDIA_ROOT


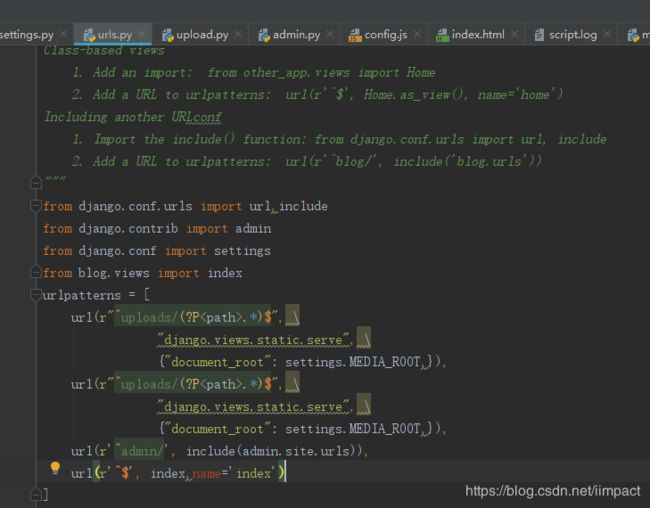
2.urls.py中配置路由
url(r"^uploads/(?P.*)$", django.views.static.serve, {"document_root":settings.MEDIA_ROOT,}),

3、在model中设置图片的上传位置和路径
新建uploads.py文件:

输入以下内容:
# -*- coding: utf-8 -*-
from django.http import HttpResponse
from django.conf import settings
from django.views.decorators.csrf import csrf_exempt
import os
import uuid
import json
import datetime as dt
@csrf_exempt
def upload_image(request, dir_name):
##################
# kindeditor图片上传返回数据格式说明:
# {"error": 1, "message": "出错信息"}
# {"error": 0, "url": "图片地址"}
##################
result = {"error": 1, "message": "上传出错"}
files = request.FILES.get("imgFile", None)
if files:
result =image_upload(files, dir_name)
return HttpResponse(json.dumps(result), content_type="application/json")
#目录创建
def upload_generation_dir(dir_name):
today = dt.datetime.today()
dir_name = dir_name + '/%d/%d/' %(today.year,today.month)
if not os.path.exists(settings.MEDIA_ROOT + dir_name):
os.makedirs(settings.MEDIA_ROOT + dir_name)
return dir_name
# 图片上传
def image_upload(files, dir_name):
#允许上传文件类型
allow_suffix =['jpg', 'png', 'jpeg', 'gif', 'bmp']
file_suffix = files.name.split(".")[-1]
if file_suffix not in allow_suffix:
return {"error": 1, "message": "图片格式不正确"}
relative_path_file = upload_generation_dir(dir_name)
path=os.path.join(settings.MEDIA_ROOT, relative_path_file)
if not os.path.exists(path): #如果目录不存在创建目录
os.makedirs(path)
file_name=str(uuid.uuid1())+"."+file_suffix
path_file=os.path.join(path, file_name)
file_url = settings.MEDIA_URL + relative_path_file + file_name
open(path_file, 'wb').write(files.file.read()) # 保存图片
return {"error": 0, "url": file_url}
配置url:
配置conf.js:
11.模板的规划和设计
1、模板的规划和设计
2、导航数据获取(分类)
技术点:
1、如何拆分一个模板,如何抽离出base模板,
如何规划和设计模板中的block,以及include的使用
(一些比较公用的模块可以单独抽离出来,并通过include调用),比如广告
12.分页器
功能点:
1、广告数据获取
2、最新文章数据获取(分页)
技术点:
1、查询的基本操作,all()
补充知识点:
a、QuerySet[:1],这种方式是查询所有的结果再取其中一条数据,还是只从数据库中取了一条
b、怎么理解QuerySet的查询是惰性的(当我们去执行all,filter,get,是不会去执行sql的,
当我们去调用查询结果集的时候会执行sql)
2、分页器Paginator的使用
3、locals()函数的使用:所有局部变量封装
4、过滤器的使用

13.django执行sql语句
1、文章归档
技术点:
1、使用filter()进行查询
2、values(),distinct()的使用
3、django中直接使用sql的两种方式
SELECT DISTINCT DATE_FORMAT(date_publish, ‘%Y-%m’) as col_date FROM blog_article ORDER BY date_publish
3.1、raw (异常:Raw query must include the primary key,返回结果必须包含主键)
3.2、excute
直接执行sql资料参考:
https://docs.djangoproject.com/en/1.8/topics/db/sql/
14.自定义Manager管理器
1.尝试用优雅的方式解决一些数据处理上的问题
自定义Manager管理器
管理器资料参考:
https://docs.djangoproject.com/en/1.8/topics/db/managers/
15.代码的重构
功能点:
1、考虑一些代码的重构
2、文章排行(浏览排行、评论排行,推荐排行)
3、标签云
4、友情链接
5、标签列表页面
技术点:
1、order_by的使用,限制取出的数据条数
2、使用filter()进行查询
3、重构的概念:
对软件内部结构的一种调整,目的是在不改变"软件之可察行为"前提下,
提高其可理解性,可重用性,降低其修改成本.
3.1、分页代码的重构
3.2、urls.py路由的重构
3.3、全局公用的一些代码的重构
聚合函数的使用:
https://docs.djangoproject.com/en/1.8/topics/db/aggregation/
新增一个urls文件:
views.py:
# -*- coding: utf-8 -*-
import logging
from django.shortcuts import render, redirect, HttpResponse
from django.core.urlresolvers import reverse
from django.conf import settings
from django.contrib.auth import logout, login, authenticate
from django.contrib.auth.hashers import make_password
from django.core.paginator import Paginator, InvalidPage, EmptyPage, PageNotAnInteger
from django.db import connection
from django.db.models import Count
from models import *
from forms import *
import json
logger = logging.getLogger('blog.views')
# Create your views here.
def global_setting(request):
# 站点基本信息
SITE_URL = settings.SITE_URL
SITE_NAME = settings.SITE_NAME
SITE_DESC = settings.SITE_DESC
# 分类信息获取(导航数据)
category_list = Category.objects.all()[:6]
# 文章归档数据
archive_list = Article.objects.distinct_date()
# 评论排行
comment_count_list = Comment.objects.values('article').annotate(comment_count=Count('article')).order_by('-comment_count')
article_comment_list = [Article.objects.get(pk=comment['article']) for comment in comment_count_list]
return locals()
def index(request):
try:
# 最新文章数据
article_list = Article.objects.all()
article_list = getPage(request, article_list)
# 文章归档
# 1、先要去获取到文章中有的 年份-月份 2015/06文章归档
# 使用values和distinct去掉重复数据(不可行)
# print Article.objects.values('date_publish').distinct()
# 直接执行原生sql呢?
# 第一种方式(不可行)
# archive_list =Article.objects.raw('SELECT id, DATE_FORMAT(date_publish, "%%Y-%%m") as col_date FROM blog_article ORDER BY date_publish')
# for archive in archive_list:
# print archive
# 第二种方式(不推荐)
# cursor = connection.cursor()
# cursor.execute("SELECT DISTINCT DATE_FORMAT(date_publish, '%Y-%m') as col_date FROM blog_article ORDER BY date_publish")
# row = cursor.fetchall()
# print row
except Exception as e:
print e
logger.error(e)
return render(request, 'index.html', locals())
def archive(request):
try:
# 先获取客户端提交的信息
year = request.GET.get('year', None)
month = request.GET.get('month', None)
article_list = Article.objects.filter(date_publish__icontains=year+'-'+month)
article_list = getPage(request, article_list)
except Exception as e:
logger.error(e)
return render(request, 'archive.html', locals())
# 按标签查询对应的文章列表
def tag(request):
try:
# 同学们自己实现该功能
pass
except Exception as e:
logger.error(e)
return render(request, 'archive.html', locals())
# 分页代码
def getPage(request, article_list):
paginator = Paginator(article_list, 2)
try:
page = int(request.GET.get('page', 1))
article_list = paginator.page(page)
except (EmptyPage, InvalidPage, PageNotAnInteger):
article_list = paginator.page(1)
return article_list
# 文章详情
def article(request):
try:
# 获取文章id
id = request.GET.get('id', None)
try:
# 获取文章信息
article = Article.objects.get(pk=id)
except Article.DoesNotExist:
return render(request, 'failure.html', {'reason': '没有找到对应的文章'})
# 评论表单
comment_form = CommentForm({'author': request.user.username,
'email': request.user.email,
'url': request.user.url,
'article': id} if request.user.is_authenticated() else{'article': id})
# 获取评论信息
comments = Comment.objects.filter(article=article).order_by('id')
comment_list = []
for comment in comments:
for item in comment_list:
if not hasattr(item, 'children_comment'):
setattr(item, 'children_comment', [])
if comment.pid == item:
item.children_comment.append(comment)
break
if comment.pid is None:
comment_list.append(comment)
except Exception as e:
print e
logger.error(e)
return render(request, 'article.html', locals())
# 提交评论
def comment_post(request):
try:
comment_form = CommentForm(request.POST)
if comment_form.is_valid():
#获取表单信息
comment = Comment.objects.create(username=comment_form.cleaned_data["author"],
email=comment_form.cleaned_data["email"],
url=comment_form.cleaned_data["url"],
content=comment_form.cleaned_data["comment"],
article_id=comment_form.cleaned_data["article"],
user=request.user if request.user.is_authenticated() else None)
comment.save()
else:
return render(request, 'failure.html', {'reason': comment_form.errors})
except Exception as e:
logger.error(e)
return redirect(request.META['HTTP_REFERER'])
# 注销
def do_logout(request):
try:
logout(request)
except Exception as e:
print e
logger.error(e)
return redirect(request.META['HTTP_REFERER'])
# 注册
def do_reg(request):
try:
if request.method == 'POST':
reg_form = RegForm(request.POST)
if reg_form.is_valid():
# 注册
user = User.objects.create(username=reg_form.cleaned_data["username"],
email=reg_form.cleaned_data["email"],
url=reg_form.cleaned_data["url"],
password=make_password(reg_form.cleaned_data["password"]),)
user.save()
# 登录
user.backend = 'django.contrib.auth.backends.ModelBackend' # 指定默认的登录验证方式
login(request, user)
return redirect(request.POST.get('source_url'))
else:
return render(request, 'failure.html', {'reason': reg_form.errors})
else:
reg_form = RegForm()
except Exception as e:
logger.error(e)
return render(request, 'reg.html', locals())
# 登录
def do_login(request):
try:
if request.method == 'POST':
login_form = LoginForm(request.POST)
if login_form.is_valid():
# 登录
username = login_form.cleaned_data["username"]
password = login_form.cleaned_data["password"]
user = authenticate(username=username, password=password)
if user is not None:
user.backend = 'django.contrib.auth.backends.ModelBackend' # 指定默认的登录验证方式
login(request, user)
else:
return render(request, 'failure.html', {'reason': '登录验证失败'})
return redirect(request.POST.get('source_url'))
else:
return render(request, 'failure.html', {'reason': login_form.errors})
else:
login_form = LoginForm()
except Exception as e:
logger.error(e)
return render(request, 'login.html', locals())
def category(request):
try:
# 先获取客户端提交的信息
cid = request.GET.get('cid', None)
try:
category = Category.objects.get(pk=cid)
except Category.DoesNotExist:
return render(request, 'failure.html', {'reason': '分类不存在'})
article_list = Article.objects.filter(category=category)
article_list = getPage(request, article_list)
except Exception as e:
logger.error(e)
return render(request, 'category.html', locals())
16.部署上线
常见的部署方式:
1、nginx+uwsgi
2、nginx+gunicorn
3、nginx+tornado
4、apache+wsgi
5、…
sae注意事项:
1、需要单独将你自己用到的环境传上去
2、需要停止日志器和图片上传(sae不支持写入,要用它特定的方式才能写入)
3、配置mysql信息,并导出mysql(http://sae.sina.com.cn/doc/python/mysql.html)
4、配置域名到settings.py(ALLOWED_HOSTS),关闭调试页面
5、配置静态文件
sae文档(python):
http://sae.sina.com.cn/doc/python/index.html