caffe添加PrecisionRecallLosslayer层(一)
This is a post outlining the steps you need to take to create your own layer in CAFFE, a popular framework for writing convolutional neural networks. The post focuses on the latest version of CAFE as of Jan 2015.
NOTES:
- I use $CAFFEROOT and /caffe/ interchangeably, this is simply the root directory of the caffe installation.
A general and slightly outdated tutorial can be found here (https://github.com/BVLC/caffe/wiki/Development).
- Create the definition a new class in one of the .hpp files located in $CAFFEROOT/include/caffe/ . In my case, I am writing a customized convolution layer. As a result, I modify thevision_layers.hpp to add a definition of myConvLayer.
- Next we need to create a myConvLayer.cpp file in the following path $CAFFEROOT/src/caffe/myConvLayer.cpp .
- Implement the virtual methods required of the class. In my case, I needed to implement the required “LayerSetUp”, “Reshape”,”ForwardCPU” and “BackwardCPU”.
- Choose a name for your layer and write it in caffe/src/caffe/proto/caffe.proto
- Find a message called LayerParameter
- Find the latest unoccupied number, there should be a comment above the message declaration saying “the next available ID when you create….”, use the smallestUnoccupiedNumber
- Add your layer to the LayerType enum, for example, I add “MYCONVOLUTIONLAYER = 38”
- If you have completed step 1 and step 2, you should be able to just compile the entire CAFFE directory fine. The next steps will require you to actually write a network and run it to get the protobuf set up right. To do this, I recommend simply use an existing network. I chose MNIST LENET and replaced the convolution layer in (/caffe/examples/mnist_modified/lenet_train_test.protxt). To get it to run with my own set up, I
- Created a modified directory(mint_modified) that copies minist in examples.
- Change the lent_solver.prototxt to use my own file. CAFFE used hardcoded path, when it should have used relative path to find the training configuration set up.
- TYPE = MYCONVOLUTION (depending on your declaration in the protobuf file in the previous step)
- Once you are done getting your own layer running within an existing network, it will crash immediately because we haven’t worked on getting
- Dealing with protobuf and layer_factory
- Now you should see an error massage saying “unknown type 38” from a file called “layer_factory.cpp”. You can find the file at caffe/src/caffe/layer_factory.cpp. The error message tells you that currently CAFFE cannot recognize the parameter specified in the protobuf file “myconvolution”. To do this, you simply need to add a new case statement at the end of “layer_factory.cpp” file.
- case LayerParameter_LayerType_MYCONVOLUTION:return new MyConvolutionLayer
(param); - This statement tells the system to use layer_factory to create the class whenever that parameter is being read
- The last part is to make sure that your own layers is using the parameters that you want.
- An interesting note here is that the parameter has no fixed paring. The way it is specified in protobuf file for example, is nesting a parameter type within a layer type. As a result, you can switch the parameters among different layers. That is I could have used the original convolution_parameter inside MyConvolution layer.
- To use my own set of parameter, I went back to caffe/src/caffe/proto/caffe.proto file
- Define a new parameter type
- “myconvolution_param = 42”
- Define a new message class
- MyConvolutionPoolingParameter { optional uint32 num_output =1; …. }
- Then go back to the lenet_train_test.protxt file and set your layer to use the my convolution parameter in myconvolutionpooling layer.
- An example layers { name:’myconv1′ type:MYCONVOLUTION; ….. myconvolution_param { num_output: 20 kernel_size ….}}
- One last step is modifying the $CAFFEROOT/src/caffe/myConvLayer.cpp to use the my convolution_param. You can access the parameters by coding “ConvolutionPoolingParameter convpool_param = this->layer_param_.convolutionpooling_param();”
- Define a new parameter type
===============================================================================================================================
先就按照tangwei2014 学习了一下triplet loss。感谢tangwei博主
===============================================================================================================================
【前言】
最近,learning to rank 的思想逐渐被应用到很多领域,比如google用来做人脸识别(faceNet),微软Jingdong Wang 用来做 person-reid 等等。learning to rank中其中重要的一个步骤就是找到一个好的similarity function,而triplet loss是用的非常广泛的一种。
【理解triplet】
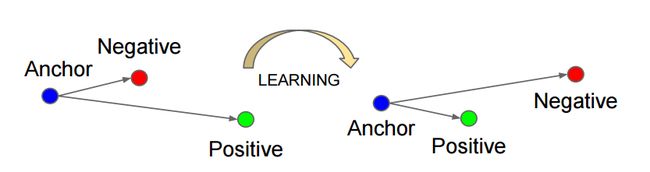
如上图所示,triplet是一个三元组,这个三元组是这样构成的:从训练数据集中随机选一个样本,该样本称为Anchor,然后再随机选取一个和Anchor (记为x_a)属于同一类的样本和不同类的样本,这两个样本对应的称为Positive (记为x_p)和Negative (记为x_n),由此构成一个(Anchor,Positive,Negative)三元组。
【理解triplet loss】
有了上面的triplet的概念, triplet loss就好理解了。针对三元组中的每个元素(样本),训练一个参数共享或者不共享的网络,得到三个元素的特征表达,分别记为: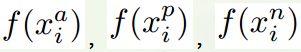 。triplet loss的目的就是通过学习,让x_a和x_p特征表达之间的距离尽可能小,而x_a和x_n的特征表达之间的距离尽可能大,并且要让x_a与x_n之间的距离和x_a与x_p之间的距离之间有一个最小的间隔
。triplet loss的目的就是通过学习,让x_a和x_p特征表达之间的距离尽可能小,而x_a和x_n的特征表达之间的距离尽可能大,并且要让x_a与x_n之间的距离和x_a与x_p之间的距离之间有一个最小的间隔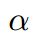 。公式化的表示就是:
。公式化的表示就是: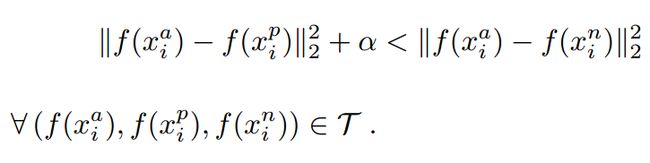
对应的目标函数也就很清楚了: 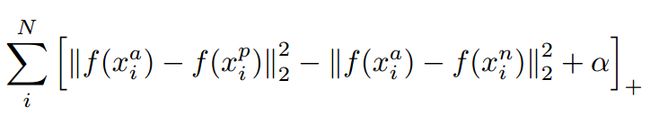
这里距离用欧式距离度量,+表示[]内的值大于零的时候,取该值为损失,小于零的时候,损失为零。
由目标函数可以看出:
- 当x_a与x_n之间的距离 < x_a与x_p之间的距离加
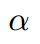 时,[]内的值大于零,就会产生损失。
时,[]内的值大于零,就会产生损失。 - 当x_a与x_n之间的距离 >= x_a与x_p之间的距离加
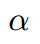 时,损失为零。
时,损失为零。
【triplet loss 梯度推导】
上述目标函数记为L。则当第i个triplet损失大于零的时候,仅就上述公式而言,有: 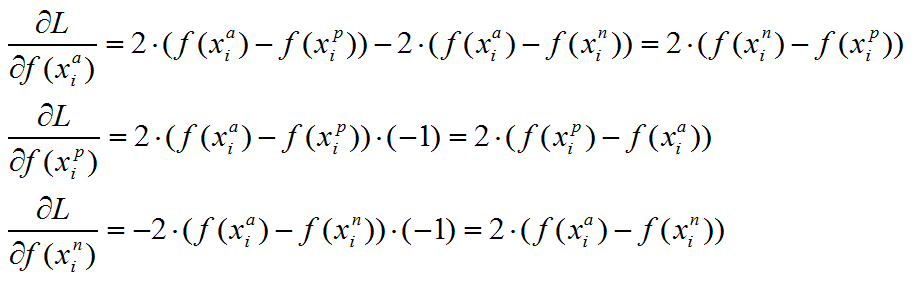
【算法实现时候的提示】
可以看到,对x_p和x_n特征表达的梯度刚好利用了求损失时候的中间结果,给的启示就是,如果在CNN中实现 triplet loss layer, 如果能够在前向传播中存储着两个中间结果,反向传播的时候就能避免重复计算。这仅仅是算法实现时候的一个Trick。
================================================================================================================
1.在~/caffe/src/caffe/proto/caffe.proto中增加triplet loss layer的定义
首先在message LayerParameter中追加 optional TripletLossParameter triplet_loss_param = 138;
其次添加message TripletLossParameter类:
message TripletLossParameter {
// margin for dissimilar pair
optional float margin = 1 [default = 1.0];
}
2.在./include/caffe/loss_layers.hpp中增加triplet loss layer的类的声明
/**
* @brief Computes the triplet loss
*/
template
class TripletLossLayer : public LossLayer {
public:
explicit TripletLossLayer(const LayerParameter& param)
: LossLayer(param){}
virtual void LayerSetUp(const vector*>& bottom,
const vector*>& top);
virtual inline int ExactNumBottomBlobs() const { return 4; }
virtual inline const char* type() const { return "TripletLoss"; }
/**
* Unlike most loss layers, in the TripletLossLayer we can backpropagate
* to the first three inputs.
*/
virtual inline bool AllowForceBackward(const int bottom_index) const {
return bottom_index != 3;
}
protected:
virtual void Forward_cpu(const vector*>& bottom,
const vector*>& top);
virtual void Forward_gpu(const vector*>& bottom,
const vector*>& top);
virtual void Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
virtual void Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom);
Blob diff_ap_; // cached for backward pass
Blob diff_an_; // cached for backward pass
Blob diff_pn_; // cached for backward pass
Blob diff_sq_ap_; // cached for backward pass
Blob diff_sq_an_; // tmp storage for gpu forward pass
Blob dist_sq_ap_; // cached for backward pass
Blob dist_sq_an_; // cached for backward pass
Blob summer_vec_; // tmp storage for gpu forward pass
Blob dist_binary_; // tmp storage for gpu forward pass
};
3. 在./src/caffe/layers/目录下新建triplet_loss_layer.cpp,实现类
主要实现三个功能:
LayerSetUp:主要是做一些CHECK工作,然后根据bottom和top对类中的数据成员初始化。
Forward_cpu:前传,计算loss
Backward_cpu:反传,计算梯度。
/*
* triplet_loss_layer.cpp
*
* Created on: Jun 2, 2015
* Author: tangwei
*/
#include
#include
#include "caffe/layer.hpp"
#include "caffe/loss_layers.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/math_functions.hpp"
namespace caffe {
template
void TripletLossLayer::LayerSetUp(
const vector*>& bottom, const vector*>& top) {
LossLayer::LayerSetUp(bottom, top);
CHECK_EQ(bottom[0]->num(), bottom[1]->num());
CHECK_EQ(bottom[1]->num(), bottom[2]->num());
CHECK_EQ(bottom[0]->channels(), bottom[1]->channels());
CHECK_EQ(bottom[1]->channels(), bottom[2]->channels());
CHECK_EQ(bottom[0]->height(), 1);
CHECK_EQ(bottom[0]->width(), 1);
CHECK_EQ(bottom[1]->height(), 1);
CHECK_EQ(bottom[1]->width(), 1);
CHECK_EQ(bottom[2]->height(), 1);
CHECK_EQ(bottom[2]->width(), 1);
CHECK_EQ(bottom[3]->channels(),1);
CHECK_EQ(bottom[3]->height(), 1);
CHECK_EQ(bottom[3]->width(), 1);
diff_ap_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_an_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_pn_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_sq_ap_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
diff_sq_an_.Reshape(bottom[0]->num(), bottom[0]->channels(), 1, 1);
dist_sq_ap_.Reshape(bottom[0]->num(), 1, 1, 1);
dist_sq_an_.Reshape(bottom[0]->num(), 1, 1, 1);
// vector of ones used to sum along channels
summer_vec_.Reshape(bottom[0]->channels(), 1, 1, 1);
for (int i = 0; i < bottom[0]->channels(); ++i)
summer_vec_.mutable_cpu_data()[i] = Dtype(1);
dist_binary_.Reshape(bottom[0]->num(), 1, 1, 1);
for (int i = 0; i < bottom[0]->num(); ++i)
dist_binary_.mutable_cpu_data()[i] = Dtype(1);
}
template
void TripletLossLayer::Forward_cpu(
const vector*>& bottom,
const vector*>& top) {
int count = bottom[0]->count();
const Dtype* sampleW = bottom[3]->cpu_data();
caffe_sub(
count,
bottom[0]->cpu_data(), // a
bottom[1]->cpu_data(), // p
diff_ap_.mutable_cpu_data()); // a_i-p_i
caffe_sub(
count,
bottom[0]->cpu_data(), // a
bottom[2]->cpu_data(), // n
diff_an_.mutable_cpu_data()); // a_i-n_i
caffe_sub(
count,
bottom[1]->cpu_data(), // p
bottom[2]->cpu_data(), // n
diff_pn_.mutable_cpu_data()); // p_i-n_i
const int channels = bottom[0]->channels();
Dtype margin = this->layer_param_.triplet_loss_param().margin();
Dtype loss(0.0);
for (int i = 0; i < bottom[0]->num(); ++i) {
dist_sq_ap_.mutable_cpu_data()[i] = caffe_cpu_dot(channels,
diff_ap_.cpu_data() + (i*channels), diff_ap_.cpu_data() + (i*channels));
dist_sq_an_.mutable_cpu_data()[i] = caffe_cpu_dot(channels,
diff_an_.cpu_data() + (i*channels), diff_an_.cpu_data() + (i*channels));
Dtype mdist = sampleW[i]*std::max(margin + dist_sq_ap_.cpu_data()[i] - dist_sq_an_.cpu_data()[i], Dtype(0.0));
loss += mdist;
if(mdist==Dtype(0)){
//dist_binary_.mutable_cpu_data()[i] = Dtype(0);
//prepare for backward pass
caffe_set(channels, Dtype(0), diff_ap_.mutable_cpu_data() + (i*channels));
caffe_set(channels, Dtype(0), diff_an_.mutable_cpu_data() + (i*channels));
caffe_set(channels, Dtype(0), diff_pn_.mutable_cpu_data() + (i*channels));
}
}
loss = loss / static_cast(bottom[0]->num()) / Dtype(2);
top[0]->mutable_cpu_data()[0] = loss;
}
template
void TripletLossLayer::Backward_cpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom) {
//Dtype margin = this->layer_param_.contrastive_loss_param().margin();
const Dtype* sampleW = bottom[3]->cpu_data();
for (int i = 0; i < 3; ++i) {
if (propagate_down[i]) {
const Dtype sign = (i < 2) ? -1 : 1;
const Dtype alpha = sign * top[0]->cpu_diff()[0] /
static_cast(bottom[i]->num());
int num = bottom[i]->num();
int channels = bottom[i]->channels();
for (int j = 0; j < num; ++j) {
Dtype* bout = bottom[i]->mutable_cpu_diff();
if (i==0) { // a
//if(dist_binary_.cpu_data()[j]>Dtype(0)){
caffe_cpu_axpby(
channels,
alpha*sampleW[j],
diff_pn_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
//}else{
// caffe_set(channels, Dtype(0), bout + (j*channels));
//}
} else if (i==1) { // p
//if(dist_binary_.cpu_data()[j]>Dtype(0)){
caffe_cpu_axpby(
channels,
alpha*sampleW[j],
diff_ap_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
//}else{
// caffe_set(channels, Dtype(0), bout + (j*channels));
//}
} else if (i==2) { // n
//if(dist_binary_.cpu_data()[j]>Dtype(0)){
caffe_cpu_axpby(
channels,
alpha*sampleW[j],
diff_an_.cpu_data() + (j*channels),
Dtype(0.0),
bout + (j*channels));
//}else{
// caffe_set(channels, Dtype(0), bout + (j*channels));
//}
}
} // for num
} //if propagate_down[i]
} //for i
}
#ifdef CPU_ONLY
STUB_GPU(TripletLossLayer);
#endif
INSTANTIATE_CLASS(TripletLossLayer);
REGISTER_LAYER_CLASS(TripletLoss);
} // namespace caffe
4.在./src/caffe/layers/目录下新建triplet_loss_layer.cu,实现GPU下的前传和反传
/*
* triplet_loss_layer.cu
*
* Created on: Jun 2, 2015
* Author: tangwei
*/
#include
#include
#include "caffe/layer.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/vision_layers.hpp"
namespace caffe {
template
void TripletLossLayer::Forward_gpu(
const vector*>& bottom, const vector*>& top) {
const int count = bottom[0]->count();
caffe_gpu_sub(
count,
bottom[0]->gpu_data(), // a
bottom[1]->gpu_data(), // p
diff_ap_.mutable_gpu_data()); // a_i-p_i
caffe_gpu_sub(
count,
bottom[0]->gpu_data(), // a
bottom[2]->gpu_data(), // n
diff_an_.mutable_gpu_data()); // a_i-n_i
caffe_gpu_sub(
count,
bottom[1]->gpu_data(), // p
bottom[2]->gpu_data(), // n
diff_pn_.mutable_gpu_data()); // p_i-n_i
caffe_gpu_powx(
count,
diff_ap_.mutable_gpu_data(), // a_i-p_i
Dtype(2),
diff_sq_ap_.mutable_gpu_data()); // (a_i-p_i)^2
caffe_gpu_gemv(
CblasNoTrans,
bottom[0]->num(),
bottom[0]->channels(),
Dtype(1.0), //alpha
diff_sq_ap_.gpu_data(), // (a_i-p_i)^2 // A
summer_vec_.gpu_data(), // x
Dtype(0.0), //belta
dist_sq_ap_.mutable_gpu_data()); // \Sum (a_i-p_i)^2 //y
caffe_gpu_powx(
count,
diff_an_.mutable_gpu_data(), // a_i-n_i
Dtype(2),
diff_sq_an_.mutable_gpu_data()); // (a_i-n_i)^2
caffe_gpu_gemv(
CblasNoTrans,
bottom[0]->num(),
bottom[0]->channels(),
Dtype(1.0), //alpha
diff_sq_an_.gpu_data(), // (a_i-n_i)^2 // A
summer_vec_.gpu_data(), // x
Dtype(0.0), //belta
dist_sq_an_.mutable_gpu_data()); // \Sum (a_i-n_i)^2 //y
Dtype margin = this->layer_param_.triplet_loss_param().margin();
Dtype loss(0.0);
const Dtype* sampleW = bottom[3]->cpu_data();
for (int i = 0; i < bottom[0]->num(); ++i) {
loss += sampleW[i]*std::max(margin +dist_sq_ap_.cpu_data()[i]- dist_sq_an_.cpu_data()[i], Dtype(0.0));
}
loss = loss / static_cast(bottom[0]->num()) / Dtype(2);
top[0]->mutable_cpu_data()[0] = loss;
}
template
__global__ void CLLBackward(const int count, const int channels,
const Dtype margin, const Dtype alpha, const Dtype* sampleW,
const Dtype* diff, const Dtype* dist_sq_ap_, const Dtype* dist_sq_an_,
Dtype *bottom_diff) {
CUDA_KERNEL_LOOP(i, count) {
int n = i / channels; // the num index, to access dist_sq_ap_ and dist_sq_an_
Dtype mdist(0.0);
mdist = margin +dist_sq_ap_[n] - dist_sq_an_[n];
if (mdist > 0.0) {
bottom_diff[i] = alpha*sampleW[n]*diff[i];
} else {
bottom_diff[i] = 0;
}
}
}
template
void TripletLossLayer::Backward_gpu(const vector*>& top,
const vector& propagate_down, const vector*>& bottom) {
Dtype margin = this->layer_param_.triplet_loss_param().margin();
const int count = bottom[0]->count();
const int channels = bottom[0]->channels();
for (int i = 0; i < 3; ++i) {
if (propagate_down[i]) {
const Dtype sign = (i < 2) ? -1 : 1;
const Dtype alpha = sign * top[0]->cpu_diff()[0] /
static_cast(bottom[0]->num());
if(i==0){
// NOLINT_NEXT_LINE(whitespace/operators)
CLLBackward<<>>(
count, channels, margin, alpha,
bottom[3]->gpu_data(),
diff_pn_.gpu_data(), // the cached eltwise difference between p and n
dist_sq_ap_.gpu_data(), // the cached square distance between a and p
dist_sq_an_.gpu_data(), // the cached square distance between a and n
bottom[i]->mutable_gpu_diff());
CUDA_POST_KERNEL_CHECK;
}else if(i==1){
// NOLINT_NEXT_LINE(whitespace/operators)
CLLBackward<<>>(
count, channels, margin, alpha,
bottom[3]->gpu_data(),
diff_ap_.gpu_data(), // the cached eltwise difference between a and p
dist_sq_ap_.gpu_data(), // the cached square distance between a and p
dist_sq_an_.gpu_data(), // the cached square distance between a and n
bottom[i]->mutable_gpu_diff());
CUDA_POST_KERNEL_CHECK;
}else if(i==2){
// NOLINT_NEXT_LINE(whitespace/operators)
CLLBackward<<>>(
count, channels, margin, alpha,
bottom[3]->gpu_data(),
diff_an_.gpu_data(), // the cached eltwise difference between a and n
dist_sq_ap_.gpu_data(), // the cached square distance between a and p
dist_sq_an_.gpu_data(), // the cached square distance between a and n
bottom[i]->mutable_gpu_diff());
CUDA_POST_KERNEL_CHECK;
}
}
}
}
INSTANTIATE_LAYER_GPU_FUNCS(TripletLossLayer);
} // namespace caffe
5. 在./src/caffe/test/目录下增加test_triplet_loss_layer.cpp
/*
* test_triplet_loss_layer.cpp
*
* Created on: Jun 3, 2015
* Author: tangwei
*/
#include
#include
#include
#include
#include
#include "gtest/gtest.h"
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/filler.hpp"
#include "caffe/vision_layers.hpp"
#include "caffe/test/test_caffe_main.hpp"
#include "caffe/test/test_gradient_check_util.hpp"
namespace caffe {
template
class TripletLossLayerTest : public MultiDeviceTest {
typedef typename TypeParam::Dtype Dtype;
protected:
TripletLossLayerTest()
: blob_bottom_data_i_(new Blob(512, 2, 1, 1)),
blob_bottom_data_j_(new Blob(512, 2, 1, 1)),
blob_bottom_data_k_(new Blob(512, 2, 1, 1)),
blob_bottom_y_(new Blob(512, 1, 1, 1)),
blob_top_loss_(new Blob()) {
// fill the values
FillerParameter filler_param;
filler_param.set_min(-1.0);
filler_param.set_max(1.0); // distances~=1.0 to test both sides of margin
UniformFiller filler(filler_param);
filler.Fill(this->blob_bottom_data_i_);
blob_bottom_vec_.push_back(blob_bottom_data_i_);
filler.Fill(this->blob_bottom_data_j_);
blob_bottom_vec_.push_back(blob_bottom_data_j_);
filler.Fill(this->blob_bottom_data_k_);
blob_bottom_vec_.push_back(blob_bottom_data_k_);
for (int i = 0; i < blob_bottom_y_->count(); ++i) {
blob_bottom_y_->mutable_cpu_data()[i] = caffe_rng_rand() % 2; // 0 or 1
}
blob_bottom_vec_.push_back(blob_bottom_y_);
blob_top_vec_.push_back(blob_top_loss_);
}
virtual ~TripletLossLayerTest() {
delete blob_bottom_data_i_;
delete blob_bottom_data_j_;
delete blob_bottom_data_k_;
delete blob_top_loss_;
}
Blob* const blob_bottom_data_i_;
Blob* const blob_bottom_data_j_;
Blob* const blob_bottom_data_k_;
Blob* const blob_bottom_y_;
Blob* const blob_top_loss_;
vector*> blob_bottom_vec_;
vector*> blob_top_vec_;
};
TYPED_TEST_CASE(TripletLossLayerTest, TestDtypesAndDevices);
TYPED_TEST(TripletLossLayerTest, TestForward) {
typedef typename TypeParam::Dtype Dtype;
LayerParameter layer_param;
TripletLossLayer layer(layer_param);
layer.SetUp(this->blob_bottom_vec_, this->blob_top_vec_);
layer.Forward(this->blob_bottom_vec_, this->blob_top_vec_);
// manually compute to compare
const Dtype margin = layer_param.triplet_loss_param().margin();
const int num = this->blob_bottom_data_i_->num();
const int channels = this->blob_bottom_data_i_->channels();
const Dtype *sampleW = this->blob_bottom_y_->cpu_data();
Dtype loss(0);
for (int i = 0; i < num; ++i) {
Dtype dist_sq_ij(0);
Dtype dist_sq_ik(0);
for (int j = 0; j < channels; ++j) {
Dtype diff_ij = this->blob_bottom_data_i_->cpu_data()[i*channels+j] -
this->blob_bottom_data_j_->cpu_data()[i*channels+j];
dist_sq_ij += diff_ij*diff_ij;
Dtype diff_ik = this->blob_bottom_data_i_->cpu_data()[i*channels+j] -
this->blob_bottom_data_k_->cpu_data()[i*channels+j];
dist_sq_ik += diff_ik*diff_ik;
}
loss += sampleW[i]*std::max(Dtype(0.0), margin+dist_sq_ij-dist_sq_ik);
}
loss /= static_cast(num) * Dtype(2);
EXPECT_NEAR(this->blob_top_loss_->cpu_data()[0], loss, 1e-6);
}
TYPED_TEST(TripletLossLayerTest, TestGradient) {
typedef typename TypeParam::Dtype Dtype;
LayerParameter layer_param;
TripletLossLayer layer(layer_param);
layer.SetUp(this->blob_bottom_vec_, this->blob_top_vec_);
GradientChecker checker(1e-2, 1e-2, 1701);
// check the gradient for the first two bottom layers
checker.CheckGradientExhaustive(&layer, this->blob_bottom_vec_,
this->blob_top_vec_, 0);
checker.CheckGradientExhaustive(&layer, this->blob_bottom_vec_,
this->blob_top_vec_, 1);
}
} // namespace caffe
3.编译测试
重新 make all 如果出错,检查代码语法错误。
make test
make runtest 如果成功,全是绿色的OK 否则会给出红色提示,就得看看是不是实现逻辑上出错了。 ==============================================================================================================================
然后是添加PrecisionRecallLosslayer,感谢一位中科院的朋友。
1、首先在caffe.proto文件中添加:

2、然后在所属层loss_layer.hpp中添加定义:

3、然后添加改层~/caffe-add/src/caffe/layers/precision_recall_loss_layer.cpp的实现:
#include
#include
#include
#include
#include
#include "caffe/layer.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/vision_layers.hpp"
namespace caffe {
template
void PrecisionRecallLossLayer::LayerSetUp(
const vector*> &bottom, const vector*> &top) {
LossLayer::LayerSetUp(bottom, top);
}
template
void PrecisionRecallLossLayer::Reshape(
const vector*> &bottom,
const vector*> &top) {
LossLayer::Reshape(bottom, top);
loss_.Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
// Check the shapes of data and label
CHECK_EQ(bottom[0]->num(), bottom[1]->num())
<< "The number of num of data and label should be same.";
CHECK_EQ(bottom[0]->channels(), bottom[1]->channels())
<< "The number of channels of data and label should be same.";
CHECK_EQ(bottom[0]->height(), bottom[1]->height())
<< "The heights of data and label should be same.";
CHECK_EQ(bottom[0]->width(), bottom[1]->width())
<< "The width of data and label should be same.";
}
template
void PrecisionRecallLossLayer::Forward_cpu(
const vector*> &bottom, const vector*> &top) {
const Dtype *data = bottom[0]->cpu_data();
const Dtype *label = bottom[1]->cpu_data();
const int num = bottom[0]->num();
const int dim = bottom[0]->count() / num;
const int channels = bottom[0]->channels();
const int spatial_dim = bottom[0]->height() * bottom[0]->width();
const int pnum =
this->layer_param_.precision_recall_loss_param().point_num();
top[0]->mutable_cpu_data()[0] = 0;
for (int c = 0; c < channels; ++c) {
Dtype breakeven = 0.0;
Dtype prec_diff = 1.0;
for (int p = 0; p <= pnum; ++p) {
int true_positive = 0;
int false_positive = 0;
int false_negative = 0;
int true_negative = 0;
for (int i = 0; i < num; ++i) {
const Dtype thresh = 1.0 / pnum * p;
for (int j = 0; j < spatial_dim; ++j) {
const Dtype data_value = data[i * dim + c * spatial_dim + j];
const int label_value = (int)label[i * dim + c * spatial_dim + j];
if (label_value == 1 && data_value >= thresh) {
++true_positive;
}
if (label_value == 0 && data_value >= thresh) {
++false_positive;
}
if (label_value == 1 && data_value < thresh) {
++false_negative;
}
if (label_value == 0 && data_value < thresh) {
++true_negative;
}
}
}
Dtype precision = 0.0;
Dtype recall = 0.0;
if (true_positive + false_positive > 0) {
precision =
(Dtype)true_positive / (Dtype)(true_positive + false_positive);
} else if (true_positive == 0) {
precision = 1.0;
}
if (true_positive + false_negative > 0) {
recall =
(Dtype)true_positive / (Dtype)(true_positive + false_negative);
} else if (true_positive == 0) {
recall = 1.0;
}
if (prec_diff > fabs(precision - recall)
&& precision > 0 && precision < 1
&& recall > 0 && recall < 1) {
breakeven = precision;
prec_diff = fabs(precision - recall);
}
}
top[0]->mutable_cpu_data()[0] += 1.0 - breakeven;
}
top[0]->mutable_cpu_data()[0] /= channels;
}
template
void PrecisionRecallLossLayer::Backward_cpu(
const vector*> &top,
const vector &propagate_down,
const vector*> &bottom) {
for (int i = 0; i < propagate_down.size(); ++i) {
if (propagate_down[i]) { NOT_IMPLEMENTED; }
}
}
#ifdef CPU_ONLY
STUB_GPU(PrecisionRecallLossLayer);
#endif
INSTANTIATE_CLASS(PrecisionRecallLossLayer);
REGISTER_LAYER_CLASS(PrecisionRecallLoss);
} // namespace caffe #include
#include
#include
#include "thrust/device_vector.h"
#include "caffe/layer.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/vision_layers.hpp"
namespace caffe {
template
void PrecisionRecallLossLayer::Forward_gpu(
const vector*> &bottom, const vector*> &top) {
Forward_cpu(bottom, top);
}
template
void PrecisionRecallLossLayer::Backward_gpu(
const vector*> &top,
const vector &propagate_down,
const vector*> &bottom) {
if (propagate_down[1]) {
LOG(FATAL) << this->type()
<< " Layer cannot backpropagate to label inputs.";
}
if (propagate_down[0]) {
Backward_cpu(top, propagate_down, bottom);
}
}
INSTANTIATE_LAYER_GPU_FUNCS(PrecisionRecallLossLayer);
} // namespace caffe 5、通过简单的minst测试,修改训练配置文件:
............
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
layer {
name: "precision_recall_loss"
type: "PrecisionRecallLoss"
bottom: "ip2"
bottom: "label"
top: "error_rate"
include {
phase: TEST
}
}