PHP使用Elasticsearch 全文搜索引擎的开发
PHP基于elasticsearch全文搜索引擎的开发
1.概述:
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。Elasticsearch中涉及到的重要概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
好了,本文主要讲Elasticsearch环境搭建,以及中文分词的用法。下面讲Elasticsearch环境搭建以及使用。
2.环境搭建
1.安装 JAVA JDK 8
sudo apt-get update
sudo apt-get install openjdk-8-jre
查看jdk安装信息:

2.下载最新的 elasticsearch安装包:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.2.tar.gz
tar -zxvf elasticsearch-6.6.2.tar.gz
cd elasticsearch-6.6.2
启动
./bin/elasticsearch
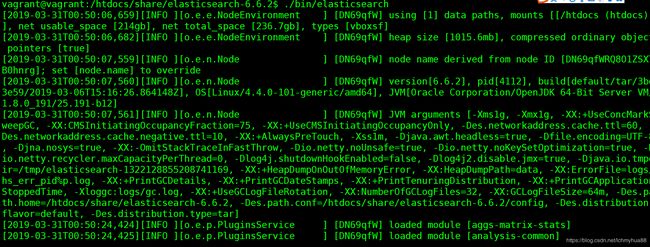
启动会打印启动的包信息:
3. 安装IK中文分词插件.
在ik分词的git(https://github.com/medcl/elasticsearch-analysis-ik
)上找到相应的ES对应的版本:
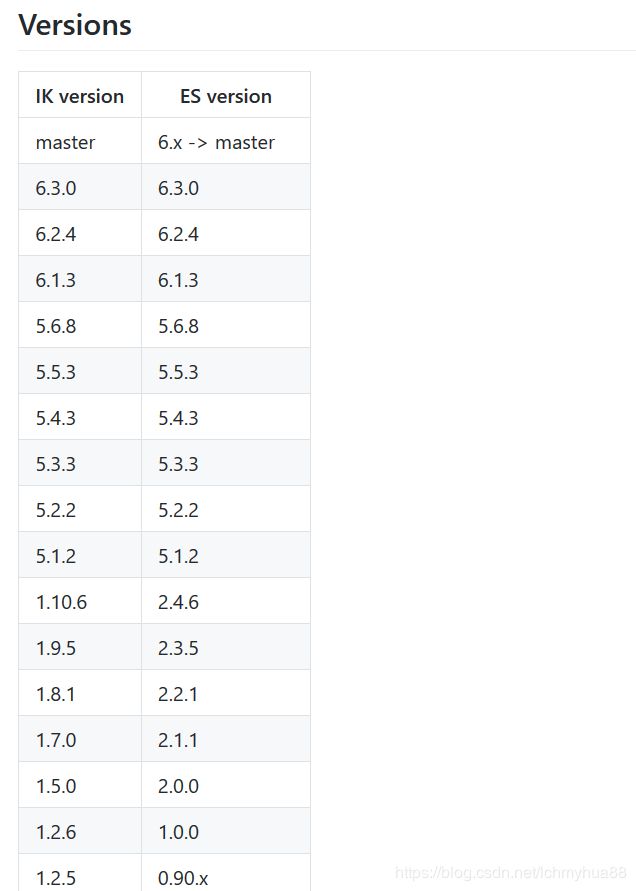

我这里安装的是最新的版本6.6.2:
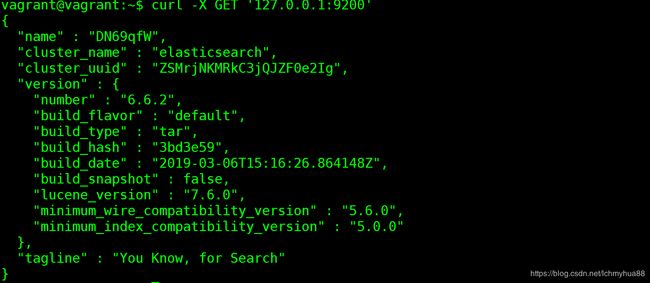
看到上面的信息,那么我们的环境就搭建 好了。
3.使用。
我本地建立一张书本信息表,里面4个字段,其中attr_text是英文存储的,其他几个字段是中文

接下来创建索引:
先设置索引参数:
$params = [
'index' => 'huazia',
'body' => [
'settings' => [
'number_of_shards' => 3,
'number_of_replicas' => 2,
'analysis' => [
'filter' => [
"ngram_filter" => [
"type" => "ngram",
"min_gram" => 2,
"max_gram" => 20
]
],
'analyzer' => [
"ngram_analyzer" => [
"type" => "custom",
"tokenizer" => "whitespace",
"filter" => [
"lowercase",
"asciifolding",
"ngram_filter"
]
]
]
]
],
'mappings' => [
'dd_book' => [
'_source' => [
'enabled' => true
],
'properties' => [
'book_name' => [
'type' => 'text',
'analyzer' => 'ik_max_word',
'search_analyzer' => 'ik_max_word',
],
'book_author' => [
'type' => 'text',
'analyzer' => 'ik_max_word',
'search_analyzer' => 'ik_max_word',
],
'book_desc' => [
'type' => 'text',
'analyzer' => 'ik_max_word',
'search_analyzer' => 'ik_max_word',
],
'attr_text' => [
'type' => 'text',
'analyzer' => 'ngram_analyzer',
'search_analyzer' => 'standard',
],
]
]
]
]
];
其中book_name,book_author,book_desc都中文,使用了中文分词器IK分词器。attr_text是英文的,所以使用ngram分词器(elasticsearch自带的分词器)
接下来我们创建索引:

看到已经创建完成
紧接着我们把mysql的书本信息表数据生成索引数据:

好了,以上准备工作已经做完了,接着我们去创建我们的搜索
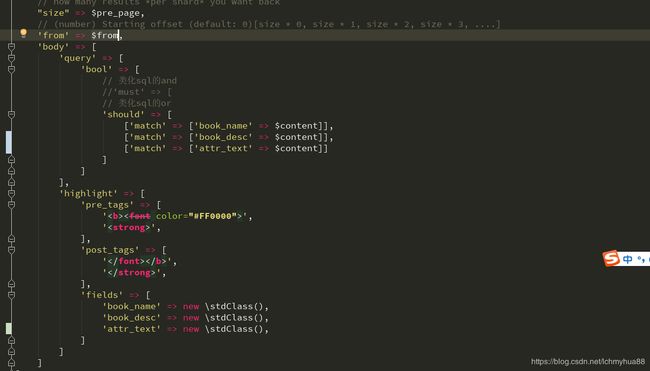
这里搜索3个字段,书名,描述,英文描述;并且对关键字进行高亮标红处理。
打开浏览器我们开始搜索:
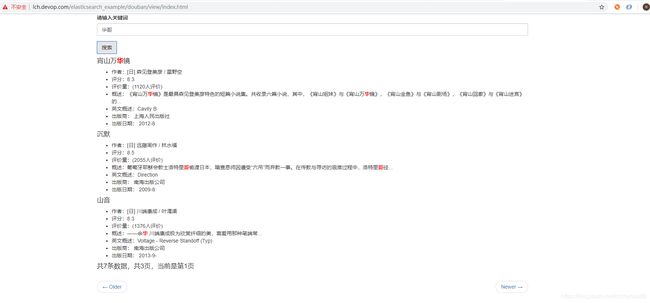
看到book_name这个字段搜索出来了高亮显示了。接着可以搜索英文描述字段attr_text;

可以看到这个英文字段信息也搜索出来了,英文搜索用的ngram切词器,本例中设置的最小粒度为2个词,也就是少于2个词是搜索不出来的,当然了粒度越小越耗性能。本例中数据的索引分了3片,查看其中的信息:

查看所有索引的信息:

以上介绍了Elasticsearch中文分词和英文分词的基本使用。接下来我们可以对Elasticsearch启动进程进行管理,本文讲的是supervisor来管理进程。
在supervisor配置文件里面设置如下:
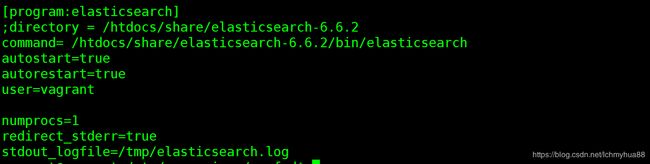
接着重启服务,看到服务已经启动。

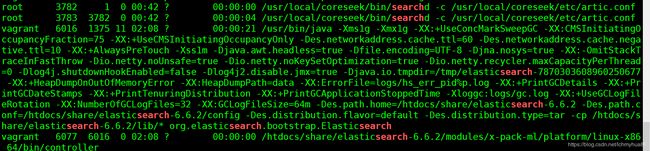
可以查看启动信息:
本文针对Elasticsearch中文搜索就介绍到这里了,后面再介绍分库分表索引构建,以及内存管理