Tensorflow on Spark爬坑指南
 NVIDIA 深度学习学院 带你快速进入火热的DL领域
NVIDIA 深度学习学院 带你快速进入火热的DL领域
阅读全文 >
正文共10718个字 3张图,预计阅读时间27分钟。
由于机器学习和深度学习不断被炒热,Tensorflow作为Google家(Jeff Dean大神)推出的开源深度学习框架,也获得了很多关注。Tensorflow的灵活性很强,允许用户使用多台机器的多个设备(如不同的CPU和GPU)。但是由于Tensorflow 分布式的方式需要用户在客户端显示指定集群信息,另外需要手动拉起ps, worker等task. 对资源管理和使用上有诸多不便。因此,Yahoo开源了基于Spark的Tensorflow,使用executor执行worker和ps task. 项目地址为:https://github.com/yahoo/TensorFlowOnSpark。
写在前面,前方高能,请注意!
虽然yahoo提供了如何在Spark集群中运行Tensorflow的步骤,但是由于这个guideline过于简单,一般情况下,根据这个guideline是跑不起来的。
Tensorflow on spark介绍
TensorflowOnSpark 支持使用Spark/Hadoop集群分布式的运行Tensorflow,号称支持所有的Tensorflow操作。需要注意的是用户需要对原有的TF程序进行简单的改造,就能够运行在Spark集群之上。
如何跑起来Tensorflow on spark
虽然Yahoo在github上说明了安装部署TFS (https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN), 但是根据实际实践,根据这个文档如果能跑起来,那真的要谢天谢地。因为在实际过程中,会因为环境问题遇到一些unexpected error。以下就是我将自己在实践过程中遇到的一些问题总结列举。
yahoo提供的编译步骤为:
# download and extract Python 2.7 export PYTHON_ROOT=~/Python curl -O https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz tar -xvf Python-2.7.12.
tgzrm Python-2.7.12.tgz
# compile into local PYTHON_ROOT
pushd Python-2.7.12 ./configure --prefix="${PYTHON_ROOT}" --enable-unicode=ucs4 make make installpopdrm -rf Python-2.7.12 # install pip
pushd "${PYTHON_ROOT}"
curl -O https://bootstrap.pypa.io/get-pip.py bin/python get-pip.py rm get-pip.py
# install tensorflow (and any custom dependencies)
${PYTHON_ROOT}/bin/pip install pydoop
# Note: add any extra dependencies here
popd
在实际编译过程中,采用的Centos7.2操作系统,可能出现以下问题:
安装pip报错
bin/python get-pip.py ERROR:root:code for hash sha224 was not found. Traceback (most recent call last):
报这个错一般是因为python中缺少_ssl.so 和 _hashlib.so库造成,可以从系统python库中找对应版本的拷贝到相应的python文件夹下(例如:lib/python2.7/lib-dynload)。
缺少zlib
bin/python get-pip.py Traceback (most recent call last): File "get-pip.py", line 20061, in
解决这个问题的方法是使用yum安装zlib*后,重新编译python后,即可解决。
ssl 报错
bin/python get-pip.py pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. Collecting pip Could not fetch URL https://pypi.python.org/simple/pip/: There was a problem confirming the ssl certificate: Can't connect to HTTPS URL because the SSL module is not available. - skipping Could not find a version that satisfies the requirement pip (from versions: ) No matching distribution found for pip
解决方法: 在Python安装目录下打开文件lib/python2.7/ssl.py,注释掉 , HAS_ALPN
from _ssl import HAS_SNI, HAS_ECDH, HAS_NPN#, HAS_ALPN
pip install pydoop报错
gcc: error trying to exec 'cc1plus': execvp:
解决办法:需要在机器上安装g++编译器
git clone [email protected]:yahoo/tensorflow.git# follow build instructions to install into ${PYTHON_ROOT}
注意编译过程需要google的bazel和protoc, 这两个工具需要提前装好。
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN 指导的步骤完成。
在yarn-env.sh中设置环境变量,增加 * export HADOOP_HDFS_HOME=/usr/hdp/2.5.0.0-1245/hadoop-hdfs/*
因为这个环境变量需要在执行tensorflow任务时被用到,如果没有export,会报错。
重启YARN,使上述改动生效。
按照Yahoo github上的步骤,执行训练mnist任务时,按下面命令提交作业:
export PYTHON_ROOT=/data2/Python/export LD_LIBRARY_PATH=${PATH}export PYSPARK_PYTHON=${PYTHON_ROOT}/bin/pythonexport SPARK_YARN_USER_ENV="PYSPARK_PYTHON=Python/bin/python"export PATH=${PYTHON_ROOT}/bin/:$PATHexport QUEUE=default spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 1G \ --py-files /data2/tesorflowonSpark/TensorFlowOnSpark/tfspark.zip,/data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --archives hdfs:///user/${USER}/Python.zip#Python \--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/jdk64/jdk1.8.0_77/jre/lib/amd64/server/" \ /data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \ --images mnist/csv/test/images \ --labels mnist/csv/test/labels \ --mode inference \ --model mnist_model \ --output predictions
此时,通过Spark界面可以观察到worker0处于阻塞状态。
17/03/21 18:17:18 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 28.4 KB, free 542.6 KB) 17/03/21 18:17:18 INFO TorrentBroadcast: Reading broadcast variable 1 took 17 ms 17/03/21 18:17:18 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 440.6 KB, free 983.3 KB) 2017-03-21 18:17:18,404 INFO (MainThread-14872) Connected to TFSparkNode.mgr on ochadoop03, ppid=14685, state='running' 2017-03-21 18:17:18,411 INFO (MainThread-14872) mgr.state='running' 2017-03-21 18:17:18,411 INFO (MainThread-14872) Feeding partition
通过分析原因发现,在mnist例子中,logdir设置的是hdfs的路径,可能是由于tf对hdfs的支持有限或者存在bug(惭愧,并没有深究 :))。将logdir改为本地目录,就可以正常运行。但是由此又带来了另一个问题,因为Spark每次启动时worker0的位置并不确定,有可能每次启动的机器都不同,这就导致在inference的时候没有办法获得训练的模型。
一个解决办法是:在worker 0训练完模型后,将模型同步到hdfs中,在inference的之前,再将hdfs的checkpoints文件夹拉取到本地执行。以下为我对yahoo提供的mnist example做的类似的修改.
def writeFileToHDFS():
rootdir = '/tmp/mnist_model'
client = HdfsClient(hosts='localhost:50070')
client.mkdirs('/user/root/mnist_model')
for parent,dirnames,filenames in os.walk(rootdir):
for dirname in dirnames:
print("parent is:{0}".format(parent))
for filename in filenames:
client.copy_from_local(os.path.join(parent,filename), os.path.join('/user/root/mnist_model',filename), overwrite=True)
#logdir = TFNode.hdfs_path(ctx, args.model)
logdir = "/tmp/" + args.model
while not sv.should_stop() and step < args.steps:
# Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
# using feed_dict
batch_xs, batch_ys = feed_dict()
feed = {x: batch_xs, y_: batch_ys}
if len(batch_xs) != batch_size:
print("done feeding")
break
else:
if args.mode == "train":
_, step = sess.run([train_op, global_step], feed_dict=feed)
# print accuracy and save model checkpoint to HDFS every 100 steps
if (step % 100 == 0):
print("{0} step: {1} accuracy: {2}".format(datetime.now().isoformat(), step, sess.run(accuracy,{x: batch_xs, y_: batch_ys})))
else:
# args.mode == "inference"
labels, preds, acc = sess.run([label, prediction, accuracy], feed_dict=feed)
results = ["{0} Label: {1}, Prediction: {2}".format(datetime.now().isoformat(), l, p) for l,p in zip(labels,preds)]
TFNode.batch_results(ctx.mgr, results)
print("acc: {0}".format(acc))
if task_index == 0:
writeFileToHDFS()
当然这段代码只是为了进行说明,并不是很严谨,在上传hdfs的时候,是需要对文件夹是否存在等要做一系列的判断。
向Spark集群提交训练任务.
spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 3 \ --executor-memory 7G \ --py-files /data2/tesorflowonSpark/TensorFlowOnSpark/tfspark.zip,/data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --archives hdfs:///user/${USER}/Python.zip#Python \--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/jdk64/jdk1.8.0_77/jre/lib/amd64/server/" \ /data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \ --images mnist/csv/train/images \ --labels mnist/csv/train/labels \ --mode train \ --model mnist_model
执行起来后,查看Spark UI,可以看到当前训练过程中的作业执行情况。
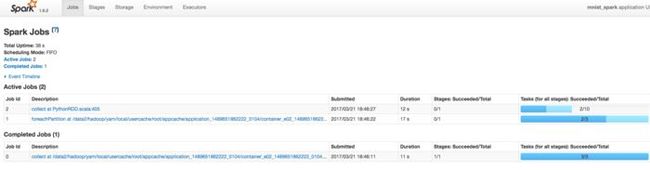
6.46.43.png
执行完后,检查hdsf,checkpoint目录, 可以看到模型的checkpoints已经上传到hdfs中。
hadoop fs -ls /user/root/mnist_model Found 8 items -rwxr-xr-x 3 root hdfs 179 2017-03-21 18:53 /user/root/mnist_model/checkpoint -rwxr-xr-x 3 root hdfs 117453 2017-03-21 18:53 /user/root/mnist_model/graph.pbtxt -rwxr-xr-x 3 root hdfs 814164 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-0.data-00000-of-00001-rwxr-xr-x 3 root hdfs 372 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-0.index -rwxr-xr-x 3 root hdfs 45557 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-0.meta -rwxr-xr-x 3 root hdfs 814164 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-338.data-00000-of-00001-rwxr-xr-x 3 root hdfs 372 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-338.index -rwxr-xr-x 3 root hdfs 45557 2017-03-21 18:53 /user/root/mnist_model/model.ckpt-338.meta
根据训练的结果,执行模型inference
spark-submit \ --master yarn \ --deploy-mode cluster \ --queue ${QUEUE} \ --num-executors 4 \ --executor-memory 1G \ --py-files /data2/tesorflowonSpark/TensorFlowOnSpark/tfspark.zip,/data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_dist.py \ --conf spark.dynamicAllocation.enabled=false \ --conf spark.yarn.maxAppAttempts=1 \ --archives hdfs:///user/${USER}/Python.zip#Python \--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/jdk64/jdk1.8.0_77/jre/lib/amd64/server/" \ /data2/tesorflowonSpark/TensorFlowOnSpark/examples/mnist/spark/mnist_spark.py \ --images mnist/csv/test/images \ --labels mnist/csv/test/labels \ --mode inference \ --model mnist_model \ --output predictions
等任务执行完成后,会发现,模型判断的结果已经输出到hdfs相关目录下了。
hadoop fs -ls /user/root/predictions Found 11 items -rw-r--r-- 3 root hdfs 0 2017-03-21 19:16 /user/root/predictions/_SUCCESS -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00000 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00001 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00002 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00003 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00004 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00005 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00006 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00007 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00008 -rw-r--r-- 3 root hdfs 51000 2017-03-21 19:16 /user/root/predictions/part-00009
查看其中的某一个文件,可看到里面保存的是测试集的标签和根据模型预测的结果。
# hadoop fs -cat /user/root/predictions/part-000002017-03-21T19:16:40.795694 Label: 7, Prediction: 7 2017-03-21T19:16:40.795729 Label: 2, Prediction: 2 2017-03-21T19:16:40.795741 Label: 1, Prediction: 1 2017-03-21T19:16:40.795750 Label: 0, Prediction: 0 2017-03-21T19:16:40.795759 Label: 4, Prediction: 4 2017-03-21T19:16:40.795769 Label: 1, Prediction: 1 2017-03-21T19:16:40.795778 Label: 4, Prediction: 4 2017-03-21T19:16:40.795787 Label: 9, Prediction: 9 2017-03-21T19:16:40.795796 Label: 5, Prediction: 6 2017-03-21T19:16:40.795805 Label: 9, Prediction: 9 2017-03-21T19:16:40.795814 Label: 0, Prediction: 0 2017-03-21T19:16:40.795822 Label: 6, Prediction: 6 2017-03-21T19:16:40.795831 Label: 9, Prediction: 9 2017-03-21T19:16:40.795840 Label: 0, Prediction: 0 2017-03-21T19:16:40.795848 Label: 1, Prediction: 1 2017-03-21T19:16:40.795857 Label: 5, Prediction: 5 2017-03-21T19:16:40.795866 Label: 9, Prediction: 9 2017-03-21T19:16:40.795875 Label: 7, Prediction: 7 2017-03-21T19:16:40.795883 Label: 3, Prediction: 3 2017-03-21T19:16:40.795892 Label: 4, Prediction: 4 2017-03-21T19:16:40.795901 Label: 9, Prediction: 9 2017-03-21T19:16:40.795909 Label: 6, Prediction: 6 2017-03-21T19:16:40.795918 Label: 6, Prediction: 6
Spark集群和tensorflow job task的对应关系,如下图,spark集群起了4个executor,其中一个作为PS, 另外3个作为worker,而谁做ps谁做worker是由Yarn和spark调度的。
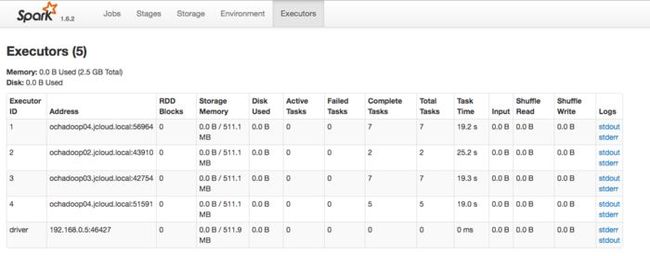
7.22.23.png
Cluster spec: {'ps': ['ochadoop02:50060'], 'worker': ['ochadoop04:52150', 'ochadoop03:52733', 'ochad
原文链接:https://www.jianshu.com/p/72cb5816a0f7
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

LSTM模型在问答系统中的应用
基于TensorFlow的神经网络解决用户流失概览问题
最全常见算法工程师面试题目整理(一)
最全常见算法工程师面试题目整理(二)
TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络
装饰器 | Python高级编程
今天不如来复习下Python基础
