图像识别的深度残差学习Deep Residual Learning for Image Recognition
原论文:Deep Residual Learning for Image Recognition
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun (Microsoft Research)
时间:Dec 2015
本文的大部分观点来自于这篇论文,并且加入了一些自己的理解。该博客纯属读书笔记。
神经网络的深度加深,带来的其中一个重要的问题就是梯度的消失和发散(vanishing/exploding gradients),它会导致深层的网络参数得不到有效的校正信号或者使得训练难以收敛,通过归一化或者之前提到的BN方法可以得到有效的缓解。但是当我们将神经网络的深度继续加深期望获得更好的输出时,我们意外地发现事实并不是我们想的那样:随着深度加深,网络的准确度趋向于饱和了,然后当我们继续加深网络,网络的准确度居然降低了,并且出现这种问题并不是因为过拟合导致的。如图1所示。56层的网络比20层的网络准确度还低。
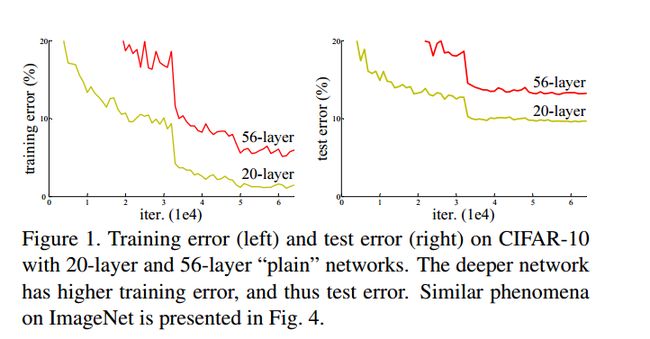 图1
图1
这是我们在训练神经网络是会遇到的一个优化的难题,即随着网络层数不断加深,求解器不能找到解决的途径,反而导致准确率下降。
Residual Network
文章提出的解决办法就是使用残差网络结构来代替原来的非线性网络结构。
假设现在有一个浅层的神经网络,具有比较理想的输出结果,现在我们在这个神经网络的后边再加几层得到一个新的神经网络,我们发现输出结果的准确度反而下降了。这是不合理的,因为如果我们后边加上的那几层对应的输入输出关系都是恒等的( identity mapping),至少新的深层神经网络也能和旧的神经网络的性能持平才对。但是,实验的结果表明现在的求解方法并不能得到理想的结果。
这是我们目前遇到的一个优化的难题,就是随着网络层数不断加深,求解器不能找到正确的解决途径。
所以文章提出了一种深度残差学习(Deep Residual Learning)的方法。图一(图片来自何凯明的深度残差网络PPT)是以往的神经网络使用的非线性函数。
 图一
图一
H(x)是任何一种理想的映射,我们希望图一的两层中的权值能够得到调整以适应H(x),但是前面已经说了,随着层数加深,求解器很难找到正确的求解途径。所以文章提出了深度残差学习的方法,如图二,图三(图片来自何凯明的深度残差网络PPT)所示。
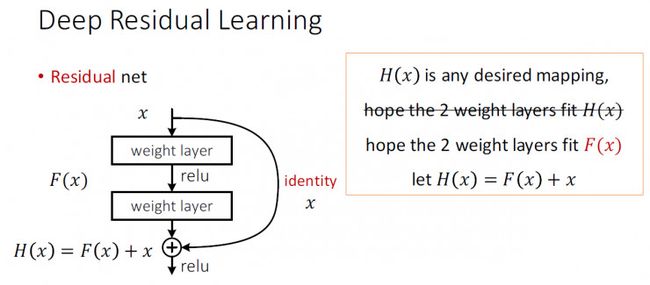 图2
图2
 图三
图三
这里H(x)仍然是一种理想的映射,但是我们在这里不调整stacked layers的权值去适应H(x),而是适应另外一个F(x),然后让H(x) = F(x) + x, x在这里是stacked layers的输入。之所以这么做是基于这样一个先验条件:就是在深层的神经网络完成的是一种恒等映射,或者是一种接近于恒等的映射。这样,我们stacked layers中的权值就更容易得到调整了。如PPT上说的,如果说恒等是理想,很容易将权重值设定为0;如果理想化映射更接近于恒等映射,便更容易发现微小波动。
这个时候stacked layers的输出不是传统神经网络当中输入的映射,而是映射和输入的叠加。通过如图所示的shortcut connections,我们可以很容易的实现这种映射。
We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
Identity Shortcuts
前面也讲了 identity shortcuts 的作用,在实际应用中,如果输入输出的维度不同(CNN中比较常见)则需要对其进行适当变形,简单一点的方法就是对额外多出来的维度用零值填充,文章给出另外一种更合理的方法。公式如图四所示。
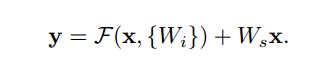 图四
图四
图四
文章通过对VGG nets做适当的改进弄了一个Plain Netwrok作为Baseline,然后与34层的Residual Network做比较。其中的很多地方就需要提高维度,使用1*1的卷积核就可以实现,此外还需要注意卷积的步幅需要一致。
Experiments
通过对比实验证明了残差学习的效果。如图五所示。
 图五
图五
实验还比较了三种projection shortcuts的实验效果。
A:零值填充,没有附加参数
B:维度上升时使用projection shortcuts,附加参数较少
C:all shortcuts are projections,附加参数很多
实验结果如图六所示。
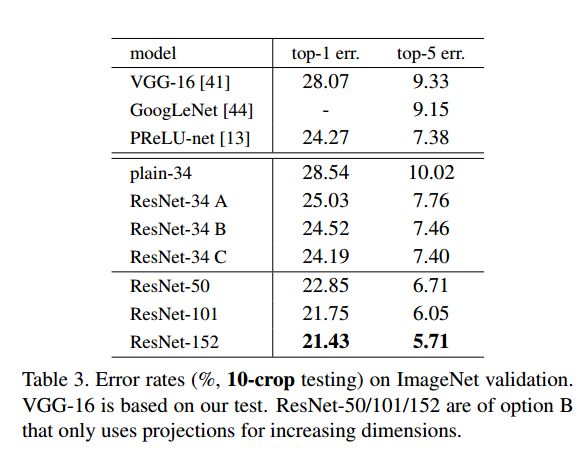 图六
图六
B比A效果提高了很多,C比B效果略微提高了一些。因为projection shortcuts并不是解决degradation problem的关键,所以文章选择B作为后续实验的网络的构建方式。这样可以减少参数,从而使得网络深度可以更深。
Deeper Bottleneck Architectures
文章提出了使用三层的building block来代替两层的building block,达到减少参数的目的。如图七所示。
 图七
图七
图七
采用三层的building block可以使得参数减少大约一半,并且网络层数还增加了。这样可以使得网络深度得到很大的提升而参数量却没有太大的变化。