一文读懂目前大热的AutoML与NAS!
点击我爱计算机视觉标星,更快获取CVML新技术
本文作者为奇点汽车美研中心首席科学家兼总裁黄浴先生,原载于知乎自动驾驶的挑战和发展专栏,原文链接:
自动机器学习AutoML和神经架构搜索NAS简介
https://zhuanlan.zhihu.com/p/75747814
文章有点长,建议收藏,绝对值得细读!
自动机器学习(AutoML, Automated Machine Learning)提供方法和流程使机器学习可用于非机器学习专家,提高机器学习的效率并加速机器学习的研究。
机器学习(ML)近年来取得了相当大的成功,并且越来越多的学科依赖它。但是,这一成功至关重要依赖于机器学习专家来执行以下任务:
预处理数据;
选择适当的特征;
选择合适的模型族;
优化模型超参数(hyperparameters);
后处理机器学习模型;
批判性地分析所获得的结果。
由于这些任务的复杂性通常超出非机器学习专家,因此机器学习应用程序的快速增长产生了现成(off-the-shelf)机器学习方法的需求,希望这些方法可以在没有专业知识的情况下轻松使用。有这样一个研究领域,让机器学习渐进地自动化,称为AutoML。作为机器学习的一个新的子领域,AutoML不仅在机器学习方面,而且在计算机视觉、自然语言处理和图形计算方面得到了更多的关注。
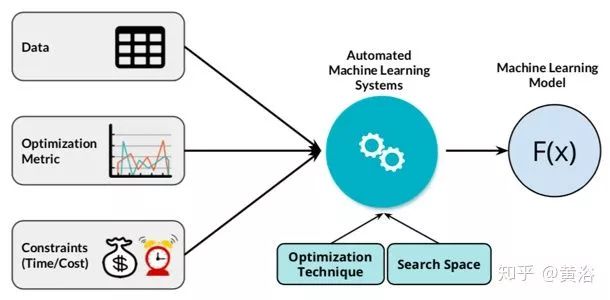
AutoML没有正式的定义。从大多数论文的描述中,AutoML的基本过程如下图所示:虚框是配置空间,包括特征、超参数和架构;左边训练数据进入,上面的优化器和它相连,定义的测度发现最佳配置,最后出来的是模型;测试数据在模型中运行,实现预测的目的。

AutoML方法已经足够成熟,可以与机器学习专家竞争,有时甚至超越这些专家。简而言之,AutoML可以提高性能,同时节省大量的时间和金钱,因为机器学习专家既难找又昂贵。因此,近年来对AutoML的商业兴趣急剧增长,几家主要的科技公司和初创公司正在开发自己的AutoML系统。
这是ML的框图:

而这是AutoML的框图:
虽然当前不同的AutoML工具和框架已经最小化了数据科学家在建模部分中的作用并节省了很多努力,但仍然有几个方面需要人为干预和解释,以便做出可以增强和影响建模步骤的正确决策。这些方面属于机器学习生产流程的两个主要构建块,即预建模和后建模(Pre-Modeling,Post-Modeling),如图ML产品流水线所示。

通常,预建模是机器学习管道的重要组成部分,可以显着影响自动算法选择和超参数优化过程的结果。预建模步骤包括许多步骤,包括数据理解、数据准备和数据验证。此外,后建模块还包括其他重要方面,包括对生成的机器学习模型如何管理和部署,该模型代表流水线中的一块石头,需要包装模型的再生性(reproducibility)。这两个构建块的各个方面可以帮助覆盖当前AutoML工具遗漏的内容,并帮助数据科学家以更加简单,有条理和信息丰富的方式完成工作。如图所示是能进一步自动化的工作:

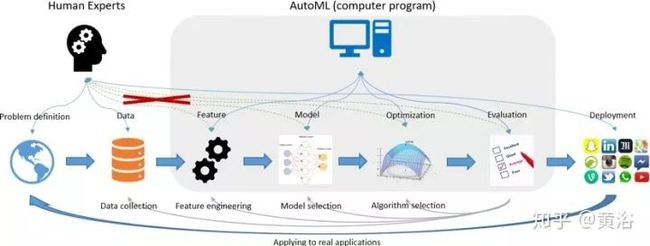
这是ML产品开发的流水线:为了使用ML技术并获得良好的性能,人们通常需要参与数据收集,特征工程,模型和算法选择。这张图片显示了典型的ML应用程序流水线,以及AutoML如何参与流水线并最大限度地减少人类的参与。
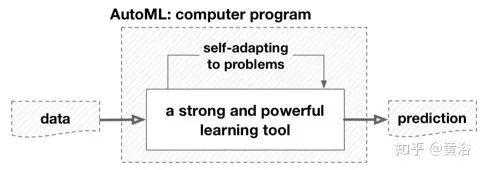
从ML角度看AutoML:从这个角度来看,AutoML本身也可以看作是一种学习工具,它对输入数据(即E)和给定任务(即T)具有良好的泛化性能(即P)。然而,传统的ML研究更多地关注发明和分析学习工具,它并不关心这些工具的使用有多容易。一个这样的例子恰恰是从简单模型到深度模型的最新趋势,它可以提供更好的性能,但也很难配置。相比之下,AutoML强调了学习工具的易用性。
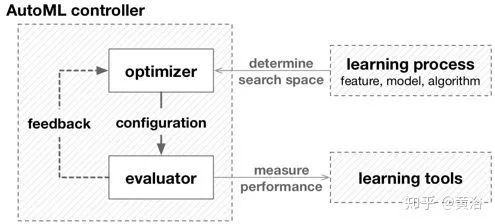
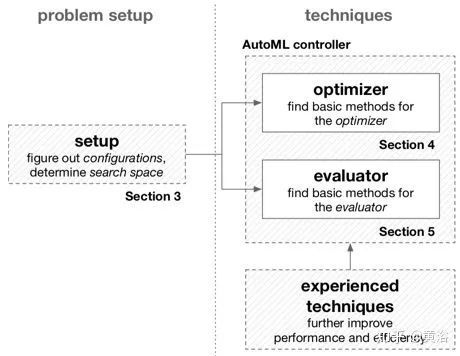
从自动化角度看AutoML:另一方面,自动化是使用各种控制系统在构建模块下运行。为了更好地预测性能,ML工具的配置应该通过输入数据适应任务,这通常是手动执行的。如图所示,从这个角度来看,AutoML的目标是在学习工具下构建高级控制方法,以便在没有人工帮助的情况下找到正确的配置。

Auto ML基本框架:控制器内部的虚线(反馈)取决于优化器使用的技术,不是必须的。
AutoML通过问题设置和技术来处理分类,这受到上图中提出的框架的启发。问题设置的分类取决于使用的学习工具,它阐明了想要自动化的“什么”; 技术分类取决于如何解决AutoML问题。具体来说,特征工程,通用机器学习应用的全部范围。
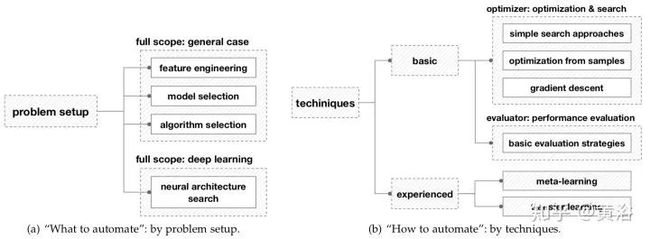
AutoML的设计流程图:接着上面的AutoML基本框架。
AutoML基本分以下几个方向:
• 自动数据清理(Auto Clean)
• 自动特征工程(AutoFE)
• 超参数优化(HPO)
• 元学习(meta learning)
• 神经网络架构搜索(NAS)
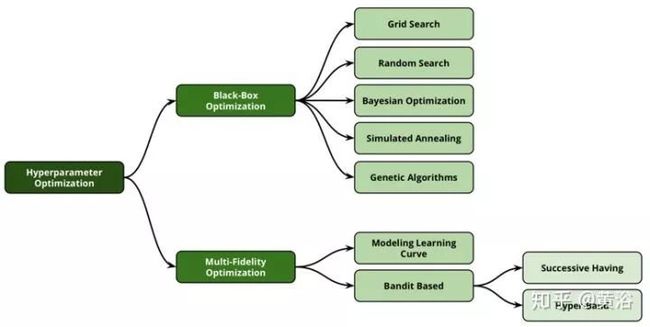
HPO方法分类:原则上,自动化超参优化技术可分为两大类:黑盒优化技术和多保真优化技术。
元学习分类:这些技术通常可以分为三大类,即基于任务属性的学习,从先前的模型评估中学习以及从已经预训练的模型中学习。

基于启发式搜索框架:它是基于群体的搜索方法,从初始化过程开始。

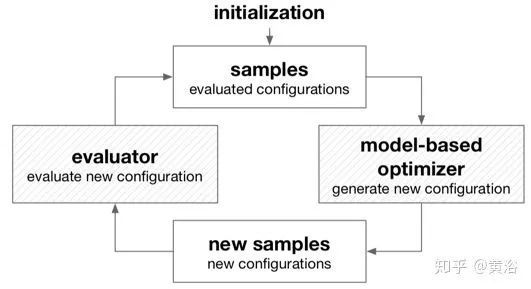
基于模型的无导数优化框架:与启发式搜索不同,基于模型的优化中最重要的组件是基于先前样本的模型。
基于强化学习的框架:与启发式搜索和基于模型的无导数优化不同,因为不需要为接收配置立即返回反馈。
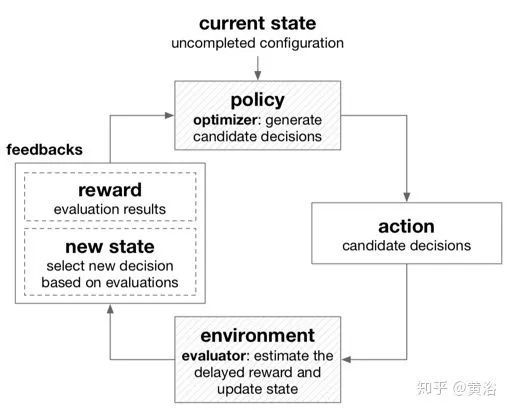
基于贪婪搜索的框架:它针对多步决策问题,在每步进行局部最优决策。

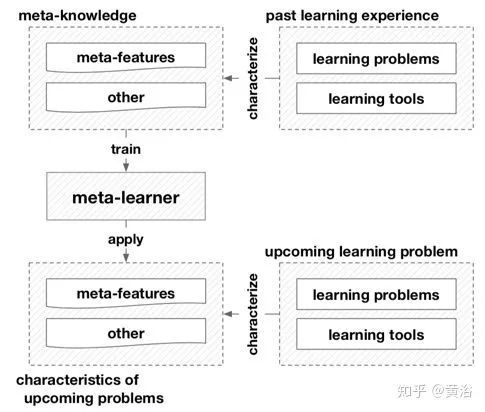
元学习一方面通过表征学习问题和工具来帮助AutoML。这些特性可以揭示关于问题和工具的重要信息,例如,数据中是否存在概念漂移(concept drift),或者模型是否与特定机器学习任务兼容。此外,利用这些特性,可以评估不同任务和工具之间的相似性,这使得不同问题之间的知识重用和转移(knowledge reuse and transfer)成为可能。一种简单但广泛使用的方法是在元特征空间(meta-feature space)中使用该任务的邻域经验最佳配置来推荐新任务的配置。另一方面,元学习者(meta-learner )编码过去的经验,并作为解决未来问题的指导。一旦经过训练,元学习者就可以快速评估学习工具的配置,免除计算昂贵的培训和模型评估。它们还可以生成有前途的配置,可以直接指定学习工具或作为搜索的良好初始化,或建议有效的搜索策略。因此,元学习可以极大地提高AutoML方法的效率。如图是基于元学习的框架。
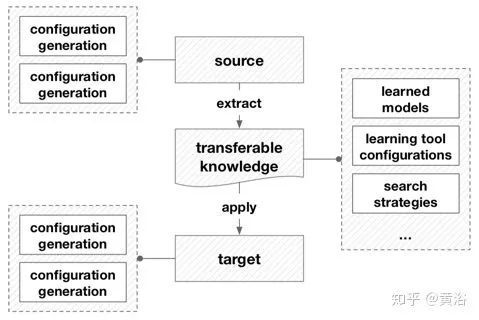
转移学习通过使用来自源域和学习任务的知识,尝试改进对目标域和学习任务的学习。在AutoML的上下文,传输的源和目标是配置生成或配置评估,其中前一个设置在AutoML实践之间传递知识,后者在AutoML实践中传递知识。另一方面,迄今为止在AutoML中利用的可转移知识通常是源配置生成或评估的最终或中间结果,例如学习工具的配置或参数,或在超参训练期间训练的替代模型。
下图是基于转移学习的框架,说明了转移学习在AutoML中的工作原理。
为使机器学习技术获得良好的性能,通常需要专家参与数据收集、特征工程、模型和算法选择。那么,AutoML参与这个开发流水线,并最大限度地减少人的参与。
某种程度上,它们是快而“肮”(大家不愿意做的工作)的方式,可以让我们很少量工作就能在机器学习任务获得高精度。如此简单有效的模式,不就是需要AI的目的!
下面重点讲NAS。
开发神经网络模型通常需要大量的架构工程。有时可以通过转移学习(transfer learning)获得,但如果真的想要获得最优性能,通常最好设计网络。但这需要专业技能(从商业角度看是昂贵的)并且总的来说具有挑战性;甚至可能不知道当前(SOA)技术的局限性!这是一个需要很多试验和错误(trial and error)的工作,其实实验本身是耗时且昂贵的。这就是NAS有了用武之地。
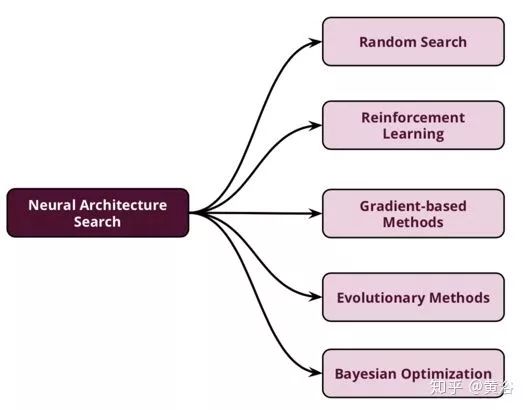
下面是NAS的分类图:从广义上讲,NAS技术分为五大类,包括随机搜索,强化学习,基于梯度的方法,进化方法和贝叶斯优化。
在感知任务中深度学习的成功很大程度上归功于其特征工程的自动化:分层特征提取器以端到端的方式从数据中学习而不是手动设计。然而,这种成功伴随着对架构工程的的需求也不断增长,其中越来越复杂的神经网络架构仍然被手动设计。神经网络架构搜索(NAS)是架构自动化工程,是机器学习自动化合乎逻辑的下一步。
NAS看作AutoML的子域,并且与HPO和元学习有重叠。根据三个维度,可以对NAS的现有方法进行分类:搜索空间,搜索策略和性能评估策略:
搜索空间(Search Space): 搜索空间原则上定义了可以代表哪些体系结构。结合适用于任务属性的先验知识可以减小搜索空间大小并简化搜索。然而,这也引入了人为偏见,可能会阻止找到超越当前人类知识的新颖架构构建块(building blocks)。
搜索策略(Search strategy):搜索策略说明了如何做空间搜索。它包含了经典的探索-开发(exploration-exploitation)之间的权衡。一方面,需要快速找到性能良好的架构,另一方面,避免过早收敛到次优架构(suboptimal architecture)区域。
性能评估策略(Performance estimation strategy):NAS的目标通常是找到在未知数据实现高预测性能的架构。性能评估是指评估此性能的过程:最简单的选择是对数据架构执行标准训练和验证,但遗憾的是,这种方法计算成本很高,限制了可以探索的体系结构量。因此,最近的研究大多集中在开发出方法去降低这些性能估计成本。
• 搜索空间
搜索空间定义了NAS原则上可以发现的神经架构。如下是神经结构搜索方法的抽象示意图:“搜索策略”从预定义的“搜索空间”A中选择体系结构A;该架构被传递到“性能估计策略”,该策略将A估计的性能返回到搜索策略。
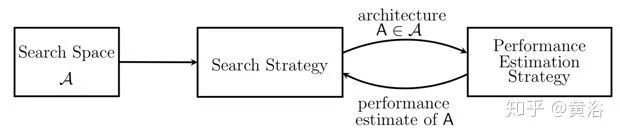
如下是不同架构空间的示意图:每个节点对应于神经网络的层,例如卷积层或池化层。不同的层类型注以不同的颜色。从层Li到层Lj的边表示Li接收Lj的输出作为输入。左:链式结构空间的元素。右:具有另外的层类型、多个分支和跳连接的复杂搜索空间元素。比如残差网络(ResNet)和致密网络(DenseNet)。

通过以下方式搜索空间被参数化:(i)层数(可能无界); (ii)每层可以执行的操作类型,例如池化,卷积或更高级类型,像深度可分离卷积或扩张卷积; (iii)与操作相关的超参数,例如,滤波器数量,核尺寸和卷积层步幅等,或简单的全连接网络的单位数。
另外一种搜索方法,是寻找网络重复的motifs,称为细胞(cells),而不是整个架构。定义了两种不同类型的细胞:保持输入维度的正常(normal)细胞和减少空间维度的缩减(reduction)细胞。然后以预定义的方式堆叠这些细胞构建最终的体系结构,如下图所示:左边是两种不同的细胞,如正常细胞(顶部)和缩减细胞(底部);右边是通过串行堆叠细胞构建的结构。
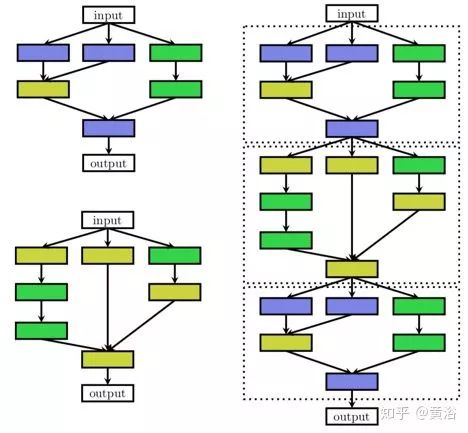
与上面讨论的相比,该搜索空间具有两个主要优点:
1. 搜索空间大小大大减少,因为细胞可以相当小。
2. 通过调整模型使用的细胞数,可以更容易地将细胞转移到其他数据集。
• 搜索策略
各种不同的搜索策略可用于探索神经架构的空间,包括随机搜索,贝叶斯优化(BO),进化方法,强化学习(RL)和基于梯度的方法。自2013年以来,贝叶斯优化在NAS中取得了一些早期成功。但2017之后,NAS成为机器学习社区的主流研究课题。
为了将NAS定义为强化学习(RL)问题,可以认为神经网络结构的生成是代理(agent)的动作,动作空间与搜索空间相同。代理的奖励(award)基于训练架构对未见数据的性能估计。不同RL方法区别在代理的策略(policy)以及如何优化,比如用Q-学习来训练一个策略,该策略依次选择层的类型以及超参数。另一种观点是作为顺序决策过程(sequential decision processes),其中策略采样动作串行地生成架构,环境的“状态”包含采样动作的摘要,和最终行动之后才能获得的(未兑现)奖励。但是,由于在串行过程中没有发生与环境的交互(无观测的外部状态,也没有中间奖励),将架构采样过程解释为单个行动的序列生成更为直观;这将RL问题简化为一个无状态、多臂强盗问题(multi-armed bandit problem)。
另一种方法是使用进化算法优化神经网络结构的神经进化(neuro-evolutionary)方法。进化算法演化了一组模型,即一组(可能是训练过的)网络;在每个进化步骤中,至少有一个来自群体(population)的模型被采样并作为父母(parent)用突变(mutations)来产生后代(offsprings)。在NAS的上下文中,突变是局部操作,例如添加或移除层、改变层的超参数、添加跳连接以及改变训练超参数。对后代进行训练之后,评估它们的适应性(fitness)并将它们添加到群体中。神经进化法的不同体现在如何对父母抽样、更新群体和产生后代等。
与上面的无梯度优化方法相比,DART【4】是一个对搜索空间连续松弛以实现基于梯度优化(gradient-based optimization)的方法:不是固定单个操作oi(例如,卷积或池化)在一个特定的层中,而是从一组操作{o1,...,om}中计算出一个凸组合。更具体地,给定一个层输入x,层输出y被计算为
其中凸系数λi有效地参数化网络架构。然后,交替权重训练数据和架构参数(如λ)验证数据执行梯度下降,依此优化网络权重和网络架构。最终,为每个层选择i = argmaxi λi的操作i获得离散架构。
• 性能评估策略
为了指导搜索过程,各种搜索策略需要估计在给定架构A的性能。最简单的方法是在训练数据上训练架构A并评估其在验证数据上的表现。然而,从头开始训练和评估每个体系结构经常产生数千GPU天级别的计算需求。为了减少这种计算负担,可以在完全训练之后取实际性能的较低保真度来估计性能(代理度量)。虽然这些低保真近似值会降低计算成本,但也会在估算中引入偏差。只要搜索策略仅是对不同体系结构进行排名并且这种相对排名稳定,这可能不会成为问题,但实际情况还是不那么简单。估计架构性能的另一种可能方式建立在学习曲线外推(learning curve extrapolation)的基础上。
加速性能估计的另一种方法是基于已训练过的其他架构权重来初始化新架构的权重。实现这一目标的一种方法,称为网络态射(network morphism)。
一次性架构搜索(One-Shot Architecture Search)是另一种加速性能评估的方法,它将所有架构视为超级图(supergraph)的不同子图,在超图的边缘各架构之间共享权重。仅训练一次性模型(one-shot model)的权重来直接评估架构(一次性模型的子图)。这大大加快了架构的性能评估,因为不需要训练(仅评估验证数据的性能)。这种方法通常会产生很大的偏差,因为它严重低估了架构的实际性能;不管怎样,它允许排名架构可靠,因为估计的性能与实际性能强烈相关。不同的一次性(one shot)NAS方法在一次性模型的训练方式上有所不同:ENAS【5】学习了一个RNN控制器,从搜索空间中对架构进行采样,并根据通过REINFORCE获得的近似梯度训练一次性模型;DARTS【4】优化了一次性模型的所有权重,同时在一次性模型的每个边缘放置混合的候选操作,对搜索空间做连续松弛。权重共享和分布固定(精心选择)可能(可能令人惊讶地)是一次性NAS必需的。
与这些方法相关的是超网络(hypernetworks)的元学习,它为新架构生成权重,只需要训练超网络而不是那些架构本身。这里的主要区别在于,权重不是严格共享的,而是从取决于架构和超网络表示的分布中采样得到。
一般地,一次性NAS的限制是,超级图定义的先验条件限制搜索空间是它的子图。此外,在架构搜索期间要求整个超级图驻留在GPU存储器中的方法,相应地也受限于相对较小的超图和搜索空间,通常使用中只能与基于细胞的搜索空间结合。虽然基于权重共享的方法已经大大减少了NAS所需的计算资源(从数千GPU天到几个GPU天),但如果架构的采样分布和一次性模型一起优化的话,目前尚不清楚它们引入搜索的偏差。
参考文献
1. Zoph, B., Le, Q.V. “Neural Architecture Search with Reinforcement Learning”. ArXiv 1611.01578,2017
2. G Seif,“Everything You Need to Know About AutoML and Neural Architecture Search”,kdnuggets.com/2018/09/e
3. Real, E., Aggarwal, A., Huang, Y., Le, Q.V. “Regularized Evolution for Image Classifier Architecture Search”. ArXiv 1802.01548,2018
4. Liu H, Simonyan K, Yang Y,“Darts: Differentiable architecture search”. arXiv 1806.09055,2018
5. Pham H, Guan M, Zoph B, Le Q, Dean J,“Efficient neural architecture search via parameter sharing”,International Conference on Machine Learning,2018
6. Bender G, Kindermans P, Zoph B, Vasudevan V, Le Q ,“Understanding and simplifying one-shot architecture search”. International Conference on Machine Learning,2018
7. Wistuba, M., Rawat, A., Pedapati, T. “A Survey on Neural Architecture Search”. ArXiv 1905.01392. 2019
8. Li, L., Talwalkar, A.“Random Search and Reproducibility for Neural Architecture Search”. ArXiv 1902.07638. 2019
9. Xie, S., Zheng, H., Liu, C., Lin, L.. “SNAS: Stochastic Neural Architecture Search”. ArXiv 1812.09926. 2019
10. Guo, Z., Zhang, X., Mu, H., Heng, W., Liu, Z., Wei, Y., & Sun, J. “Single Path One-Shot Neural Architecture Search with Uniform Sampling”. ArXiv 1904.00420,2019.
11. Cai, H., Zhu, L., Han, S. “ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware”. ArXiv 1812.00332,2019.
12. M Zoeller,M Huber,“Survey on Automated Machine Learning”,arXiv 1904.12054,2019
13. R Elshawi, M Maher, S Sakr,“Automated Machine Learning: State-of-The-Art and Open Challenges ”,arXiv 1906.02287,2019
14. Q Yao et al.,“Taking the Human out of Learning Applications: A Survey on Automated Machine Learning”, arXiv 1810.13306, 2018
AutoML-NAS微信群
关注最新的AutoML、NAS技术,欢迎加入专业交流群,扫码添加CV君拉你入群,(如已为CV君好友请直接私信)
(请务必注明:AutoML)

喜欢在QQ交流的童鞋,可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过验证还请见谅)

长按关注我爱计算机视觉