Transformer端侧模型压缩——Mobile Transformer
随着Transformer模型在NLP、ASR等序列建模中的普及应用,其在端侧等资源受限场景的部署需求日益增加。经典的mobile-transformer结构包括evolved tansformer、lite-transformer、mobile-bert、miniLM等模型,借助结构改进、知识蒸馏等策略实现了transformer模型的小型化、并确保精度鲁棒性。
1. The Evolved Transformer
Paper Link: https://arxiv.org/abs/1901.11117
GitHub: https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/evolved_transformer.py
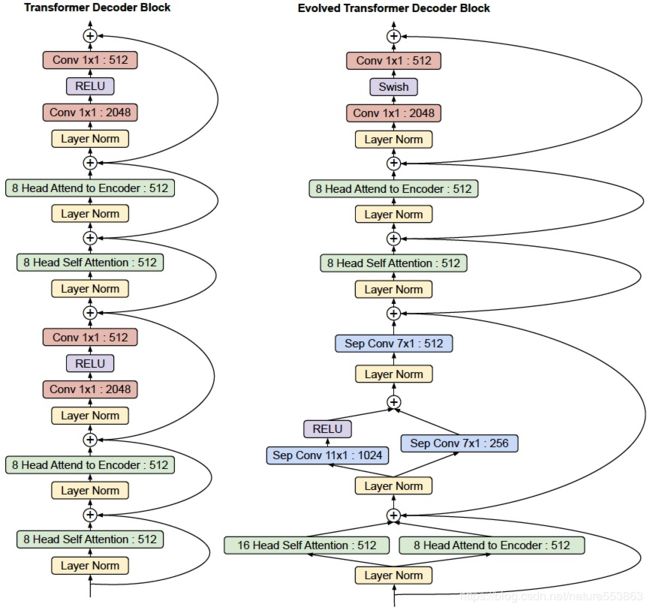
Google基于NAS搜索获得的Transformer结构:
- 搜索空间:包括两个stackable cell,分别包含在transformer encoder与transformer decoder。每个cell由NAS-style block组成, 可通过左右两个block转换输入Embedding、再聚合获得新的Embedding,进一步输入到self-attention layer。
- 搜索策略:基于EA (Evolutional Aligorithm)的搜索策略;
网络结构如下:

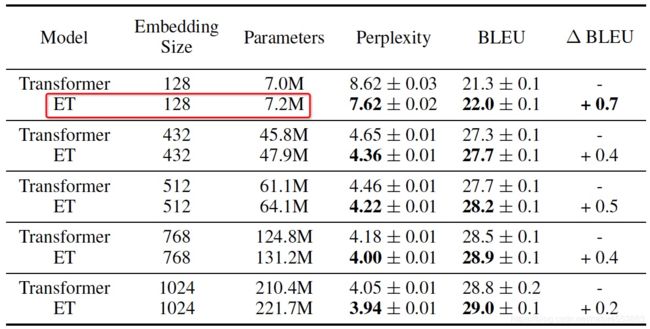
2. Lite Transformer with Long-Short Range Attention
Paper Link: https://arxiv.org/abs/2004.11886
GitHub: https://github.com/mit-han-lab/lite-transformer
Lite Transformer是韩松组研究提出的一种高效、面向移动端部署的Transformer架构,其核心是长短距离注意力结构(Long-Short Range Attention,LSRA)。LSRA将输入Embedding沿feature维度split成两部分,其中一部分通过GLU、一维卷积,用以提取局部context信息;而另一部分依靠self-attention,用以负责全局相关性信息编码。
Lite Transformer核心结构如下:
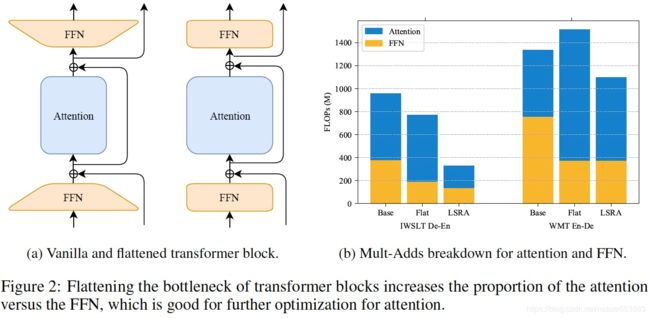
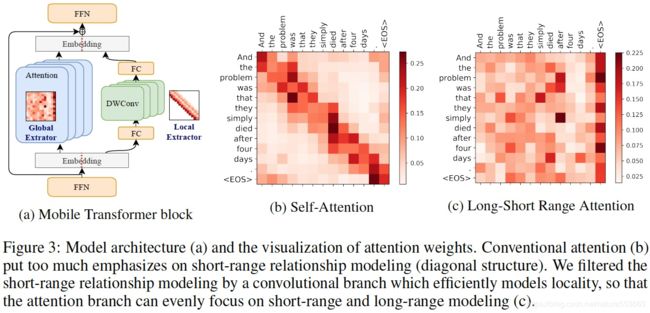

3. HAT: Hardware-Aware Transformers for Efficient Natural Language Processing
Paper Link: https://arxiv.org/abs/2005.14187
GitHub: https://github.com/mit-han-lab/hardware-aware-transformers
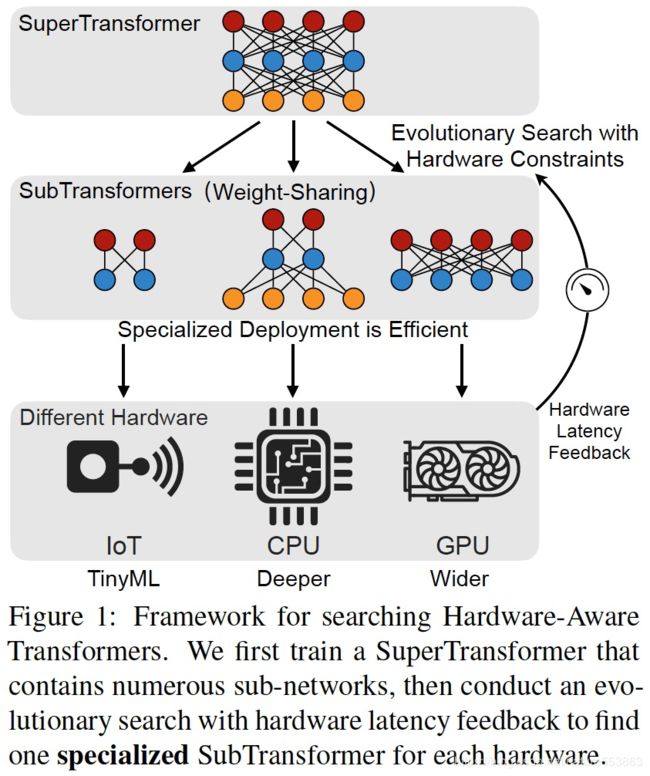
HAT是韩松组研究提出的one for all网络,sub-transformer通过共享super-transformer的网络参数,可实现不同部署平台与硬件设备的快速适配。设计核心包括arbitrary encoder-decoder attention、以及elastic网络结构 (hidden size、embed-size、layers等)。
One for all自动化部署流程、以及核心网络结构如下:



4. MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Paper Link: https://arxiv.org/abs/2004.02984
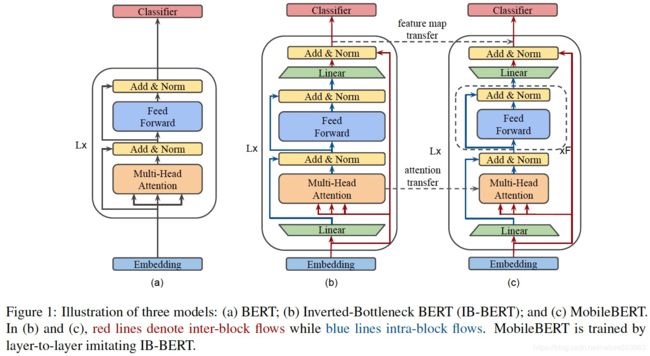
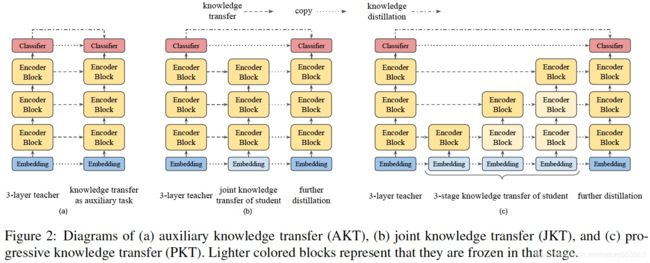
Google Brain提出了MobileBERT,该模型是与任务无关的,即可以通过简单的微调、应用于各种下游NLP任务。基本上,MobileBERT是BERT_LARGE的精简版,同时配备了bottleneck结构和self-attention与ffn之间的平衡。为了训练MobileBERT,首先训练了一个特别设计的教师模型 (包含Inverted Attention Block),然后通过知识蒸馏诱导MobileBERT的训练。
具体的网络结构与蒸馏机制如下:
5. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
Paper Link: https://arxiv.org/abs/2002.10957
GitHub: https://github.com/microsoft/unilm/tree/master/minilm
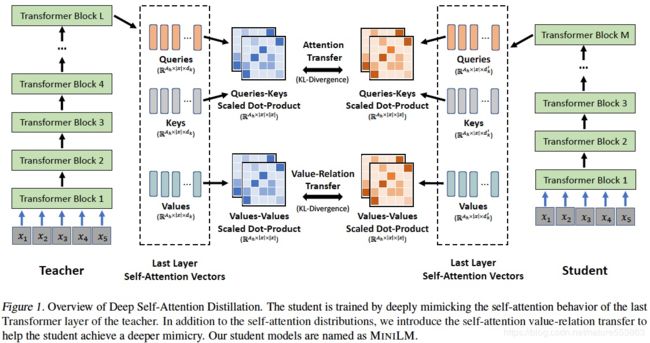
微软研究院提出了基于 Transformer预训练模型的通用压缩方法:深度自注意力知识蒸馏(Deep Self-Attention Distillation),通过迁移teacher model最后一层self-attention layer的attention score信息与value relation信息,可有效实现student model的诱导训练。只迁移最后一层的知识,显得简单有效、且训练速度更快,而且不需要手动设计teacher-student之间的层对应关系。
Attention score信息与Value relation信息的知识迁移如下:
Attention score transfer:

Value relation transfer:

6. Miscellaneous
关于Separable Conv1d在序列模型中的应用、及优势,可参考:Depthwise Separable Convolutions for Neural Machine Translation;
移动端推理框架可参考:MNN、NCNN、Paddle-lite、Tengine、TNN、TF-lite等;