目标检测网络的知识蒸馏
"Learning Efficient Object Detection Models with Knowledge Distillation"这篇文章通过知识蒸馏(Knowledge Distillation)与Hint指导学习(Hint Learning),提升了主干精简的多分类目标检测网络的推理精度(文章以Faster RCNN为例),例如Faster RCNN-Alexnet、Faster-RCNN-VGGM等,具体框架如下图所示:
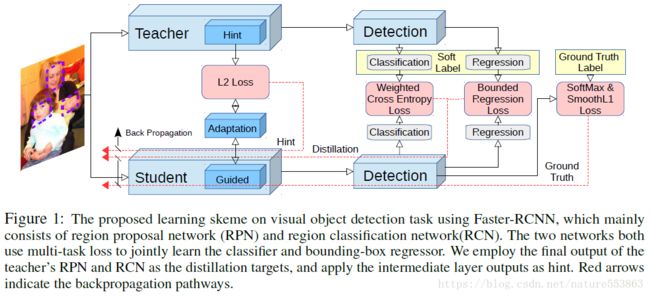
教师网络的暗知识提取分为三点:中间层Feature Maps的Hint;RPN/RCN中分类层的暗知识;以及RPN/RCN中回归层的暗知识。具体如下:

具体指导学生网络学习时,RPN与RCN的分类损失由分类层softmax输出与hard target的交叉熵loss、以及分类层softmax输出与soft target的交叉熵loss构成:
![]()
由于检测器需要鉴别的不同类别之间存在样本不均衡(imbalance),因此在L_soft中需要对不同类别的交叉熵分配不同的权重,其中背景类的权重为1.5(较大的比例),其他分类的权重均为1.0:
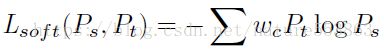
RPN与RCN的回归损失由正常的smooth L1 loss、以及文章所定义的teacher bounded regression loss构成:
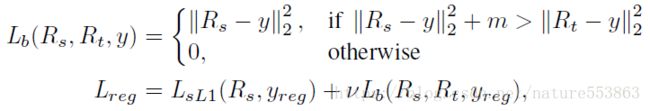
其中Ls_L1表示正常的smooth L1 loss,Lb表示文章定义的teacher bounded regression loss。当学生网络的位置回归与ground truth的L2距离超过教师网络的位置回归与ground truth的L2距离、且大于某一阈值时,Lb取学生网络的位置回归与ground truth之间的L2距离,否则Lb置0。
Hint learning需要计算教师网络与学生网络中间层输出的Feature Maps之间的L2 loss,并且在学生网络中需要添加可学习的适配层(adaptation layer),以确保guided layer输出的Feature Maps与教师网络输出的Hint维度一致:
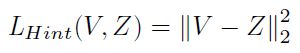
通过知识蒸馏、Hint指导学习,提升了精简网络的泛化性、并有助于加快收敛,最后取得了良好的实验结果,具体见文章实验部分。
以SSD为例,KD loss与Teacher bounded L2 loss设计如下:
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..box_utils import match, log_sum_exp
eps = 1e-5
def KL_div(p, q, pos_w, neg_w):
p = p + eps
q = q + eps
log_p = p * torch.log(p / q)
log_p[:,0] *= neg_w
log_p[:,1:] *= pos_w
return torch.sum(log_p)
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
cfg, use_gpu=True, neg_w=1.5, pos_w=1.0, Temp=1., reg_m=0.):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes # 21
self.threshold = overlap_thresh # 0.5
self.background_label = bkg_label # 0
self.encode_target = encode_target # False
self.use_prior_for_matching = prior_for_matching # True
self.do_neg_mining = neg_mining # True
self.negpos_ratio = neg_pos # 3
self.neg_overlap = neg_overlap # 0.5
self.variance = cfg['variance']
# soft-target loss
self.neg_w = neg_w
self.pos_w = pos_w
self.Temp = Temp
self.reg_m = reg_m
def forward(self, predictions, pred_t, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
pred_t (tuple): teacher's predictions
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# predictions of teachers
loc_teach1, conf_teach1 = pred_t[0]
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
# wrap targets
with torch.no_grad():
if self.use_gpu:
loc_t = loc_t.cuda(non_blocking=True)
conf_t = conf_t.cuda(non_blocking=True)
pos = conf_t > 0 # (1, 0, 1, ...)
num_pos = pos.sum(dim=1, keepdim=True) # [num, 1], number of positives
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data) # [batch,num_priors,1] before expand_as
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# knowledge transfer for loc regression
# teach1
loc_teach1_p = loc_teach1[pos_idx].view(-1, 4)
l2_dis_s = (loc_p - loc_t).pow(2).sum(1)
l2_dis_s_m = l2_dis_s + self.reg_m
l2_dis_t = (loc_teach1_p - loc_t).pow(2).sum(1)
l2_num = l2_dis_s_m > l2_dis_t
l2_loss_teach1 = l2_dis_s[l2_num].sum()
l2_loss = l2_loss_teach1
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf.float()) - batch_conf.gather(1, conf_t.view(-1, 1)).float()
# Hard Negative Mining
loss_c[pos.view(-1, 1)] = 0
loss_c = loss_c.view(num, -1)
#loss_c[pos] = 0 # filter out pos boxes for now
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
# CrossEntropy loss
pos_idx = pos.unsqueeze(2).expand_as(conf_data) # [batch,num_priors,cls]
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# soft loss for Knowledge Distillation
# teach1
conf_p_teach = conf_teach1[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
pt = F.softmax(conf_p_teach/self.Temp, dim=1)
if self.neg_w > 1.:
ps = F.softmax(conf_p/self.Temp, dim=1)
soft_loss1 = KL_div(pt, ps, self.pos_w, self.neg_w) * (self.Temp**2)
else:
ps = F.log_softmax(conf_p/self.Temp, dim=1)
soft_loss1 = nn.KLDivLoss(size_average=False)(ps, pt) * (self.Temp**2)
soft_loss = soft_loss1
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum().float()
loss_l = loss_l.float()
loss_c = loss_c.float()
loss_l /= N
loss_c /= N
l2_loss /= N
soft_loss /= N
return loss_l, loss_c, soft_loss, l2_loss
Paper地址:https://papers.nips.cc/paper/6676-learning-efficient-object-detection-models-with-knowledge-distillation.pdf
PyTorch版SSD:https://github.com/amdegroot/ssd.pytorch