LSM Tree-Based存储引擎的compaction策略(feat. RocksDB)
前言
这篇从半个月前就开始写,断断续续写到现在,终于能发了(被简书吞了好几次),不容易。
最近笔者正在补习与RocksDB底层相关的细节,因为:
- 次要原因——当前所有Flink实时任务的状态后端都是RocksDB;
- 主要原因——将来会利用TiDB搭建HTAP服务。TiDB与我们现有的MySQL可以无缝衔接,并且它的基础正是RocksDB。
RocksDB与笔者多次讲过的HBase一样,都属于基于LSM树的存储引擎,只不过前者偏向嵌入式用途,更轻量级而已。看官可以先食用这篇文章获得关于LSM树的前置知识。
下面先粗略看看RocksDB的读写流程,其实与HBase是很像的。
RocksDB读写简介
直接画图说明。这张图取自Flink PMC大佬Stefan Richter在Flink Forward 2018演讲的PPT,笔者重画了一下。

RocksDB的写缓存(即LSM树的最低一级)名为memtable,对应HBase的MemStore;读缓存名为block cache,对应HBase的同名组件。
执行写操作时,先同时写memtable与预写日志WAL。memtable写满后会自动转换成不可变的(immutable)memtable,并flush到磁盘,形成L0级sstable文件。sstable即有序字符串表(sorted string table),其内部存储的数据是按key来排序的,后文将其简称为SST。
执行读操作时,会首先读取内存中的数据(根据局部性原理,刚写入的数据很有可能被马上读取),即active memtable→immutable memtable→block cache。如果内存无法命中,就会遍历L0层sstable来查找。如果仍未命中,就通过二分查找法在L1层及以上的sstable来定位对应的key。
随着sstable的不断写入,系统打开的文件就会越来越多,并且对于同一个key积累的数据改变(更新、删除)操作也就越多。由于sstable是不可变的,为了减少文件数并及时清理无效数据,就要进行compaction操作,将多个key区间有重合的sstable进行合并。本文暂无法给出"compaction"这个词的翻译,个人认为把它翻译成“压缩”(compression?)或者“合并”(merge?)都是片面的。
通过上面的简介,我们会更加认识到,LSM树是一种以读性能作为trade-off换取写性能的结构,并且RocksDB中的flush和compaction操作正是LSM思想的核心。下面来介绍LSM-based存储中通用的两种compaction策略,即size-tiered compaction和leveled compaction。
通用compaction策略
size-tiered compaction与空间放大
size-tiered compaction的思路非常直接:每层允许的SST文件最大数量都有个相同的阈值,随着memtable不断flush成SST,某层的SST数达到阈值时,就把该层所有SST全部合并成一个大的新SST,并放到较高一层去。下图是阈值为4的示例。
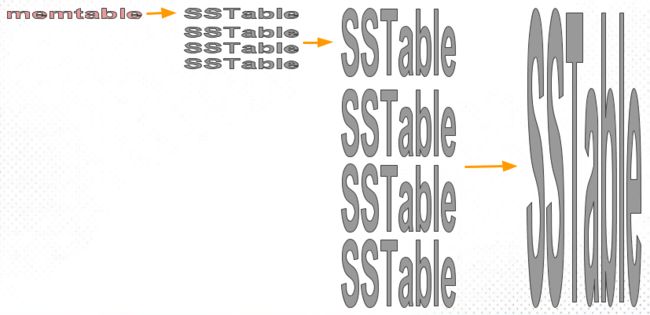
size-tiered compaction的优点是简单且易于实现,并且SST数目少,定位到文件的速度快。当然,单个SST的大小有可能会很大,较高的层级出现数百GB甚至TB级别的SST文件都是常见的。它的缺点是空间放大比较严重,下面详细说说。
所谓空间放大(space amplification),就是指存储引擎中的数据实际占用的磁盘空间比数据的真正大小偏多的情况。例如,数据的真正大小是10MB,但实际存储时耗掉了25MB空间,那么空间放大因子(space amplification factor)就是2.5。
为什么会出现空间放大呢?很显然,LSM-based存储引擎中数据的增删改都不是in-place的,而是需要等待compaction执行到对应的key才算完。也就是说,一个key可能会同时对应多个value(删除标记算作特殊的value),而只有一个value是真正有效的,其余那些就算做空间放大。另外,在compaction过程中,原始数据在执行完成之前是不能删除的(防止出现意外无法恢复),所以同一份被compaction的数据最多可能膨胀成原来的两倍,这也算作空间放大的范畴。
下面用Cassandra的size-tiered compaction策略举两个例子,以方便理解。每层SST个数的阈值仍然采用默认值4。
- 以约3MB/s的速度持续插入新数据(保证unique key),时间与磁盘占用的曲线图如下。
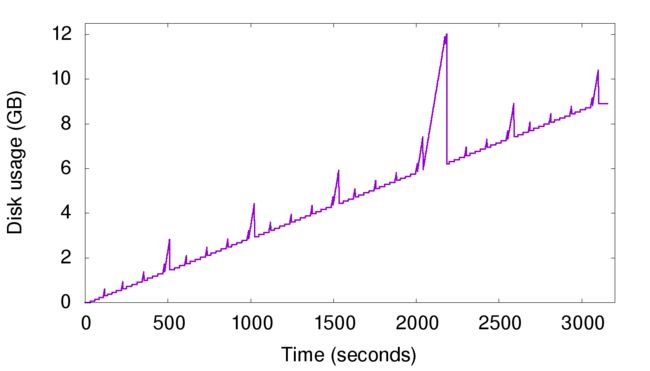
图中清晰可见有不少毛刺,这就是compaction过程造成的空间放大。注意在2000s~2500s之间还有一个很高的尖峰,原数据量为6GB,但在一瞬间增长到了12GB,说明Cassandra在做大SST之间的compaction,大SST的缺陷就显现出来了。尽管这只是暂时的,但是也要求我们必须预留出很多不必要的空闲空间,增加成本。
- 重复写入一个400万条数据的集合(约1.2GB大,保证unique key),共重复写入15次来模拟数据更新,时间与磁盘占用的曲线图如下。

这种情况更厉害,最高会占用多达9.3GB磁盘空间,放大因子为7.75。虽然中途也会触发compaction,但是最低只能压缩到3.5GB左右,仍然有近3倍的放大。这是因为重复key过多,就算每层compaction过后消除了本层的空间放大,但key重复的数据仍然存在于较低层中,始终有冗余。只有手动触发了full compaction(即图中2500秒过后的最后一小段),才能完全消除空间放大,但我们也知道full compaction是极耗费性能的。
接下来介绍leveled compaction,看看它是否能解决size-tiered compaction的空间放大问题。
leveled compaction与写放大
leveled compaction的思路是:对于L1层及以上的数据,将size-tiered compaction中原本的大SST拆开,成为多个key互不相交的小SST的序列,这样的序列叫做“run”。L0层是从memtable flush过来的新SST,该层各个SST的key是可以相交的,并且其数量阈值单独控制(如4)。从L1层开始,每层都包含恰好一个run,并且run内包含的数据量阈值呈指数增长。
下图是假设从L1层开始,每个小SST的大小都相同(在实际操作中不会强制要求这点),且数据量阈值按10倍增长的示例。即L1最多可以有10个SST,L2最多可以有100个,以此类推。

随着SST不断写入,L1的数据量会超过阈值。这时就会选择L1中的至少一个SST,将其数据合并到L2层与其key有交集的那些文件中,并从L1删除这些数据。仍然以上图为例,一个L1层SST的key区间大致能够对应到10个L2层的SST,所以一次compaction会影响到11个文件。该次compaction完成后,L2的数据量又有可能超过阈值,进而触发L2到L3的compaction,如此往复,就可以完成Ln层到Ln+1层的compaction了。
可见,leveled compaction与size-tiered compaction相比,每次做compaction时不必再选取一层内所有的数据,并且每层中SST的key区间都是不相交的,重复key减少了,所以很大程度上缓解了空间放大的问题。重复一遍上一节做的两个实验,曲线图分别如下。
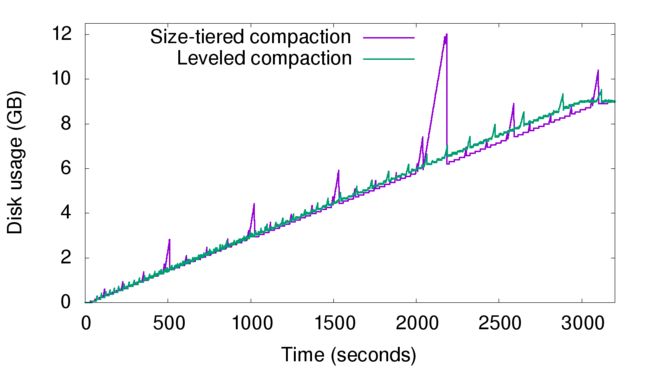
持续写入实验,尖峰消失了。
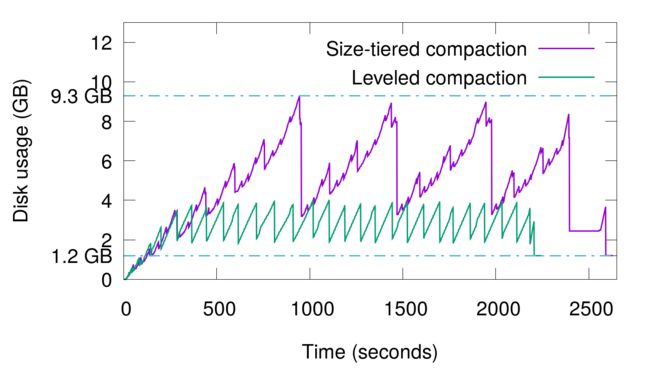
持续更新实验,磁盘占用量的峰值大幅降低,从原来的9.3GB缩减到了不到4GB。
但是鱼与熊掌不可兼得,空间放大并不是唯一掣肘的因素。仍然以size-tiered compaction的第一个实验为例,写入的总数据量约为9GB大,但是查看磁盘的实际写入量,会发现写入了50个G的数据。这就叫写放大(write amplification)问题。
写放大又是怎么产生的呢?下面的图能够说明。
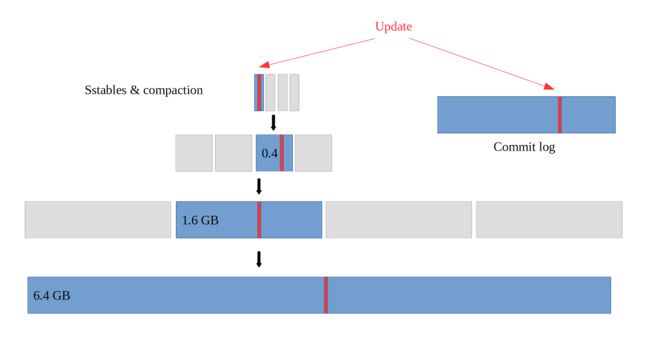
可见,这是由compaction的本质决定的:同一份数据会不断地随着compaction过程向更高的层级重复写入,有多少层就会写多少次。但是,我们的leveled compaction的写放大要严重得多,同等条件下实际写入量会达到110GB,是size-tiered compaction的两倍有余。这是因为Ln层SST在合并到Ln+1层时是一对多的,故重复写入的次数会更多。在极端情况下,我们甚至可以观测到数十倍的写放大。
写放大会带来两个风险:一是更多的磁盘带宽耗费在了无意义的写操作上,会影响读操作的效率;二是对于闪存存储(SSD),会造成存储介质的寿命更快消耗,因为闪存颗粒的擦写次数是有限制的。在实际使用时,必须权衡好空间放大、写放大、读放大三者的优先级。
RocksDB的混合compaction策略
由于上述两种compaction策略都有各自的优缺点,所以RocksDB在L1层及以上采用leveled compaction,而在L0层采用size-tiered compaction。下面分别来看看。
leveled compaction
当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。
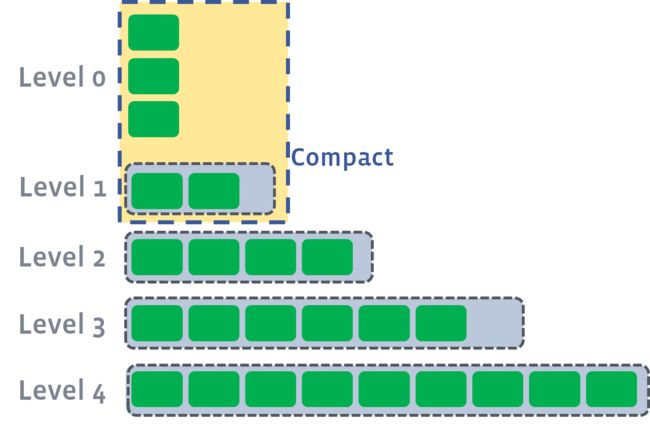
L1层及以后的compaction过程完全符合前文所述的leveled compaction逻辑,如下图所示,很容易理解。

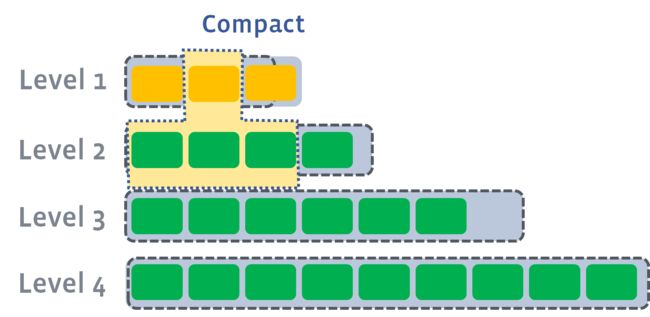

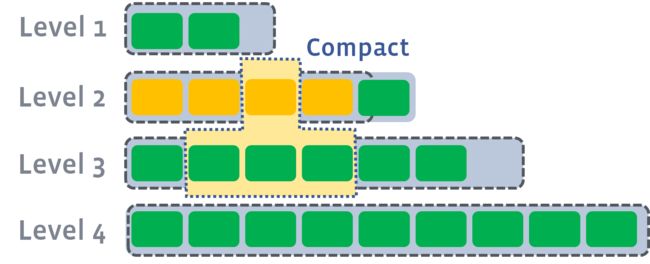
多个compaction过程是可以并行进行的,如下图所示。最大并行数由max_background_compactions参数来指定。

前面说过,leveled compaction策略中每一层的数据量是有阈值的,那么在RocksDB中这个阈值该如何确定呢?需要分两种情况来讨论。
- 参数
level_compaction_dynamic_level_bytes为false
这种情况下,L1层的大小阈值直接由参数max_bytes_for_level_base决定,单位是字节。各层的大小阈值会满足如下的递推关系:
target_size(Lk+1) = target_size(Lk) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_additional[k]
其中,max_bytes_for_level_multiplier是固定的倍数因子,max_bytes_for_level_multiplier_additional[k]是第k层对应的可变倍数因子。举个例子,假设max_bytes_for_level_base = 314572800,max_bytes_for_level_multiplier = 10,所有max_bytes_for_level_multiplier_additional[k]都为1,那么就会形成如下图所示的各层阈值。

可见,这与上文讲leveled compaction时的示例是一个意思。
- 参数
level_compaction_dynamic_level_bytes为true
这种情况比较特殊。最高一层的大小不设阈值限制,亦即target_size(Ln)就是Ln层的实际大小,而更低层的大小阈值会满足如下的倒推关系:
target_size(Lk-1) = target_size(Lk) / max_bytes_for_level_multiplier
可见,max_bytes_for_level_multiplier的作用从乘法因子变成了除法因子。特别地,如果出现了target_size(Lk) < max_bytes_for_level_base / max_bytes_for_level_multiplier的情况,那么这一层及比它低的层就都不会再存储任何数据。
举个例子,假设现在有7层(包括L0),L6层已经存储了276GB的数据,并且max_bytes_for_level_base = 1073741824,max_bytes_for_level_multiplier = 10,那么就会形成如下图所示的各层阈值,亦即L5~L1的阈值分别是27.6GB、2.76GB、0.276GB、0、0。
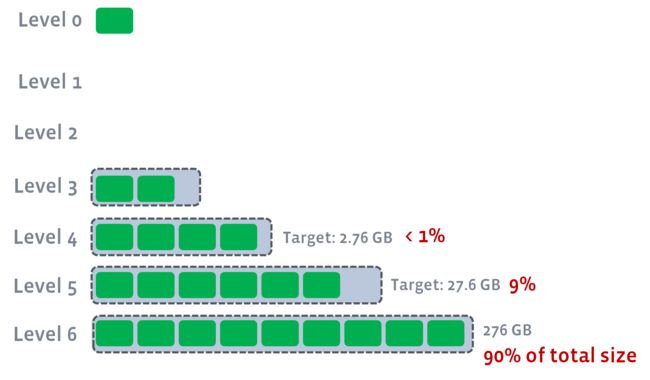
可见,有90%的数据都落在了最高一层,9%的数据落在了次高一层。由于每个run包含的key都是不重复的,所以这种情况比上一种更能减少空间放大。
universal compaction
universal compaction是RocksDB中size-tiered compaction的别名,专门用于L0层的compaction,因为L0层的SST的key区间是几乎肯定有重合的。
前文已经说过,当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。universal compaction还会检查以下条件。
空间放大比例
假设L0层现有的SST文件为(R1, R1, R2, ..., Rn),其中R1是最新写入的SST,Rn是较旧的SST。所谓空间放大比例,就是指R1~Rn-1文件的总大小除以Rn的大小,如果这个比值比max_size_amplification_percent / 100要大,那么就会将L0层所有SST做compaction。相邻文件大小比例
有一个参数size_ratio用于控制相邻文件大小比例的阈值。如果size(R2) / size(R1)的比值小于1 + size_ratio / 100,就表示R1和R2两个SST可以做compaction。接下来继续检查size(R3) / size(R1 + R2)是否小于1 + size_ratio / 100,若仍满足,就将R3也加入待compaction的SST里来。如此往复,直到不再满足上述比例条件为止。
当然,如果上述两个条件都没能触发compaction,该策略就会线性地从R1开始合并,直到L0层的文件数目小于level0_file_num_compaction_trigger阈值。
The End
还是写的很乱,但就这样吧。
困了。明天加班,民那晚安。