深度之眼Paper带读笔记NLP.Baseline.3.C2W
文章目录
- 前言
- 前期知识储备
- 论文总览
- 学习目标
- 第一课:论文导读
- 背景知识
- 词嵌入模型的问题
- 无推理能力
- 词表大小问题
- 研究成果及意义
- 研究成果
- 研究意义
- 第二课:论文精读
- 论文结构
- 摘要
- 论文章节
- C2W模型
- 词嵌入模型
- 字符嵌入模型
- C2W模型应用
- 实验结果及分析
- 语言模型训练方法:
- POS实验
- 论文总结
- 代码复现
- 项目环境配置
- 数据集
- 数据集处理
- C2W模型
前言
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
从字符中生成词嵌入:用于开放词表示的组合字符模型
题目中的function代表词语法和语义特征或称为词嵌入
开放意思是词表大小是不固定的,没有UNK单词,只要有新单词就可以加入到词表中。
作者:Wang Ling(第一作者)
单位:Carnegie Mellon University
会议:EMNLP2015
在线LaTeX公式编辑器
前期知识储备
机器学习:机器学习中基本的原理及概念,如数据集的划分,损失函数,优化方法等
神经网络:了解神经网络的基本知识,特别是循环神经网络(LSTM)的基本原理
词向量:了解词向量的概念,了解word2vec,了解语言模型训练词向量的方法
编程:了解PyTorch基本使用方法,如数据读取、模型构建,损失优化等
论文总览

学习目标
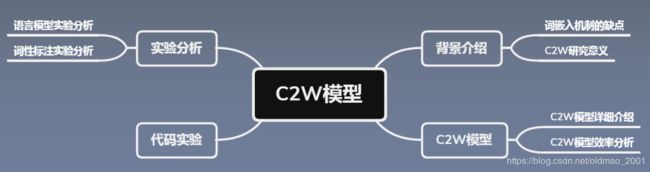
第一课:论文导读
背景知识
- 词向量的学习对于自然语言处理的应用非常重要,词向量可以在空间上捕获词之间的语法和语义(Function)相似性。
- 但是词向量机制中的词和词之间是独立的,这种独立性假设是有问题的,词之间形式上的相似性会一定程度造成功能的相似性(cat vs cats),尤其是在形态丰富的语言中。
- 但是这种形态和功能之间的关系有不是绝对的(不好学习到),为了学习这种关系,本文在字符嵌入上使用双向LSTM来捕捉这种关系。
- 本文的C2W模型能够很好地捕捉词之间的语法和语义相似度,并且在两个任务上取得最优的结果。
词嵌入模型的问题
无推理能力
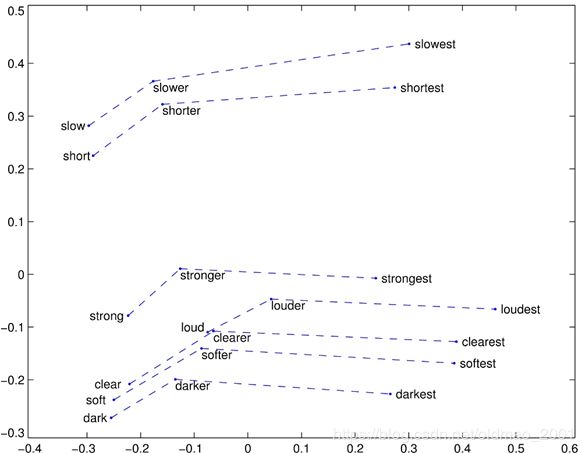
虽然模型可以学习到词与词之间的关系,例如上图中的原型,比较级,最高级。
但是如果给定一个单词great,是不能推出来他的比较级是greater的(如果词表中没有greater这个词就会是一个UNK),就是没有推理能力。
词表大小问题
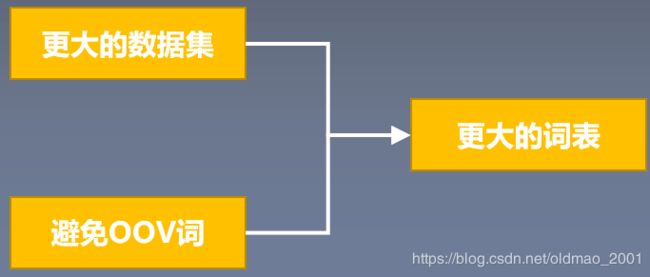
研究成果及意义
研究成果
在英语EN、葡萄牙语PT、加泰罗尼亚语CA、德语DE和土耳其语TR五种语言的语言模型上均取得最优结果。
从困惑度和参数个数上来看,结果都不错
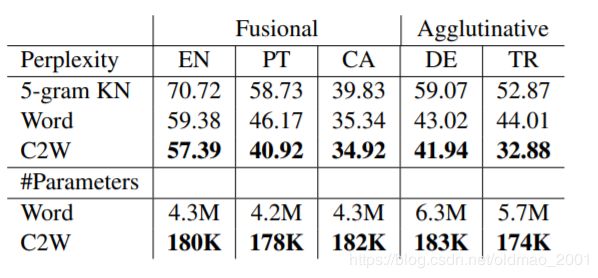
在英语的词性标注POS任务上取得最优STOA的结果。
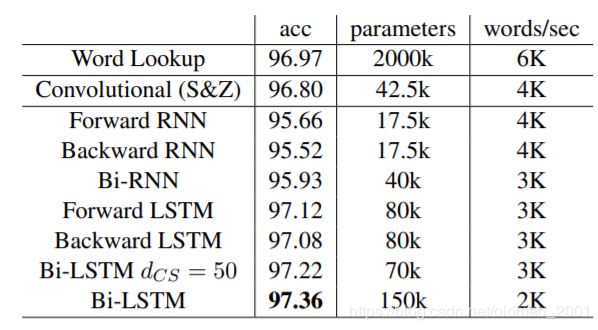
右边的速度显示这个模型速度比较慢。
研究意义
C2W历史意义
提供了一种新的训练词表示的方法,并且首次学习词内部的形式
第二课:论文精读
论文结构
摘要
- 我们提出了一种新的使用字符和双向LSTM生成词表示的模型。
We introduce a model for constructing vector representations of words by
composing characters using bidirectional LSTMs. - 相对于传统的词向量方法,我们的C2W模型需要的参数比较少,主要有两部分,一部分是字符映射成向量的参数,一部分是组合模块LSTM的参数。
Relative to traditional word representation models that have independent
vectors for each word type, our model requires only a single vector per character type and a fixed set of parameters for the compositional model. - 尽管我们的模型参数少,并且单词中的形式-功能关系很难学习,我们的模型在语言模型和词性标注任务上取得最优的结果。
Despite the compactness of this model and, more importantly, the arbitrary nature of the form–function relationship in language, our “composed” word representations yield state-of-the-art results in language modeling and part-of-speech tagging. - 这种优势在形态丰富的语言(土耳其语)中更加明显。
Benefits over traditional baselines are particularly pronounced in morphologically rich languages (e.g., Turkish).
论文章节
- Introduction
- Word Vectors and Wordless Word Vectors
2.1 Problem: Independent Parameters
2.2 Solution: Compositional Models - C2W Model
- Experiments: Language Modeling
4.1 Language Model
4.2 Experiments - Experiments: Part-of-speech Tagging
5.1 Bi-LSTM Tagging Model
4.2 Experiments
4.3 Discussion - Related Work
- Conclusion
这个文章的Related Work是放后面的,当Related Work对介绍后面的内容不影响可以放后面。
C2W模型
词嵌入模型
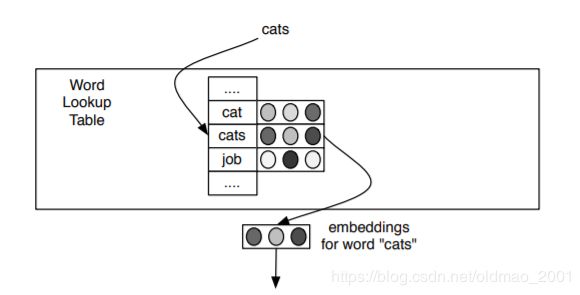
模型输入是词,输出是词向量
训练好后在Word Lookup Table里面可以直接查找词对应的词向量
字符嵌入模型
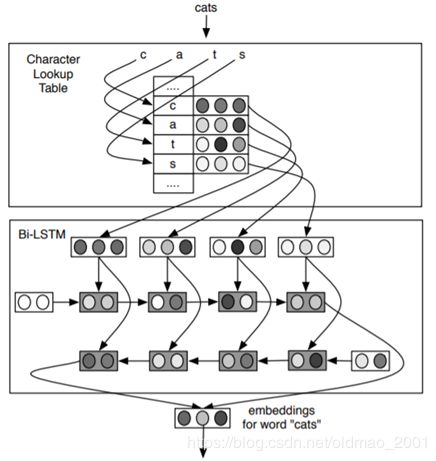
这里输入一个词,把每一个字符映射为向量(Character Lookup Table),例如上图中把c,a,t,s对应的四个向量丢到Bi-LSTM中(下半部分中第二排是正向LSTM【cats】,第三排是反向LSTM【stac】),然后把正向和反向的最后一个隐藏层的输出组合到一起得到单词cats的词向量。
缺点:
训练时还需要通过LSTM生成词表示,速度比词向量机制要慢。
测试时虽然可以通过缓存的方法预先生成一些词向量,但是对于OOV词的词表示生成依旧速度慢。
优点:
能够解决OOV词问题。
可以捕获字符间的结构信息。
可以推理出相似结构的词表示。
C2W模型应用
用于需要字符信息的任务,如序列标注、NER、POS
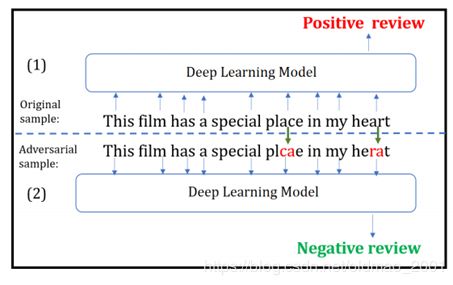
用于OOV词比较多的任务,如对抗样本,下图中的plcae和herat如果映射为UNK向量,那么整句话就很可能被识别为负面信息。
实验结果及分析
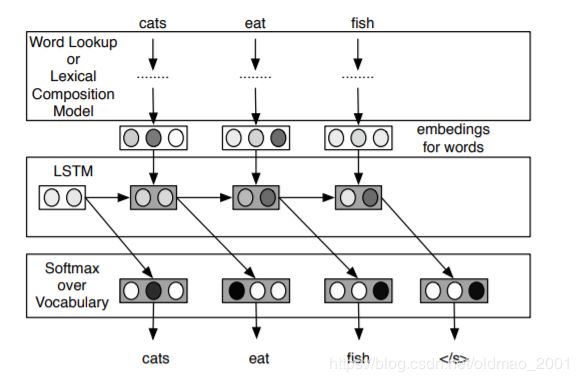
语言模型训练方法:
上面是论文C2W模型,得到词向量后通过LSTM进行预测。
基于上面的语言模型:
在英语EN、葡萄牙语PT、加泰罗尼亚语CA、德语DE和土耳其语TR五种语言的语言模型上均取得最优结果。
从困惑度和参数个数上来看,结果都不错。
这里补充一下,困惑度和单词数量的关系,当单词数量越大,词表就越大,每一个词分到的概率就变小(概率总和为1),困惑度变高。因此单词量小反而困惑度变小。
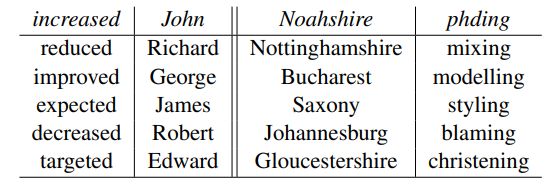
Table 2: Most-similar in-vocabular words under the C2W model; the two query words on the left are in the training vocabulary, those on the right are nonce (invented) words.
最右边两个词是作者自己发明的。
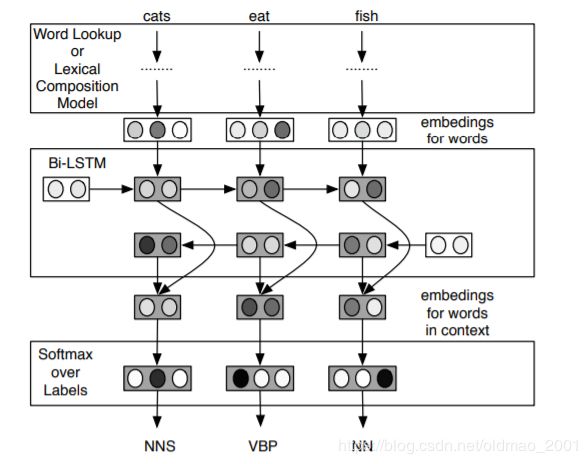
POS实验
词性标注模型,和上面的语言模型差不多
结果:
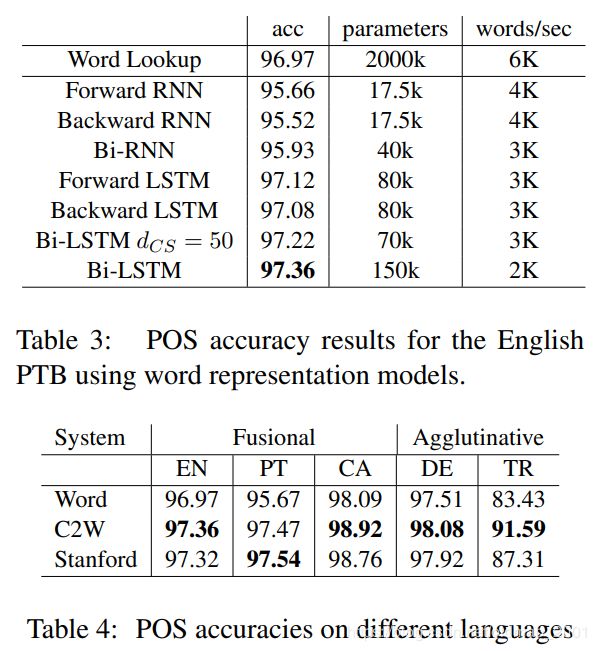
和词向量方法组合的词性标注实验
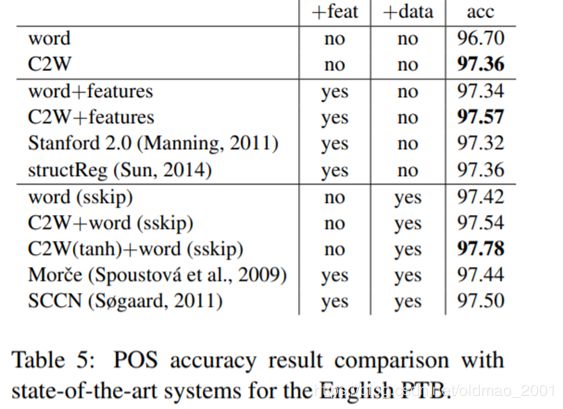
论文总结
关键点
词向量机制的两个问题:1.词与词之间是独立的cat和cats实际上应该不独立;2.词表太大,导致参数过多
如何学习单词中的形式-功能关系(双向LSTM)
C2W模型
创新点
提出了一种新的词表示方法—C2W
在语言模型任务和词性标注任务上取得非常好的结果
在形态丰富的语言中表现效果更好
启发点
这种词的独立性假设是存在本质问题的,尤其是在形态学丰富的语言中。在这种形态学丰富的语言中,更合理的假设是形态相似的词功能上(语法和语义)可能也相似。
This paper argues that this independence assumption is inherently problematic, in particular in morphologically rich languages (e.g., Turkish). In such languages, a more reasonable assumption would be that orthographic (formal) similarity is evidence for functional similarity (Introduction P1)
我们这篇工作的目的不是为了超越基准模型,而是为了说明基准模型中的特征工程可以从数据中自动学习出来。(都超过了才说的漂亮话)
The goal of our work is not to overcome existing benchmarks, but show that much of the feature engineering done in the benchmarks can be learnt automatically from the task specific data. (5.5 Discussion P1)
代码复现
项目环境配置
·Python3.5
·jupyter notebook
·torch 1.4.0
·numpy 1.16.2
·gensim 3.8.1
·tqdm 4.31.1
·pickler
·json
·nltk
·wikiextractor
数据集
同baseline 1
数据集可以选一个比较小的,注意要下article
wikiextractor:https://github.com/attardi/wikiextractor 这个东东处理的数据可以提取出完整的句子,带标点,而不是一个个的单词,用法如下:
python WikiExtractor.py -o output- b 1000M enwiki-latest-pages-articles14.xml-p7697595p7744800.bz2 --json
output是文件夹,1000M是大数据集在输出的时候可以进行切分为小文件的大小。
下图是处理后的结果:
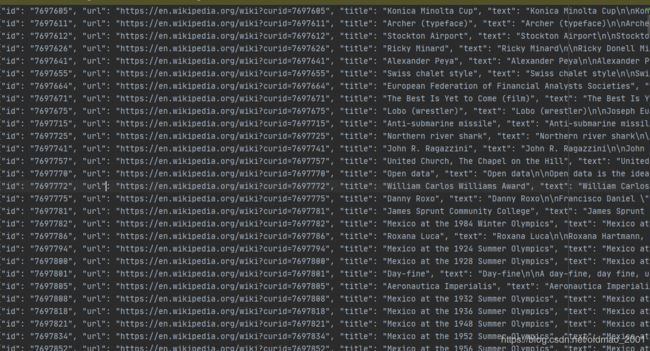
有的时候还有/n的换行符,这个是处理过的。
data = json.loads(data,strict=False)
sentences = data["text"]
sentences = sentences.replace("\n\n",". ")
sentences = sentences.replace("\n",". ")
另外一个要注意的就是nltk的安装,以上安装会比较慢,还会报错:
可以直接下载(https://pan.baidu.com/s/1hq7UUFU)后解压到:
c盘下user下的当前用户名的Roaming>nltk_data里面,
解压后:
打开tokenizers再解压得到punkt目录,和一堆文件,创建一个PY3文件夹,把文件放到PY3文件夹,否则会报错。(每个人环境貌似不一样,我的就不用创建,保险一点就是punkt和PY3都放一份)
数据集处理
data_processing
# -*- coding: utf-8 -*-
import json
import nltk
# ·数据集加载
# ·分句,分词以及划分数据集
# ·加载训练集
# ·构建word2id,char2id
# ·构建特征和标签
# ·生成torch数据导入类
datas = open("./wiki_00", encoding="utf-8").read().splitlines() # 按行进行切分
print(datas[0:5]) # 打印一部分数据看看,发现是很乱的
num_words = 0
f_train = open("train.txt", "w", encoding="utf-8")
f_valid = open("valid.txt", "w", encoding="utf-8")
f_test = open("test.txt", "w", encoding="utf-8")
for data in datas:
data = json.loads(data, strict=False)
# 这里的data包含的内容不单单有文本信息,还有文章的编号,标题,网址等信息,这些我们都不要,我们只关心'text'对应的内容
# 'id': '7719190', 'url': 'https://en.wikipedia.org/wiki?curid=7719190', 'title': 'List of Teletubbies episodes and videos', 'text': 'List of Teletubbies episodes and videos
# 用data["text"]来提取'text'对应的内容
sentences = data["text"]
# 替换掉\n\n替换为句号+空格
sentences = sentences.replace("\n\n", ". ")
sentences = sentences.replace("\n", ". ")
# 用sent_tokenize把句子进行切分
sentences = nltk.sent_tokenize(sentences)
for sentence in sentences:
# 用word_tokenize对每个句子中的单词进行切分,这里不用空格分是因为句子里面包含有标点符号
sentence = nltk.word_tokenize(sentence)
# 过滤标题和长句
if len(sentence) < 10 or len(sentence) > 100:
continue
num_words += len(sentence)
print(sentence)
# 一句话切为词后加回车换行
sentence = " ".join(sentence) + "\n"
# 前1000000个词作为训练集放到train.txt,接下来20000个词作为验证集放到valid.txt中,接下来20000个词作为测试集放到test.txt中
if num_words <= 1000000:
f_train.write(sentence)
elif num_words <= 1020000:
f_valid.write(sentence)
elif num_words <= 1040000:
f_test.write(sentence)
else:
exit()
data_load
# coding:utf-8
from torch.utils import data
import os
import numpy as np
import pickle
from collections import Counter
# 继承py的DataLoader进行处理,前面三个函数需要实现
class Char_LM_Dataset(data.DataLoader):
def __init__(self, mode="train", max_word_length=16, max_sentence_length=100):
self.path = os.path.abspath('.')
if "data" not in self.path:
self.path += "/data"
self.mode = mode
self.max_word_length = max_word_length
self.max_sentence_length = max_sentence_length
datas = self.read_file()
datas, char_datas, weights = self.generate_data_label(datas)
# 对datas和char_datas进行reshape
# 标签datas原来大小sample_number*MSL,整合为一维的
# 数据char_datas原来大小sample_number * MSL * MWL,因为LSTM对输入是有要求的:batchsize*MWL*embeddingsize
# LSTM的输出是二维(sample_number*MSL)*embeddingsize,然后再reshape为三维:sample_number*MSL*embeddingsize
# 所以这里char_datas要reshape为二维的:(sample_number * MSL) * MWL
self.datas = datas.reshape([-1])
self.char_datas = char_datas.reshape([-1, self.max_word_length])
self.weights = weights
print(self.datas.shape, self.char_datas.shape, weights.shape)
def __getitem__(self, index):
return self.char_datas[index], self.datas[index], self.weights[index]
def __len__(self):
return len(self.datas)
def read_file(self):
# 加载训练集
if self.mode == "train":
datas = open(self.path + "/train.txt", encoding="utf-8").read().strip("\n").splitlines()
# 读取train.txt后用空格将词分开
datas = [s.split() for s in datas]
if not os.path.exists(self.path + "/word2id"):
words = []
chars = []
for data in datas:
for word in data:
words.append(word.lower())
chars.extend(word)
# 构建word2id,char2id
# 由于词表包含和,所以要-2
words = dict(Counter(words).most_common(5000 - 2))
# 由于字表包含和和,所以要-3
chars = dict(Counter(chars).most_common(512 - 3))
print(chars)
# 除了保留的2个特殊符号,其他单词都设置id
word2id = {"" : 0, "" : 1}
for word in words:
word2id[word] = len(word2id)
# 除了保留的3个特殊符号,其他字符都设置id
char2id = {"" : 0, "" : 1, "" : 2}
for char in chars:
char2id[char] = len(char2id)
self.word2id = word2id
self.char2id = char2id
pickle.dump(self.word2id, open(self.path + "/word2id", "wb"))
pickle.dump(self.char2id, open(self.path + "/char2id", "wb"))
else:
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
self.char2id = pickle.load(open(self.path + "/char2id", "rb"))
return datas
elif self.mode == "valid":
datas = open(self.path + "/valid.txt", encoding="utf-8").read().strip("\n").splitlines()
datas = [s.split() for s in datas]
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
self.char2id = pickle.load(open(self.path + "/char2id", "rb"))
return datas
elif self.mode == "test":
datas = open(self.path + "/test.txt", encoding="utf-8").read().strip("\n").splitlines()
datas = [s.split() for s in datas]
self.word2id = pickle.load(open(self.path + "/word2id", "rb"))
self.char2id = pickle.load(open(self.path + "/char2id", "rb"))
return datas
# 构建特征和标签
# 由于句子和句子,单词和单词是不一样长度的,因此在构建它们的矩阵的时候是根据max_sentence_length(100)和max_word_length(16)来设计的
# 如果句子中的单词小于max_sentence_length,则用pad补齐
# 如果单词中的字符小于max_word_length,则用pad补齐
# 为了使得模型不对用于补齐的pad进行计算,每个句子和单词都配上一个weights,weights在pad的位置为0,否则为1,用于表示当前位置的东西是否要进行预测计算
# loss*weights即可避免pad的计算
def generate_data_label(self, datas):
char_datas = []
weights = []
for i, data in enumerate(datas):
if i % 1000 == 0: # 每1000个做一次输出
print(i, len(datas))
# 对应的id是2,下面得到的是:
# [[2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2]]
char_data = [[self.char2id["" ]] * self.max_word_length]
for j, word in enumerate(data):
char_word = []
# 将每个词映射为字符
for char in word:
# 如果能在字符表找到字符的id则设置id,否则设置为unk的id
char_word.append(self.char2id.get(char, self.char2id["" ]))
# 将短的单词的字符补齐到max_word_length长度,补的" ]] * (self.max_word_length - len(char_word))
# 如果能在单词表找到单词的id则设置id,否则设置为unk的id
datas[i][j] = self.word2id.get(datas[i][j].lower(), self.word2id["" ])
char_data.append(char_word)
weights.extend([1] * len(datas[i]) + [0] * (self.max_sentence_length - len(datas[i])))
# 句子按照max_sentence_length进行补" ]] * (
self.max_sentence_length - len(datas[i]))
char_datas.append(char_data)
# 字符表组合为词后也要按max_sentence_length进行补,每个词按max_word_length长度进行补。
char_datas[i] = char_datas[i][0:self.max_sentence_length] + \
[[self.char2id["" ]] * self.max_word_length] * (
self.max_sentence_length - len(char_datas[i]))
datas = np.array(datas) # 句子个数*max_sentence_length,即:sample_number*MSL
char_datas = np.array(char_datas) # 句子个数*max_sentence_length*max_word_length,即:sample_number*MSL*MWL
weights = np.array(weights)
return datas, char_datas, weights
if __name__ == "__main__":
char_lm_dataset = Char_LM_Dataset()
C2W模型
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import numpy as np
# 输入数据是二维的:(bs*MSL)*MWL,对输入进行char_embedding后,得到:(bs*MSL)*MWL*char_embedding_size,进入Bi-LSTM
# Bi-LSTM输出两部分,正向:(bs*MSL)*MWL*hidden_size,反向:(bs*MSL)*MWL*hidden_size
# PyTorch把正向和反向都concat到一起:(bs*MSL)*MWL*hidden_size*2
# 输入要设置batch_first=True,PyTorch才会认为第一个维度是batchsize,默认是false,这里要注意。
# 然后我们需要把正向的最后一个值(正向最后的输出)和反向的第一个值(反向最后的输出)拿出来进行concat。
# 然后把concat的结果进行FC,得到:(bs*MSL)*word_embedding_size二维结果
# reshape为三维的:bs*MSL*word_embedding_size
# 送进LSTM得到三维的:bs*MSL*LM_hidden_size
# Reshape为二维的:(bs*MSL)*LM_hidden_size
# 送进分类器得到:(bs*MSL)*词表大小
class C2W(nn.Module):
def __init__(self, config):
super(C2W, self).__init__()
self.char_hidden_size = config.char_hidden_size
self.word_embed_size = config.word_embed_size
self.lm_hidden_size = config.lm_hidden_size
self.character_embedding = nn.Embedding(config.n_chars, config.char_embed_size)
self.sentence_length = config.max_sentence_length
self.char_lstm = nn.LSTM(input_size=config.char_embed_size, hidden_size=config.char_hidden_size,
bidirectional=True, batch_first=True)
self.lm_lstm = nn.LSTM(input_size=self.word_embed_size, hidden_size=config.lm_hidden_size, batch_first=True)
self.fc_1 = nn.Linear(2 * config.char_hidden_size, config.word_embed_size)
self.fc_2 = nn.Linear(config.lm_hidden_size, config.vocab_size)
def forward(self, x):
# x是二维的:(bs*MSL)*MWL
# 对输入进行char_embedding后,得到:(bs*MSL)*MWL*char_embedding_size
input = self.character_embedding(x)
char_lstm_result = self.char_lstm(input)
# 需要把正向的最后一个值(正向最后的输出)和反向的第一个值(反向最后的输出)拿出来进行concat。
word_input = torch.cat([char_lstm_result[0][:, -1, 0:self.char_hidden_size],
char_lstm_result[0][:, 0, self.char_hidden_size:0]], dim=1)
print(word_input.shape)
# 把concat的结果进行FC,得到:(bs*MSL)*word_embedding_size二维结果
word_input = self.fc_1(word_input)
# reshape为三维的:bs*MSL*word_embedding_size
word_input = word_input.view([-1, self.sentence_length, self.word_embed_size])
# 送进LSTM得到三维的:bs*MSL*LM_hidden_size
lm_lstm_result = self.lm_lstm(word_input)[0].contiguous()
# Reshape为二维的:(bs*MSL)*LM_hidden_size
lm_lstm_result = lm_lstm_result.view([-1, self.lm_hidden_size])
# 送进分类器得到:(bs*MSL)*词表大小
out = self.fc_2(lm_lstm_result)
return out
class config:
def __init__(self):
self.n_chars = 64
self.char_embed_size = 50
self.max_sentence_length = 8
self.char_hidden_size = 50
self.lm_hidden_size = 150
self.word_embed_size = 50
config.vocab_size = 1000
if __name__ == "__main__":
config = config()
c2w = C2W(config)
test = torch.tensor(np.zeros([64, 16])).long()
c2w(test)