| 点击此处返回总目录 这节课讲解怎么在caffe中使用GoogleNet来实现图像的识别。 一、 到caffe的GitHub上去下载训练好的GoogleNet模型。 地址:https://github.com/BVLC/caffe models->bvlc_googlenet->点击下面的链接,下载。  提醒:不要半夜下载。可能是关闭的,半夜下不下来。 下载完后为: ,有51M。 ,有51M。 放到caffe-master\models\bvlc_googlenet文件夹下。 我们可以看一下GoogleNet的网络结构,使用绘图工具。比较恶心,就不粘上了。解释一下网络结构吧 //deploy.prototxt(不全,拿了一部分)
| name: "GoogleNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 224 dim: 224 } } //一个批次10张图片。彩色图片。
}
layer {
name: "conv1/7x7_s2"
type: "Convolution"
bottom: "data"
top: "conv1/7x7_s2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
pad: 3 #外面补3圈0
kernel_size: 7
stride: 2
weight_filler {
type: "xavier"
std: 0.1 #标准差。但是对于"xavier"算法来说没用。当type为其他类型时,比如高斯算法时有用。
}
bias_filler {
type: "constant" #常数。为0.2。如果不设置就是0
value: 0.2
}
}
}
layer {
name: "conv1/relu_7x7"
type: "ReLU"
bottom: "conv1/7x7_s2"
top: "conv1/7x7_s2"
}
layer {
name: "pool1/3x3_s2"
type: "Pooling"
bottom: "conv1/7x7_s2"
top: "pool1/3x3_s2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "pool1/norm1"
type: "LRN" #局部响应归一化。可以提高模型识别的准确率。
bottom: "pool1/3x3_s2"
top: "pool1/norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "inception_4a/pool_proj"
type: "Convolution"
bottom: "inception_4a/pool"
top: "inception_4a/pool_proj"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.1
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_4a/relu_pool_proj"
type: "ReLU"
bottom: "inception_4a/pool_proj"
top: "inception_4a/pool_proj"
}
layer {
name: "inception_4a/output"
type: "Concat" //表示合并数据的意思。把前面很多个分支的输出汇总。合并的条件是数据的后面三个参数一样
bottom: "inception_4a/1x1"
bottom: "inception_4a/3x3"
bottom: "inception_4a/5x5"
bottom: "inception_4a/pool_proj"
top: "inception_4a/output"
}
layer {
name: "inception_4b/1x1"
type: "Convolution"
bottom: "inception_4a/output"
top: "inception_4b/1x1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 160
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
name: "inception_5a/relu_5x5"
type: "ReLU"
bottom: "inception_5a/5x5"
top: "inception_5a/5x5"
}
layer {
name: "inception_5a/pool"
type: "Pooling"
bottom: "pool4/3x3_s2"
top: "inception_5a/pool"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
pad: 1
}
}
layer {
name: "loss3/classifier"
type: "InnerProduct"
bottom: "pool5/7x7_s1"
top: "loss3/classifier"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "loss3/classifier"
top: "prob"
} |
GoogleNet中有这样的结构,叫做Inception。池化层的输出给了三个卷积层,还有一个池化层。Inception中,这三个卷积层意味着三个不同大小的感受野,最后合并意味着不同尺度特征的融合。 采用1,3,5的卷积核大小,是因为使用步长为1,pad为0,1,2的方式采样后得到的特征平面大小相同。比如, 原图像大小为x*x。卷积核为1*1,pad = 0,得到图片:x*x 原图像x*x,卷积核3*3,pad = 1,得到图片(x+2)-3+1 =x ,还是x*x 原图片x*x,卷积核5*5,pad = 2,得到图片(x+4)-5+1 = x ,还是x*x 这样才能够合并。 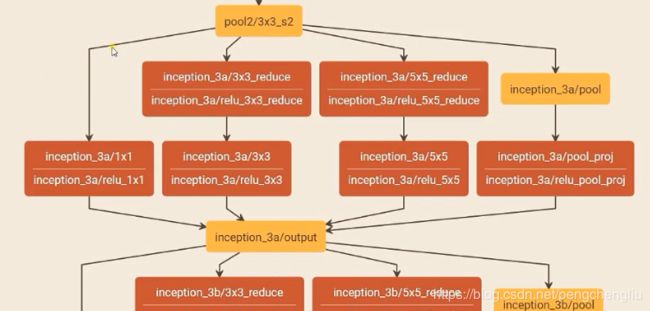
2. 准备要识别的图片 caffe-windows\models\bvlc_googlenet目录下新建文件夹image。 从网上随便下载了几张图片。 
3. 准备synset_words.txt文件 网上应该能搜到。前面是编号,后面是1000个物体的分类。 放到caffe-windows\models\bvlc_googlenet下。 
4. 运行程序,进行图像识别。 //
| # coding: utf-8 import caffe
import numpy as np
import matplotlib.pyplot as plt
import os
import PIL
from PIL import Image
import sys #定义Caffe根目录
caffe_root = 'F:/deep_learning/Caffe/caffe-windows/'
#网络结构描述文件
deploy_file = caffe_root+'models/bvlc_googlenet/deploy.prototxt'
#训练好的模型
model_file = caffe_root+'models/bvlc_googlenet/bvlc_googlenet.caffemodel' #cpu模式.因为只安装了CPU的版本,所以这句话没有也可以。
caffe.set_mode_cpu() #定义网络模型
net = caffe.Classifier(deploy_file, #调用deploy文件
model_file, #调用模型文件
mean=np.load(caffe_root +'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1), #调用均值文件
channel_swap=(2,1,0), #caffe中图片是BGR格式,而原始格式是RGB,所以要转化
raw_scale=255, #python中将图片存储为[0, 1],而caffe中将图片存储为[0, 255],所以需要一个转换
image_dims=(224, 224)) #输入模型的图片要是224*224的图片 #分类标签文件
imagenet_labels_filename = caffe_root +'models/bvlc_googlenet/synset_words.txt'
#载入分类标签文件
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') #对目标路径中的图像,遍历并分类
for root,dirs,files in os.walk(caffe_root+'models/bvlc_googlenet/image/'):
for file in files:
#加载要分类的图片
image_file = os.path.join(root,file)
input_image = caffe.io.load_image(image_file) #载入图片 #打印图片路径及名称
image_path = os.path.join(root,file)
print(image_path)
#显示图片
img=Image.open(image_path)
plt.imshow(img)
plt.axis('off')
plt.show()
#预测图片类别
prediction = net.predict([input_image]) #结果是1000个分类对应的概率值
print 'predicted class:',prediction[0].argmax() #最大的概率所在的位置 # 输出概率最大的前5个预测结果
top_k = prediction[0].argsort()[-5:][::-1] #对1000个概率进行排序。提取最后的5个值。最后再倒序。得到的是编号。
for node_id in top_k:
#获取分类名称
human_string = labels[node_id]
#获取该分类的置信度
score = prediction[0][node_id]
print('%s (score = %.5f)' % (human_string, score)) |
运行结果: D:\Anaconda3\envs\py2\lib\site-packages\skimage\io\_io.py:49: UserWarning: `as_grey` has been deprecated in favor of `as_gray`
warn('`as_grey` has been deprecated in favor of `as_gray`')
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/1.jpg  predicted class: 249
n02110063 malamute, malemute, Alaskan malamute (score = 0.56430)
n02109961 Eskimo dog, husky (score = 0.21304)
n02110185 Siberian husky (score = 0.20320)
n02091467 Norwegian elkhound, elkhound (score = 0.01089)
n02106662 German shepherd, German shepherd dog, German police dog, alsatian (score = 0.00340)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/2.jpg 
predicted class: 436
n02814533 beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon (score = 0.60606)
n02974003 car wheel (score = 0.24771)
n04285008 sports car, sport car (score = 0.07949)
n03770679 minivan (score = 0.01537)
n03100240 convertible (score = 0.01536)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/3.jpg 
predicted class: 660
n03776460 mobile home, manufactured home (score = 0.43408)
n02859443 boathouse (score = 0.12835)
n02793495 barn (score = 0.05500)
n04589890 window screen (score = 0.03707)
n04435653 tile roof (score = 0.03689)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/4.jpg 
predicted class: 296
n02134084 ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus (score = 0.98611)
n02120079 Arctic fox, white fox, Alopex lagopus (score = 0.01358)
n02114548 white wolf, Arctic wolf, Canis lupus tundrarum (score = 0.00020)
n02111889 Samoyed, Samoyede (score = 0.00006)
n02441942 weasel (score = 0.00002)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/5.jpg 
predicted class: 850
n04399382 teddy, teddy bear (score = 0.22030)
n02883205 bow tie, bow-tie, bowtie (score = 0.07489)
n04579432 whistle (score = 0.05284)
n02910353 buckle (score = 0.03879)
n04133789 sandal (score = 0.03587)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/6.jpg 
predicted class: 283
n02123394 Persian cat (score = 0.48360)
n02123045 tabby, tabby cat (score = 0.38249)
n02124075 Egyptian cat (score = 0.05283)
n02123159 tiger cat (score = 0.03804)
n02127052 lynx, catamount (score = 0.01692)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/7.jpg 
predicted class: 584
n03476684 hair slide (score = 0.16116)
n03954731 plane, carpenter's plane, woodworking plane (score = 0.15686)
n04133789 sandal (score = 0.04462)
n04517823 vacuum, vacuum cleaner (score = 0.03880)
n04372370 switch, electric switch, electrical switch (score = 0.03754)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/8.jpg 
predicted class: 283
n02123394 Persian cat (score = 0.82506)
n02112018 Pomeranian (score = 0.03154)
n03325584 feather boa, boa (score = 0.01828)
n02328150 Angora, Angora rabbit (score = 0.01628)
n02127052 lynx, catamount (score = 0.01535)
F:/deep_learning/Caffe/caffe-windows/models/bvlc_googlenet/image/9.jpg 
predicted class: 283
n02123394 Persian cat (score = 0.49727)
n02127052 lynx, catamount (score = 0.21929)
n02123045 tabby, tabby cat (score = 0.05281)
n02124075 Egyptian cat (score = 0.04727)
n03958227 plastic bag (score = 0.03218) |