k-近邻算法
原理
- k-近邻算法是一种简单的分类算法;
- 通过计算测试点与数据集点的距离,根据距离最小的前k个点的类别,来判断测试点的类别。该判断有些类似生活中的选举投票。
参考维基百科上kNN词条的图
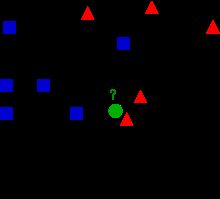
图中绿点周围有红色三角和蓝色方块,当K=3是,kNN算法将判定绿点为红色三角;当K=5时,kNN算法将判定绿点为蓝色方块
实现步骤(摘自书本 )
- 计算已知类别的数据点与测试点之间的距离;
- 按照距离递增排序;
- 选取与当前距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回频率最高的类别作为当前点的类别。
k近邻算法的实现(python)
def kNN(testSet, dataSet, labels, k):
# 计算欧拉距离
dataSetSize = dataSet.shape[0]
diffMat = tile(testSet, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
# 查找最近K个点的类别
classCount = {}
for i in range(k):
votelabel = labels[sortedDistIndicies[i]]
classCount [votelabel] = classCount.get(votelabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),\
key = operator.itemgetter(1), reverse = True)
# 返回应属类别
return sortedClassCount[0][0]
- 需要说明的地方:
argsort()的返回值为距离排序后的大小序号,比如:
distances = np.array([1.2, 0.5, 4.2, 3.7])
print np.argsort(distances) # [1 0 3 2]
- 在查找最近k个点的类别过程中,累计每个邻近点的类别出现的次数,返回频率最高的类别作为当前点的类别
- K的取值不一样,导致的结果也将不太一样
实例
测试集来自
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Original%29
样例:
1000025,5,1,1,1,2,1,3,1,1,2
1002945,5,4,4,5,7,10,3,2,1,2
特征含义:

除了id,其余9维特征可以作为我们的特征向量,而最后的预测结果为: 2(良性),4(恶性)
由于元数据含有缺失值,如:(1057013,8,4,5,1,2,?,7,3,1,4 )
可以考虑将这部分样例删去
实例代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from numpy import *
import operator
import pandas as pd
import random
def getMat():
fr = open('breast-cancer-wisconsin.data')
lines = fr.readlines()
raw_lines = lines
# 删除含有缺失值的样本
for line in lines:
if line.find('?') != -1:
raw_lines.remove(line)
numberOfline = len(raw_lines)
returnMat = zeros((numberOfline, 10))
index = 0
for line in raw_lines:
line = line.strip().split(',')
line1 = [int(x) for x in line]
returnMat[index:] = line1[1:]
index += 1
return returnMat
def kNN(testSet, dataSet, labels, k):
# 计算欧拉距离
dataSetSize = dataSet.shape[0]
diffMat = tile(testSet, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
# 查找最近K个点的类别
classCount = {}
for i in range(k):
votelabel = labels[sortedDistIndicies[i]]
classCount [votelabel] = classCount.get(votelabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),\
key = operator.itemgetter(1), reverse = True)
# 返回应属类别
return sortedClassCount[0][0]
if __name__ == '__main__':
dataMat = getMat()
ratio = 0.2 # 样本中20%的数据用于测试
numberTest = int(0.2 * len(dataMat))
random.shuffle(dataMat) # 将样本随机化
dataTrain = dataMat[numberTest:len(dataMat), 0:-1]
dataTrainLabel = dataMat[numberTest:len(dataMat), -1]
dataTest = dataMat[0:numberTest, 0:-1]
dataTestLabel = dataMat[0:numberTest, -1]
errorNum = 0
for i in range(numberTest):
testResult = kNN(dataTest[i,:], dataTrain, dataTrainLabel, 7)
print "came back: %d, the true answer is: %d" % (testResult, dataTestLabel[i])
if (testResult != dataTestLabel[i]):
errorNum += 1
print "error rate is: %f" % (errorNum/float(numberTest))
print errorNum, numberTest
运行结果如下:

结果分析
可以看出kNN算法准确性比较高
但是计算量大,需要计算大量的点距离,当样本特征较多时(1000+),运行效率较低,因此不太适合大数据运算
参考:
- https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- http://blog.topspeedsnail.com/archives/10287