语义分割之ENet
论文:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
代码:https://github.com/TimoSaemann/ENet
论文提出了新的语义分割模型ENet (efficient neural network),相比SegNet,速度提升18倍,计算量减少75倍,参数量减少79倍。并且具有相当的精度,是一个实时的语义分割网络结构。

网络结构:

ENet的输入图像大小为512*512*3,输出图像大小为512*512
- 表示最开始的网络模块,分别使用stride=2的3*3卷积和max pooling进行下采样。卷积输出通道数为13,maxpooling输出通道数为3,concat后为16。
2.ENet的瓶颈单元
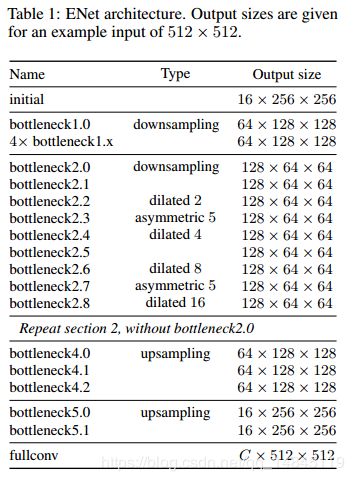
网络结构先做下采样(编码),再做上采用(解码),编码部分的层数大于解码部分。
设计选择:
Feature map resolution:
(1)减少特征图分辨率会引起空间信息的损失,像准确的边界形状。
(2)全像素分割需要输入和输出具有相同的分辨率。
(3)过强的下采样会影响准确性。
Early downsampling:
早期处理高分辨率的输入会耗费大量计算资源,ENet的初始化模型会大大减少输入的大小。这是考虑到视觉信息在空间上是高度冗余的,可以压缩成更有效的表示方式。
Decoder size:
ENet由一个大的编码模块和一个小的解码模块组合成。
Nonlinear operations:
去除初始几层的大部分RELU操作,可以提高网络的准确性。
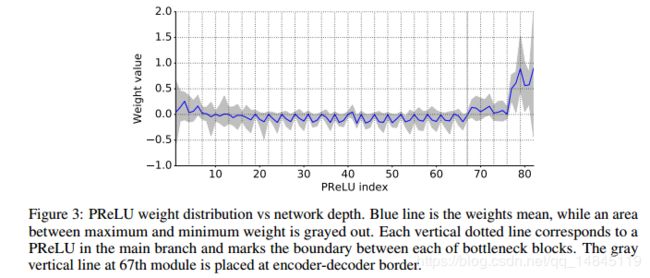
Information-preserving dimensionality changes:
在Initial Block,将Pooling操作和卷积操作并行,再concat到一起,这将inference阶段时间加速了10倍。同时在做下采样时,原来ResNet的卷积层分支会使用stride=2的1*1卷积,这会丢失大量的输入数据。ENet改为2×2的卷积核,有效的改善了信息的流动和准确率。
Factorizing filters:
将n×n的卷积核拆为n×1和1×n的卷积核,可以有效的减少参数量和计算量。
Dilated convolutions:
使用膨胀卷积可以增大模型的感受野,提高4%的IOU准确性。
Regularization:
在模型的卷积层后面使用Spatial Dropout,可以获得比stochastic depth和L2 weight decay更好的效果。
实验结果:
速度:

模型大小:

准确性:

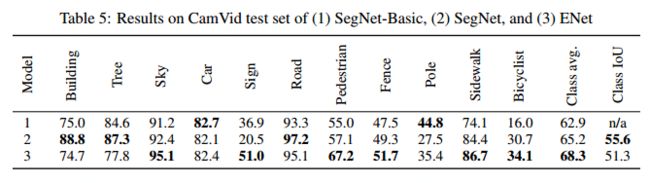

在Cityscapes和CamVid数据集上,ENet效果都好于SegNet。在SUN RGB-D数据集上,ENet效果比SegNet效果要差。
labelme标注数据转化:
# -*- coding: UTF-8 -*-
import numpy as np
import cv2
import math
import os
import json
import matplotlib.pyplot as plt
import shutil
def points2cont(point_lists):
new_cnts = []
for point_list in point_lists:
cont = np.array(point_list, dtype=np.int32)
cont = cont.reshape((-1, 1, 2))
new_cnts.append(cont)
return new_cnts
def creat_mask(cnts,size=(3024, 4032)):
mask = np.zeros(size, dtype=np.uint8)
# cnt = points2cont(cnt)
i=1
for cnt in cnts:
cv2.drawContours(mask, cnt, -1, [i], -1)
i+=1
# plt.imshow(mask)
# plt.show()
return mask
def load_point_list(json_file):
jsons = json.load(open(json_file,'r'))
point_lists = []
for plist in jsons['shapes']:
point_lists.append(plist)
return point_lists
def select_one_class_cnt(point_lists,label):
max_cnt = []
max_size = 0
max_label = 0
plists = []
for p in point_lists:
point_list = p['points']
if p['label'] == label:
plists.append(point_list)
if len(plists) > 0:
cnts = points2cont(plists)
return cnts
else:
return []
def visual_contour(img,cnts):
imshow_img = img.copy()
cv2.drawContours(imshow_img, cnts, -1, [0,0,255], 2)
return imshow_img
def main(imgs_dir,labels_dir,masks_dir,labels):
files = os.listdir(imgs_dir)
for file in files:
if '.jpg' in file:
prefix = '.jpg'
elif '.JPG' in file:
prefix = '.JPG'
else:
prefix = '.png'
# print file
img_file = os.path.join(imgs_dir,file)
print (img_file)
img = cv2.imread(img_file,2)
h,w = img.shape
json_file = os.path.join(labels_dir,file.replace('.JPG','.json'))
if not os.path.exists(json_file):
print (json_file," not exist")
continue
point_list = load_point_list(json_file)
cnts = []
for i in range(len(labels)):
cnts.append(select_one_class_cnt(point_list,labels[i]))
if len(cnts)==0:
print(0)
continue
mask = creat_mask(cnts, (h,w))
depth_file = file[:-4]+'.png'
color_ff = file[:-4]+'.jpg'
cv2.imwrite(os.path.join(masks_dir,depth_file),mask,[cv2.IMWRITE_PNG_COMPRESSION,0])
if __name__ == '__main__':
imgs_dir = r"jpg"#原图路径
labels_dir = r"seg_json"#labelme标注的json路径
masks_dir = r"object_mask"#生成的mask路径
labels = ["1","2","3"]#label名称
main(imgs_dir,labels_dir,masks_dir,labels)
ncnn支持:
ncnn不支持Upsample操作,所以需要将网络中的Upsample操作替换为deconv操作,
layer {
name: "upsample4_0_4"
type: "Upsample"
bottom: "bn4_0_4"
bottom: "pool2_0_4_mask"
top: "upsample4_0_4"
upsample_param {
scale: 2
}
}
layer {
name: "upsample5_0_4"
type: "Upsample"
bottom: "bn5_0_4"
bottom: "pool1_0_4_mask"
top: "upsample5_0_4"
upsample_param {
scale: 2
}
}替换为,
layer {
name: "upsample4_0_4"
type: "Deconvolution"
bottom: "bn4_0_4"
top: "upsample4_0_4"
convolution_param {
num_output: 64
bias_term: true
kernel_size: 2
stride: 2
}
}
layer {
name: "upsample5_0_4"
type: "Deconvolution"
bottom: "bn5_0_4"
top: "upsample5_0_4"
convolution_param {
num_output: 29
bias_term: true
kernel_size: 2
stride: 2
}
}
双loss同时训练:
再原始loss
layer {
name: "deconv6_0_0"
type: "Deconvolution"
bottom: "prelu5_1_4"
top: "deconv6_0_0"
convolution_param {
num_output: 4
bias_term: true
kernel_size: 2
stride: 2
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "deconv6_0_0"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255
weight_by_label_freqs: false
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "deconv6_0_0"
bottom: "label"
top: "accuracy"
top: "per_class_accuracy"
}
的基础上增加,
###########loss 2
layer {
name: "upsample_encoder6_0_0_"
type: "Deconvolution"
bottom: "prelu3_8_4"
top: "upsample_encoder6_0_0_"
convolution_param {
num_output: 4
bias_term: true
kernel_size: 8
stride: 8
}
}
layer {
name: "loss_conv"
type: "SoftmaxWithLoss"
bottom: "upsample_encoder6_0_0_"
bottom: "label"
top: "loss_conv"
loss_param {
ignore_label: 255
weight_by_label_freqs: false
}
}
layer {
name: "accuracy_conv"
type: "Accuracy"
bottom: "upsample_encoder6_0_0_"
bottom: "label"
top: "accuracy_conv"
top: "per_class_accuracy_conv"
}
加权的softmax,类似focal loss,
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "deconv6_0_0_"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255
weight_by_label_freqs: true
class_weighting: 0.5
class_weighting: 2.5
class_weighting: 2.0
class_weighting: 2.0
class_weighting: 2.0
class_weighting: 2.0
class_weighting: 2.0
}
}
数据增强:
enet代码中drop层写的很好,可以当作数据增强,而其余的传统数据增强却没实现,先做数据增强,可以提升一定的精度,
#https://github.com/aleju/imgaug
#pip install imgaug#coding=utf-8
import cv2
import numpy as np
import math
import random
from PIL import Image, ImageEnhance, ImageOps, ImageFile
import os
import glob
import argparse
import sys
import xml.etree.ElementTree as ET
import imgaug.augmenters as iaa
# imgpath = sys.argv[1]
# annopath = sys.argv[2]
imgpath = "./image"
annopath = "./mask"
destimgpath = imgpath + "_aug"
destannopath = annopath + "_aug"
os.system("del %s"% destimgpath)
os.system("del %s"% destannopath)
if not os.path.exists(destimgpath):
os.mkdir(destimgpath)
if not os.path.exists(destannopath):
os.mkdir(destannopath)
def ShadowExtension(src, degree):
h, w, _ = src.shape
temp = src[:, 0:int(degree*w)]
a = temp * 0.8
b = a.astype(np.uint8)
src[:, 0:int(degree * w)] = b
out = src
return out
def EqExtension(src):
I_backup = src.copy()
b, g, r = cv2.split(I_backup)
b = cv2.equalizeHist(b)
g = cv2.equalizeHist(g)
r = cv2.equalizeHist(r)
I_eq = cv2.merge([b, g, r])
return I_eq
def HueExtension(src):
img_hsv = cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
cre = random.randint(90, 100)
cre = float(cre) / 100
img_hsv[:,:,2] = img_hsv[:,:,2] * cre
# print(img_hsv[:,:,0])
dst = cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR)
return dst
def flip_img(img,scale=1.0,direction=0):
img_flip = cv2.flip(img,direction)
l = img.shape
img_flip = cv2.resize(img_flip,(int(l[1]*scale),int(l[0]*scale)))
return img_flip
def flip_box(src,originbox,scale=1.0,direction=0): #todo
l = src.shape
boxnum = int(len(originbox)/4)
resultbox = []
if direction == 1:
for i in range(boxnum):
flip_rec = [l[1]-originbox[2+4*i],originbox[1 + 4*i],l[1]-originbox[0 + 4*i],originbox[3 + 4*i]]
resultbox.extend(flip_rec)
# flip_rec = [l[1]-originbox[2],originbox[1],l[1]-originbox[0],originbox[3]]
if direction == 0:
for i in range(boxnum):
flip_rec = [originbox[0 + 4*i],l[0] - originbox[3 + 4*i],originbox[2 + 4*i],l[0] - originbox[1 + 4*i]]
resultbox.extend(flip_rec)
# flip_rec = [originbox[0],l[0] - originbox[3],originbox[2],l[0] - originbox[1]]
resultbox = [int(i*scale) for i in resultbox]
return resultbox
def rotate_image(img, angle, scale=1.):
w = img.shape[1]
h = img.shape[0]
# 角度变弧度
rangle = np.deg2rad(angle) # angle in radians
# now calculate new image width and height
nw = (abs(np.sin(rangle)*h) + abs(np.cos(rangle)*w))*scale
nh = (abs(np.cos(rangle)*h) + abs(np.sin(rangle)*w))*scale
# ask OpenCV for the rotation matrix
rot_mat = cv2.getRotationMatrix2D((nw*0.5, nh*0.5), angle, scale)
# calculate the move from the old center to the new center combined
# with the rotation
rot_move = np.dot(rot_mat, np.array([(nw-w)*0.5, (nh-h)*0.5,0]))
# the move only affects the translation, so update the translation
# part of the transform
rot_mat[0,2] += rot_move[0]
rot_mat[1,2] += rot_move[1]
# 仿射变换
return cv2.warpAffine(img, rot_mat, (int(math.ceil(nw)), int(math.ceil(nh))), flags=cv2.INTER_LANCZOS4)
def randomGaussianBlur(img):
"""
对图像进行高斯滤波,使图像变得模糊
:param image:
:return:
"""
kernal_size_list = [5, 7, 9] # [3, 5, 7, 9, 10]
kernal_size = random.choice(kernal_size_list)
sigmaX = random.choice(range(1, 8, 2)) #range(10, 130, 15)
sigma = sigmaX
#sigma = sigmaX * 1.0 / 10 # 100
# print kernal_size
# print sigma
#img = np.asarray(img)
img_gau = cv2.GaussianBlur(img, (kernal_size, kernal_size), sigma)
# return img
return img_gau
def randomColor(image):
"""
对图像进行颜色抖动
:param image: PIL的图像image
:return: 有颜色色差的图像image
"""
c = random.randint(0,3)
# c = 3
random_factor = np.random.randint(0, 50) / 10. # 随机因子
color_image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
if c == 0:
return color_image
random_factor = np.random.randint(8, 14) / 10. # 随机因子
brightness_image = ImageEnhance.Brightness(color_image).enhance(random_factor) # 调整图像的亮度
if c == 1:
return brightness_image
# #
random_factor = np.random.randint(10, 15) / 10. # 随机因子
contrast_image = ImageEnhance.Contrast(brightness_image).enhance(random_factor) # 调整图像对比度
if c == 2:
return contrast_image
random_factor = np.random.randint(0, 30) / 10. # 随机因子
return ImageEnhance.Sharpness(contrast_image).enhance(random_factor) # 调整图像锐度
# 随机生成5000个椒盐噪声
def zaodian(img):
height,weight,channel = img.shape
img_zao = img.copy()
for i in range(5000):
x = np.random.randint(0,height)
y = np.random.randint(0,weight)
img_zao[x ,y ,:] = 255
return img_zao
def translate(img,w,h):
rows,cols,channel = img.shape
M = np.float32([[1,0,w],[0,1,h]])
img_ping = cv2.warpAffine(img,M,(cols,rows))
return img_ping
def rhgan(ganimg,srcimg):
h,w,_ = ganimg.shape
maxh = srcimg.shape[0] - h -1
maxw = srcimg.shape[1] - w -1
if maxh <0 or maxw < 0:
return srcimg
y = random.randint(0,maxh)
x = random.randint(0,maxw)
roiimg = srcimg[y:y + h,x:x+w,:]
mask = np.ones(ganimg.shape, ganimg.dtype) * 255
cv2.copyTo(ganimg, mask, roiimg)
return srcimg
def superpixelsaug(img):
images = np.expand_dims(img, axis=0)
aug = iaa.Superpixels(p_replace=0.005,max_size=50)
images_aug = aug(images=images)
img_aug = np.squeeze(images_aug)
return img_aug
def fogaug(img):
images = np.expand_dims(img, axis=0)
aug = iaa.Fog()
images_aug = aug(images=images)
img_aug = np.squeeze(images_aug)
return img_aug
def cloudsaug(img):
images = np.expand_dims(img, axis=0)
aug = iaa.Clouds()
images_aug = aug(images=images)
img_aug = np.squeeze(images_aug)
return img_aug
def fnaug(img):
images = np.expand_dims(img, axis=0)
aug = iaa.FrequencyNoiseAlpha(first=iaa.EdgeDetect(0.5))
images_aug = aug(images=images)
img_aug = np.squeeze(images_aug)
return img_aug
def Coarseaug(img):
images = np.expand_dims(img, axis=0)
aug = iaa.CoarseDropout(0.02, size_percent=0.5)
images_aug = aug(images=images)
img_aug = np.squeeze(images_aug)
return img_aug
def copyxml(srcannofile,destannofile):
os.system("copy %s %s"%(srcannofile,destannofile))
return 0
if __name__ == '__main__':
imgfiles = os.listdir(imgpath)
print (imgfiles)
annofiles = os.listdir(annopath)
for img_name in imgfiles:
img = cv2.imread(imgpath + "/" + img_name)
if img is None:
continue
xmlname = img_name.replace(".png", "_mask.png")
srcannofile = os.path.join(annopath ,xmlname)
lableimg = cv2.imread(srcannofile)
if lableimg is None:
continue
rand_scale = random.randint(1, 3)
# direction = random.randint(0,1)
direction = 1
img_flip = flip_img(img, 1.0 / rand_scale,direction=direction)
label_flip = flip_img(lableimg,1.0/rand_scale,direction=direction)
flip_imgname = img_name.rstrip('.jpg').rstrip(".png") + '_flip' + '.jpg'
flip_labelname = flip_imgname.rstrip("jpg") + "png"
destannofile = destannopath + "/" + flip_labelname
cv2.imwrite(destimgpath + "/" + flip_imgname, img_flip)
cv2.imwrite(destannofile,label_flip)
range_num = random.randint(1, 20)
# range_num = 10
for i in range(range_num):
rand_num = random.randint(0, 16)
# rand_num = 8
if rand_num == 0 or rand_num == 13 or rand_num == 14 or rand_num == 15 :
rand_scale = random.randint(1, 3)
rand_angle = random.randint(0, 3)
angles = [5, 3, 358, 355]
img_rot = rotate_image(img, angles[rand_angle], 1.0 / rand_scale)
label_rot = rotate_image(lableimg, angles[rand_angle], 1.0 / rand_scale)
rot_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_rot%s' % i + '.jpg'
rot_labelname = rot_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + rot_labelname
cv2.imwrite(destimgpath + "/" + rot_imgname, img_rot)
cv2.imwrite(destannofile, label_rot)
elif rand_num == 1 :
img_gau = randomGaussianBlur(img)
gau_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_gau%s' % i + '.jpg'
gau_xmlname = gau_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + gau_xmlname
cv2.imwrite(destimgpath + "/" + gau_imgname, img_gau)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 2:
img_zao = zaodian(img)
zao_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_zao%s' % i + '.jpg'
zao_xmlname = zao_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + zao_xmlname
cv2.imwrite(destimgpath + "/" + zao_imgname, img_zao)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 3:
ch = [5, 10, 15, 20]
cw = [5, 10, 15, 20]
w = random.choice(cw)
h = random.choice(ch)
img_ping = translate(img, w, h)
label_ping = translate(lableimg,w,h)
# ping_rec = [rectangle[0] + w, rectangle[1] + h, rectangle[2] + w, rectangle[3] + h]
ping_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_ping%s' % i + '.jpg'
ping_xmlname = ping_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + ping_xmlname
cv2.imwrite(destimgpath + "/" + ping_imgname, img_ping)
cv2.imwrite(destannofile, label_ping)
elif rand_num == 4 or rand_num == 7:
img_c = Image.open(imgpath + '/' + img_name, mode="r")
img_color = randomColor(img_c)
img_color = cv2.cvtColor(np.asarray(img_color), cv2.COLOR_RGB2BGR)
color_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_color%s' % i + '.jpg'
color_xmlname = color_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + color_xmlname
cv2.imwrite(destimgpath + "/" + color_imgname, img_color)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 5:
img_eq = EqExtension(img)
eq_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_eq%s' % i + '.jpg'
eq_xmlname = eq_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + eq_xmlname
cv2.imwrite(destimgpath + "/" + eq_imgname, img_eq)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 6:
img_hue = HueExtension(img)
hue_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_hue%s' % i + '.jpg'
hue_xmlname = hue_imgname.rstrip('jpg') + 'png'
destannofile = destannopath + "/" + hue_xmlname
cv2.imwrite(destimgpath + "/" + hue_imgname, img_hue)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 111:
ganpath = "./gan/"
ganfiles = os.listdir(ganpath)
ganlen = len(ganfiles)
gan_num = random.randint(0,ganlen-1)
ganimg = cv2.imread(ganpath + ganfiles[gan_num])
img_gan = rhgan(ganimg, img)
gan_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_gan%s' % i + '.jpg'
gan_xmlname = gan_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath , gan_xmlname)
cv2.imwrite(destimgpath + "/" + gan_imgname, img_gan)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 111:
img_sup = superpixelsaug(img)
sup_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_sup%s' % i + '.jpg'
sup_xmlname = sup_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, sup_xmlname)
cv2.imwrite(destimgpath + "/" + sup_imgname, img_sup)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 9 or rand_num == 8:
img_fog = fogaug(img)
fog_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_fog%s' % i + '.jpg'
fog_xmlname = fog_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, fog_xmlname)
cv2.imwrite(destimgpath + "/" + fog_imgname, img_fog)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 10:
img_cloud = cloudsaug(img)
cloud_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_cloud%s' % i + '.jpg'
cloud_xmlname = cloud_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, cloud_xmlname)
cv2.imwrite(destimgpath + "/" + cloud_imgname, img_cloud)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 11:
img_fn = fnaug(img)
fn_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_fn%s' % i + '.jpg'
fn_xmlname = fn_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, fn_xmlname)
cv2.imwrite(destimgpath + "/" + fn_imgname, img_fn)
cv2.imwrite(destannofile, lableimg)
elif rand_num == 12:
img_coarse = Coarseaug(img)
coarse_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_coarse%s' % i + '.jpg'
coarse_xmlname = coarse_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, coarse_xmlname)
cv2.imwrite(destimgpath + "/" + coarse_imgname, img_coarse)
cv2.imwrite(destannofile, lableimg)
elif range_num == 16:
degree = random.randint(20, 100)
degree = degree / 100.0
img_shadow = ShadowExtension(img,degree)
shadow_imgname = img_name.rstrip('.jpg').rstrip('.png') + '_shadow%s' % i + '.jpg'
shadow_xmlname = shadow_imgname.rstrip('jpg') + 'png'
destannofile = os.path.join(destannopath, shadow_xmlname)
cv2.imwrite(destimgpath + "/" + shadow_imgname, img_shadow)
cv2.imwrite(destannofile, lableimg)
总结:
ENet,一个快速实时的语义分割模型结构。