TensorFlow剪枝API开发教程
Tensorflow在今年推出剪枝API,可用于对模型剪枝,使模型的大小可以得到压缩,速度得到提升。具体的参考文档为以下两篇:
第一篇,tensorflow推出的weixin推文:
https://mp.weixin.qq.com/s?__biz=MzU1OTMyNDcxMQ==&mid=2247485959&idx=1&sn=8d27c110d1ff857df986820c8923119b&chksm=fc18414fcb6fc859f4c03c9152b3b207308f908b0e757cd7cb6d149c8d366ebb6d967fa4ca96#rd
第二篇,tensorflow对应接口的使用说明:
https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras
先注意以下几点:
(1)当前API只支持keras,且是tensorflow的keras,而非原生的keras。
(2)当前只支持Sequential模型。
原理:
剪枝原理较为简单,简单理解,即在训练过程中,在迭代一定次数后,便对net中的接近0的权重,都置为0,已达到对模型剪枝的作用,以此反复,直到net的参数达到目标的稀疏度。这样,模型训练完成后,模型里面大多数的weight皆为0,那么,当我们使用zip进行压缩时,模型便可以得到很大程度的压缩,且在推断过程中,减少了很多的计算量。
1 .package安装:
pip install tensorflow
pip install tensorflow-model-optimization
2.构建pruned_model
分为两种方式,第一种是直接构建pruned_model,另外一种是将Sequential_keras模型转换成pruned_model模型,分别介绍:
(1):Build a pruned model layer by layer:
from tensorflow_model_optimization.sparsity import keras as sparsity
pruning_params = {
'pruning_schedule': sparsity.PolynomialDecay(initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=2000,
end_step=end_step,
frequency=100)
}
l = tf.keras.layers
pruned_model = tf.keras.Sequential([
sparsity.prune_low_magnitude(
l.Conv2D(32, 5, padding='same', activation='relu'),
input_shape=input_shape,
**pruning_params),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.BatchNormalization(),
sparsity.prune_low_magnitude(
l.Conv2D(64, 5, padding='same', activation='relu'), **pruning_params),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.Flatten(),
sparsity.prune_low_magnitude(l.Dense(1024, activation='relu'),
**pruning_params),
l.Dropout(0.4),
sparsity.prune_low_magnitude(l.Dense(num_classes, activation='softmax'),
**pruning_params)
])
pruned_model.summary()
(2):Prune a whole model:
###先构建Sequential_keras模型
def buildNet():
l = tf.keras.layers
model = tf.keras.Sequential([
l.Conv2D( 32, 5, padding='same', activation='relu', input_shape=[224,224,3]),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.BatchNormalization(),
l.SeparableConv2D(64, 5, padding='same', activation='relu'),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.BatchNormalization(),
l.SeparableConv2D(32, 5, padding='same', activation='relu'),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.BatchNormalization(),
l.SeparableConv2D(32, 5, padding='same', activation='relu'),
l.MaxPooling2D((2, 2), (2, 2), padding='same'),
l.GlobalAveragePooling2D(),
l.Dense(32, activation='relu'),
l.Dropout(0.4),
l.Dense(2, activation='softmax') ])
return model
model = buildNet()
###载入weight
model.load_weights('keras_model_weights.h5')
###将keras各个layer转换成pruned_layer
'''
###可将整个keras_model直接转换成pruned_layer
new_pruning_params = {
'pruning_schedule': sparsity.PolynomialDecay(initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=0,
end_step=end_step,
frequency=100)
}
new_pruned_model = sparsity.prune_low_magnitude(model, **new_pruning_params)
new_pruned_model.summary()
'''
###但当存在不支持转换的layer,将会报错,那么我们必须一个layer一个layer进行转换
pruning_schedule = sparsity.PolynomialDecay(
initial_sparsity=0.50,
final_sparsity=0.90,
begin_step=0,
end_step=end_step,
frequency=100)
pruned_model = tf.keras.Sequential()
for layer in model.layers:
layerName = layer.name
if('conv2d' in layerName):
print ('conv')
print (layerName)
pruned_model.add(sparsity.prune_low_magnitude(
layer,
pruning_schedule
))
elif('dense' in layerName):
print ('dense')
print (layerName)
pruned_model.add(sparsity.prune_low_magnitude(
layer,
pruning_schedule
))
else:
pruned_model.add(layer)
pruned_model.summary()
3.进行训练:
pruned_model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer='adam',
metrics=['accuracy'])
callbacks = [
sparsity.UpdatePruningStep()
]
pruned_model.fit(
train_generator,
steps_per_epoch=train_num//batch,
validation_data=validation_generator,
validation_steps=val_num//batch,
initial_epoch = 0,
epochs=10,
callbacks=callbacks)
4.去除剪枝封装并保存模型:
final_model = sparsity.strip_pruning(pruned_model)
final_model.summary()
tf.keras.models.save_model(final_model, 'pruned_final_model.h5', include_optimizer=False)
5.试验结果:
压缩前模型大小:
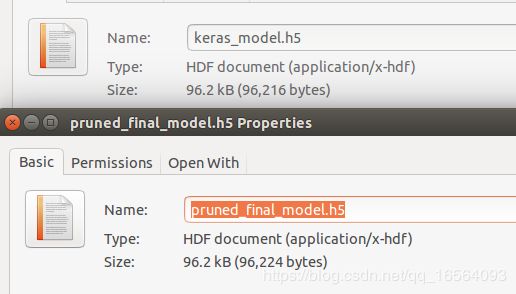
压缩后模型大小:

运行速度比较:

可以看到模型压缩后大小明显小了很多。速度也得到明显的提升。