yolo TensorFlow实战(一)yolo算法理解
相关资料
论文原稿以及翻译:https://github.com/SnailTyan/deep-learning-papers-translation
可用示例(yolo v3):https://github.com/xiaochus/YOLOv3
yolo算法吴恩达视频:https://mooc.study.163.com/learn/2001281004?tid=2001392030#/learn/content?type=detail&id=2001729334
基础知识
这里推荐上面所说的吴恩达老师的视频,非常详细,讲得非常好,虽然是英文讲课,但是配上中文字幕,多看两遍,会有很大的收获。
神经网络基础
25个基本概念:
https://blog.csdn.net/pangjiuzala/article/details/72630166
相对系统的整理(Deep Learning(深度学习)学习笔记整理系列):
https://blog.csdn.net/zouxy09/article/details/8775360
卷积神经网络
卷积神经网络为什么能够提取特征,其实我觉得还不是特别清楚:
https://blog.csdn.net/weixin_42078618/article/details/83895555
卷积神经网络(cnn)基本原理和公式推导:
https://blog.csdn.net/weipf8/article/details/82081866
目标检测
目标检测原理以及应用:
https://blog.csdn.net/qq_35451572/article/details/80249259
yolo
yolo简介:
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。在2017年CVPR上,Joseph Redmon和Ali Farhadi又发表的YOLO v2,进一步提高了检测的精度和速度。
人们瞥一眼图像,立即知道图像中的物体是什么,它们在哪里以及它们如何相互作用。人类的视觉系统是快速和准确的,使我们能够执行复杂的任务,如驾驶时没有多少有意识的想法。快速,准确的目标检测算法可以让计算机在没有专门传感器的情况下驾驶汽车,使辅助设备能够向人类用户传达实时的场景信息,并表现出对一般用途和响应机器人系统的潜力。
目前的检测系统重用分类器来执行检测。为了检测目标,这些系统为该目标提供一个分类器,并在不同的位置对其进行评估,并在测试图像中进行缩放。像可变形部件模型(DPM)这样的系统使用滑动窗口方法,其分类器在整个图像的均匀间隔的位置上运行。
最近的方法,如R-CNN使用区域提出方法首先在图像中生成潜在的边界框,然后在这些提出的框上运行分类器。在分类之后,后处理用于细化边界框,消除重复的检测,并根据场景中的其它目标重新定位边界框[13]。这些复杂的流程很慢,很难优化,因为每个单独的组件都必须单独进行训练。
我们将目标检测重新看作单一的回归问题,直接从图像像素到边界框坐标和类概率。使用我们的系统,您只需要在图像上看一次(YOLO),以预测出现的目标和位置。
YOLO很简单:参见图1。单个卷积网络同时预测这些盒子的多个边界框和类概率。YOLO在全图像上训练并直接优化检测性能。这种统一的模型比传统的目标检测方法有一些好处。
 图1:YOLO检测系统。用YOLO处理图像简单直接。我们的系统(1)将输入图像调整为448×448,(2)在图像上运行单个卷积网络,以及(3)由模型的置信度对所得到的检测进行阈值处理。
图1:YOLO检测系统。用YOLO处理图像简单直接。我们的系统(1)将输入图像调整为448×448,(2)在图像上运行单个卷积网络,以及(3)由模型的置信度对所得到的检测进行阈值处理。
yolo的实现
统一检测(Unified Detection)
统一检测是yolo的核心,区别于普通的滑动窗口法,YOLO将输入图像划分为S*S的栅格,每个栅格负责检测中心落在该栅格中的物体,如下图所示:

对于图中的狗来说,红点就是狗的中心,红点所在的方格负责检测狗,同时我们在标记标签的时候也以此方格作为标记。
每个网格单元预测这些盒子的B个边界框(bounding boxes)和置信度分数(confidence scores)。这些置信度分数反映了该模型对盒子是否包含目标的信心,以及它预测盒子的准确程度。在形式上,我们将置信度定义为:
![]()
如果这个栅格中不存在一个 object,则置信度分数(confidence score)应该为0;否则的话,置信度分数则为 predicted bounding box与 ground truth box之间的 IOU(交并比:https://blog.csdn.net/mdjxy63/article/details/79343733)。
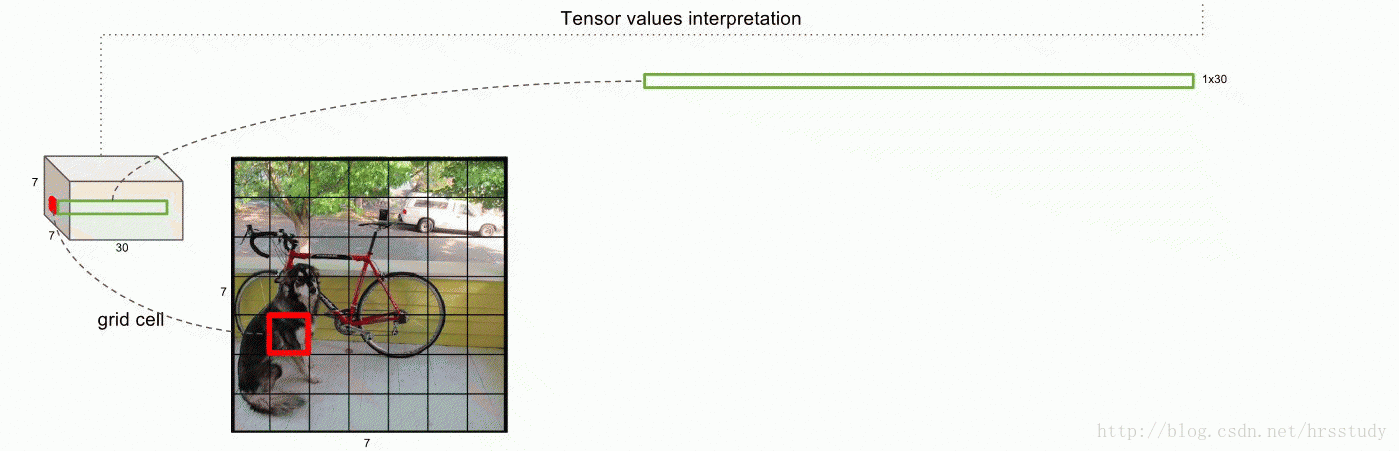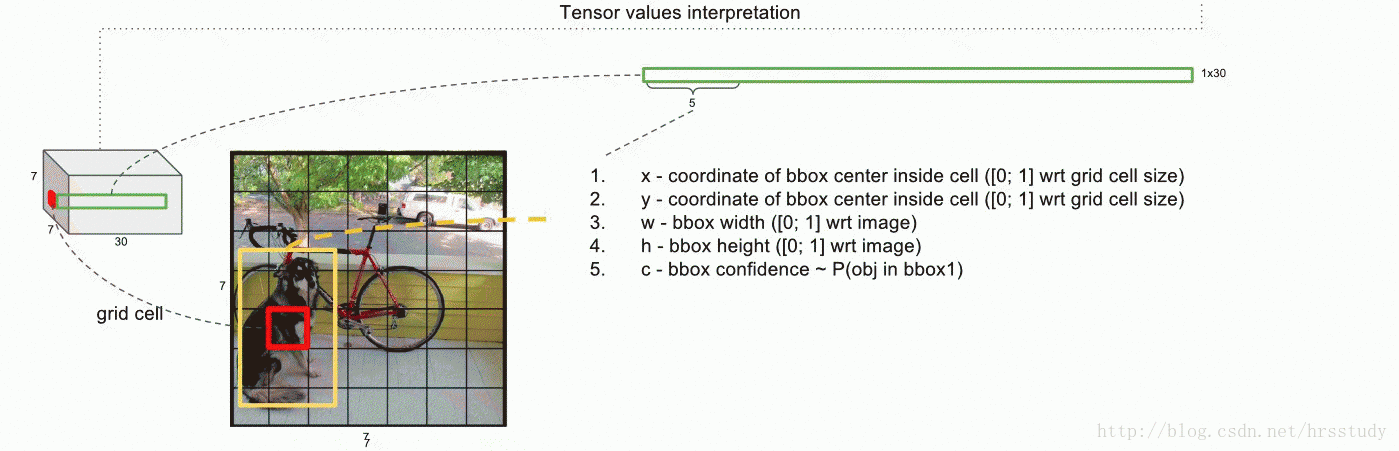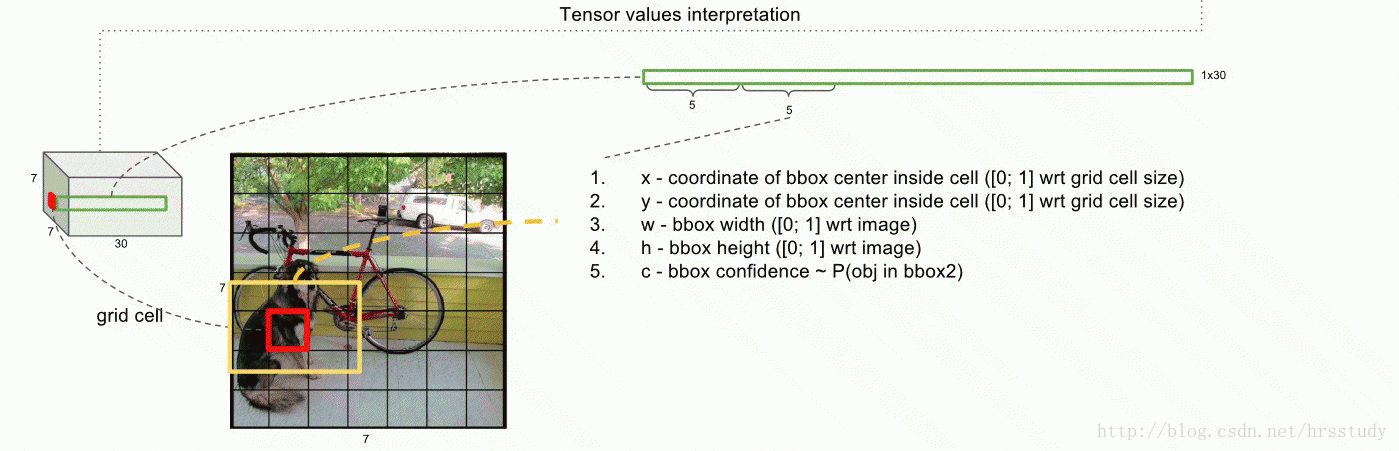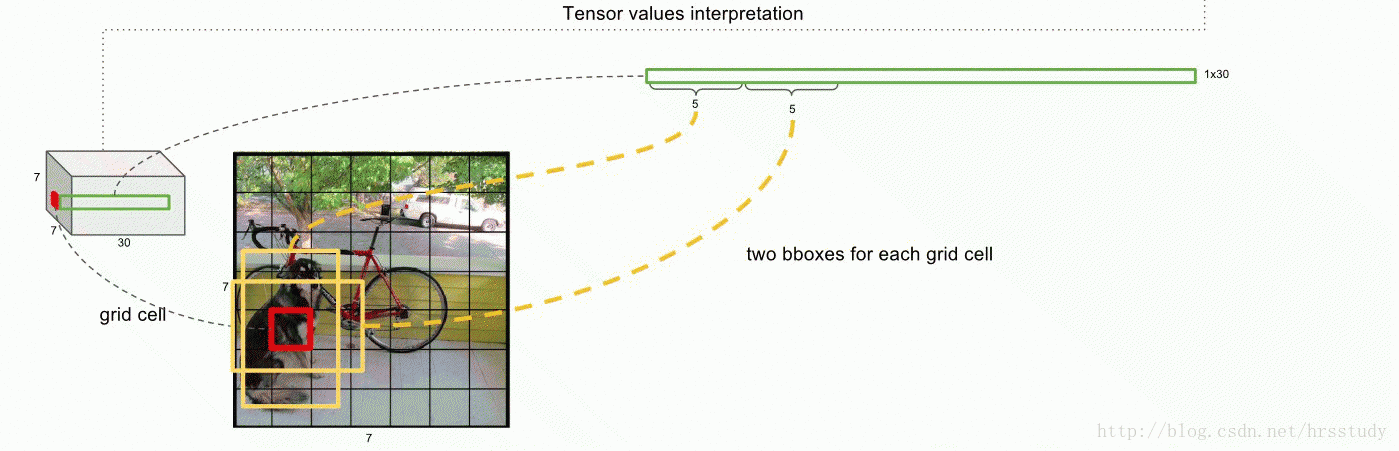
YOLO对每个bounding box有5个predictions:x, y, w, h, and confidence。
坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
confidence就是预测的bounding box和ground truth box的IOU值。
我们这里以7X7的栅格为例,每个栅格我们给出2个bounding boxes,同时我们的类别C有20个,那么相当于我们对于每一个栅格就有(2X5+20=30个数据)那么我们的预测结果就能够用下图表示(此图是在另一个帖子上转载的:https://blog.csdn.net/hrsstudy/article/details/70305791):

C=20意味着20个类,我们对于每一个类的预测值叫做条件类别概率(conditional class probability:Pr(Class_i|Object))
在测试时,我们将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘, 这乘积既包含了bounding box中预测的class的 probability信息,也反映了bounding box是否含有Object和bounding box坐标的准确度。:
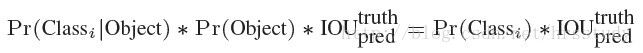
对于每一个栅格都进行这样的操作,最后会得到7X7X30X2的tensor
如图:

其实这里还存在一些很重要的问题,包括非最大抑制问题
这里引用了另一位大佬的帖子:https://blog.csdn.net/m0_37192554/article/details/81092514
首先我先介绍一下非极大值抑制算法(non maximum suppression, NMS)这个算法不单单是针对Yolo算法的,而是所有的检测算法中都会用到。NMS算法主要解决的是一个目标被多次检测的问题,如图11中人脸检测,可以看到人脸被多次检测,但是其实我们希望最后仅仅输出其中一个最好的预测框,比如对于美女,只想要红色那个检测结果。那么可以采用NMS算法来实现这样的效果:首先从所有的检测框中找到置信度最大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框。Yolo预测过程也需要用到NMS算法。
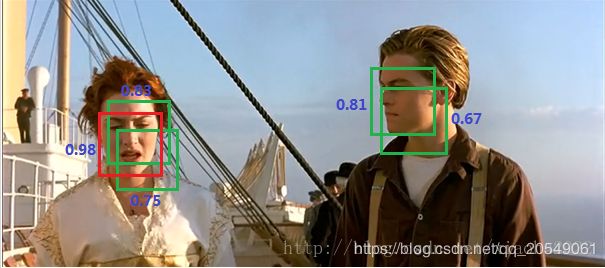
图7NMS应用在人脸检测
下面就来分析Yolo的预测过程,这里我们不考虑batch,认为只是预测一张输入图片。根据前面的分析,最终的网络输出是个边界框。
所有的准备数据已经得到了,那么我们先说第一种策略来得到检测框的结果,我认为这是最正常与自然的处理。首先,对于每个预测框根据类别置信度选取置信度最大的那个类别作为其预测标签,经过这层处理我们得到各个预测框的预测类别及对应的置信度值,其大小都是。一般情况下,会设置置信度阈值,就是将置信度小于该阈值的box过滤掉,所以经过这层处理,剩余的是置信度比较高的预测框。最后再对这些预测框使用NMS算法,最后留下来的就是检测结果。一个值得注意的点是NMS是对所有预测框一视同仁,还是区分每个类别,分别使用NMS。Ng在deeplearning.ai中讲应该区分每个类别分别使用NMS,但是看了很多实现,其实还是同等对待所有的框,我觉得可能是不同类别的目标出现在相同位置这种概率很低吧。
上面的预测方法应该非常简单明了,但是对于Yolo算法,其却采用了另外一个不同的处理思路(至少从C源码看是这样的),其区别就是先使用NMS,然后再确定各个box的类别。其基本过程如图12所示。对于98个boxes,首先将小于置信度阈值的值归0,然后分类别地对置信度值采用NMS,这里NMS处理结果不是剔除,而是将其置信度值归为0。最后才是确定各个box的类别,当其置信度值不为0时才做出检测结果输出。这个策略不是很直接,但是貌似Yolo源码就是这样做的。Yolo论文里面说NMS算法对Yolo的性能是影响很大的,所以可能这种策略对Yolo更好。但是我测试了普通的图片检测,两种策略结果是一样的。
图8 Yolo的预测处理流程
这个图有点花,而且有点小错误,我用excel做了一个简单的一个类的处理流程

网络设计(Network Design)
YOLO检测网络包括24个卷积层和2个全连接层,如图所示:
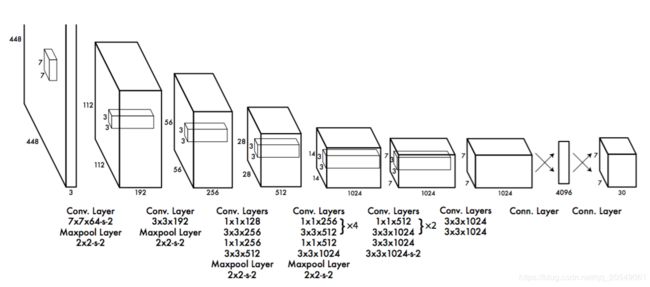
注:上图表示的卷积过程一个有8个,对于每一个过程,都有输入层,卷积核层,然后一个最大池化层。以第一个图为例:输入是一个448X448X3的图片,卷积核7X7 ,64个卷积核,strides=2,那么卷积结果根据公式,好吧这里我用公式没算出来,鬼知道他怎么算的,这里涉及到了GoogLeNet,我不会。
损失函数
关于yolo的损失函数,说实在的,我看论文真的没有看得懂,都他么写的什么玩意儿,我这智商确实不够用。于是我重新找了一个帖子
大家请移步这个帖子,讲得很好,很清楚
https://blog.csdn.net/shengyan5515/article/details/84036734