Tensorflow四种交叉熵函数计算公式
Tensorflow交叉熵函数:cross_entropy
注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
Note:
它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mea(loss)使用
计算公式:

Python 程序:
import tensorflowas tf
import numpy as np
def sigmoid(x):
return 1.0/(1+np.exp(-x))
# 5个样本三分类问题,且一个样本可以同时拥有多类
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]
logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pred = sigmoid(logits)
E1 = -y*np.log(y_pred)-(1-y)*np.log(1-y_pred)
print(E1) # 按计算公式计算的结果
sess =tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
print(E2)
输出的E1,E2结果相同
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes]
labels:和logits具有相同type和shape的张量(tensor),,是一个有效的概率,sum(labels)=1, one_hot=True(向量中只有一个值为1.0,其他值为0.0)
name:操作的名字,可填可不填
output:
loss,shape:[batch_size]
Note:
它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
计算公式:

Python程序:
import tensorflow as tf
import numpy asnp
def softmax(x):
sum_raw = np.sum(np.exp(x),axis=-1)
x1 = np.ones(np.shape(x))
for i inrange(np.shape(x)[0]):
x1[i] = np.exp(x[i])/sum_raw[i]
return x1
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])# 每一行只有一个1
logits =np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pred =softmax(logits)
E1 = -np.sum(y*np.log(y_pred),-1)
print(E1)
sess = tf.Session()
y = np.array(y).astype(np.float64)
E2 = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
print(E2)
输出的E1,E2结果相同
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes]
labels: shape为[batch_size],labels[i]是{0,1,2,……,num_classes-1}的一个索引, type为int32或int64
name:操作的名字,可填可不填
output:
loss,shape:[batch_size]
Note:
它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
计算公式:
和tf.nn.softmax_cross_entropy_with_logits()一样,只是要将labels转换成tf.nn.softmax_cross_entropy_with_logits()中labels的形式
tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
计算具有权重的sigmoid交叉熵sigmoid_cross_entropy_with_logits()
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
计算公式:

sigmoid_cross_entropy_with_logits
TensorFlow最早实现的交叉熵算法。这个函数的输入是logits和targets,logits就是神经网络模型中的 W * X矩阵,注意不需要经过sigmoid,而targets的shape和logits相同,就是正确的label值,例如这个模型一次要判断100张图是否包含10种动物,这两个输入的shape都是[100, 10]。注释中还提到这10个分类之间是独立的、不要求是互斥,这种问题我们称为多目标。
softmax_cross_entropy_with_logits
Softmax本身的算法很简单,就是把所有值用e的n次方计算出来,求和后算每个值占的比率,保证总和为1,一般我们可以认为Softmax出来的就是confidence也就是概率,softmaxcrossentropywithlogits和sigmoidcrossentropywithlogits很不一样,输入是类似的logits和lables的shape一样,但这里要求分类的结果是互斥的,保证只有一个字段有值,例如CIFAR-10中图片只能分一类而不像前面判断是否包含多类动物。在函数头的注释中我们看到,这个函数传入的logits是unscaled的,既不做sigmoid也不做softmax,因为函数实现会在内部更高效得使用softmax,对于任意的输入经过softmax都会变成和为1的概率预测值,这个值就可以代入变形的Cross Entroy算法- y * ln(a) - (1 - y) * ln(1 - a)算法中,得到有意义的Loss值了。如果是多目标问题,经过softmax就不会得到多个和为1的概率,而且label有多个1也无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes
softmax的公式是: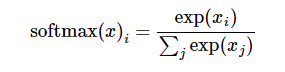
至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
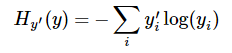
其中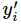 指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
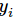 就是
就是softmax的输出向量[Y1,Y2,Y3...]
显而易见,预测越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
注意!!!这个函数的返回值并不是一个数,而是一个向量,如
果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到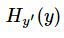 ,如果求loss,则要做
,如果求loss,则要做
一步tf.reduce_mean操作,对向量求均值!
预测获得的结果值越大,表示属于这个类的可能性更大。