tensorflow中的检查点checkpoint详解(二)——以tensorflow1.x 的模型保存与恢复为主
前言:前面专门讲解了一篇关于tensorflow2.x的文件保存,主要是介绍了两种模式,一个是keras的h5文件,一个是tensorflow专用的SavedModel(.pb文件)文件,详细请参考:
详解tensorflow2.0的模型保存方法(一)
本文会专门介绍tensorflow中的checkpoint,以及在tensorflow2.x以及tensorflow1.x中如何保存成checkpoint。
一、什么是checkpoint?以及如何保存checkpoint?
1.1 什么是checkpoint
检查点checkpoint中存储着模型model所使用的的所有的 tf.Variable 对象,它不包含任何关于模型的计算信息,因此只有在源代码可用,也就是我们可以恢复原模型结构的时候,checkpoint才有用,否则不知道模型的结构,仅仅只知道一些Variable是没有意义的。
Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值 。本质上是存储的各个变量的值,并没有网络结构信息哦!!!
1.2 tensorflow2.x 的高层kerasAPI怎么保存checkpoint
model.save_weights('path_to_my_tf_checkpoint') # 文件夹,保存checkpoint权重具体可以参考前面的那篇文章:详解tensorflow2.0的模型保存方法(一)
关于使用高层keras加载checkpoint也很简单,参考上一篇文章即可。
1.3 tensorflow1.x版本中低层PAI怎么保存checkpoint文件
(1)模型的保存
saver = tf.train.Saver() # 通过Saver类创建一个实例对象
saver.save(sess, model_path + model_name)一般的格式如下,在外面创建saver对象,然后在session里面训练结束之后开始保存,如下:
saver = tf.train.Saver()
with tf.Session() as sess:
...训练代码...
saver.save(sess, model_path + model_name)(2)Saver类介绍
下面查看一下函数原型,
tf.train.Saver(
var_list=None,
reshape=False,
sharded=False,
max_to_keep=5,
keep_checkpoint_every_n_hours=10000.0,
name=None,
restore_sequentially=False,
saver_def=None,
builder=None,
defer_build=False,
allow_empty=False,
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)几个常见的使用参数解释如下:
- var_list:保存的变量Varialble列表,也可以是一个字典映射,表示我们需要保存哪一些变量,默认情况下不用指定,表示保存所有的变量;
- max_to_keep:保存最近的几份检查点,默认是5,及保存最后5份检查点
- keep_checkpoint_every_n_hours: 格多少个小时保存一次检查点,默认是10000小时
Saver类的属性和常用方法:
Saver类的属性:
last_checkpointsSaver类的方法
as_saver_defbuildexport_meta_graphfrom_protorecover_last_checkpointsrestoresaveset_last_checkpointsset_last_checkpoints_with_timeto_proto
保存模型常用的方法save方法原型查看:
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix='meta',
write_meta_graph=True,
write_state=True,
strip_default_attrs=False,
save_debug_info=False
)
return:
返回checkpoint文件保存的文件夹地址,这个地址可以直接在restore恢复模型的时候使用参数解析:
- sess: 保存变量的会话对象
- save_path: 文件名称,保存checkpoint文件的完整路径哦,注意:这里是完整文件路径,不是文件夹哦!
- global_step: 它会作为checkpoint文件的一个后缀,
- latest_filename:
- meta_graph_suffix: 图的结构的文件的后缀,默认是 "meta" ,这个是可以更改的,
- write_meta_graph: 是否写入graph的mata文件
- write_state: Boolean indicating whether or not to write the CheckpointStateProto.
- strip_default_attrs:
- save_debug_info:
1.4 保存文件的实例
# 保存模型
saver = tf.train.Saver()
# 会话GPU的相关配置
# config 的有关配置
with tf.Session(config = config) as sess:
for epoch in range(epochs):
for i in range(train_batch_count):
# 训练代码
# epoch 结束之后保存模型
save_path = saver.save(sess, "./ckpt_model/keypoint_model.ckpt")
print("model has saved,saved in path: %s" % save_path)
'''
打印结果:
./ckpt_model/keypoint_model.ckpt 就是我们保存的文件路径
'''保存之后在当前文件夹之下的ckpt_model文件夹下面得到下面的四个文件如下:
------ckpt_model
|--------- keypoint
|--------- keypoint_model.ckpt.data-00000-of-00001
|--------- keypoint_model.ckpt.index
|--------- keypoint_model.ckpt.mata
那save函数里面这个常用的参数 global-step 怎么使用呢?常常需要在训练步骤中,隔多少步骤保存一次模型checkpoint的时候就是用这个,如下:
现在我们不是最后才保存一次检查点了,而是在每一个epoch之后,就保存一次检查点,这就需要将save的代码放到for循环里面,如下:
# 保存模型
saver = tf.train.Saver()
# 会话GPU的相关配置
# config 的有关配置
with tf.Session(config = config) as sess:
for epoch in range(epochs):
for i in range(train_batch_count):
# 训练代码
# 每一次 epoch 结束之后保存模型 ,添加global_step参数
save_path = saver.save(sess, "./ckpt_model/keypoint_model.ckpt",global_step=epoch)
print("model has saved,saved in path: %s" % save_path)
我们发现现在我们的模型是这样的:
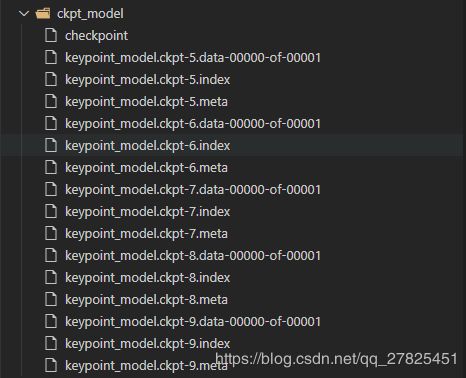
我们发现两个点:
- 第一:每一个文件在原本指定的名称,即“keypoint_model.ckpt”后面多了一个后缀数字,这个数字就是global_step指定的数字;
- 第二:按道理这里应该是保存10份检查点,从0,1,2,...7,8,9,但是之所以这里只有5,6,7,8,9这5份,是因为全面在创建的Saver对象的时候,构造函数中的默认参数为 max_to_keep =5,也就是指保存最后的5份。
所以什么时候需要使用global_step参数呢?
- 第一:在每一个epoch之后,这样global_step=epoch
- 第二:在每一个epoch内部,每隔很多个step就保存一次,这样也是可以的,这样global_step=step
1.5 checkpoint的几个文件简介(4个文件)
checkpoint的一般格式如下:
(1)meta文件
.meta文件:一个协议缓冲,保存tensorflow中完整的graph、variables、operation、collection;这是我们恢复模型结构的参照;
meta文件保存的是图结构,通俗地讲就是神经网络的网络结构。当然在使用低层PAI编写神经网络的时候,本质上是一系列运算以及张量构造的一个较为复杂的graph,这个和高层API中的层的概念还是有区别的,但是可以这么去理解,整个graph的结构就是网络结构。一般而言网络结构是不会发生改变,所以可以只保存一个就行了。我们可以使用下面的代码只在第一次保存meta文件。
saver.save(sess, 'my_model.ckpt', global_step=step, write_meta_graph=False)在后面恢复整个graph的结构的时候,并且还可以使用
tf.train.import_meta_graph(‘xxxxxx.meta’)能够导入图结构。
(2)data文件
keypoint_model.ckpt-9.data-00000-of-00001:数据文件,保存的是网络的权值,偏置,操作等等。
(3)index文件
keypoint_model.ckpt-9.index 是一个不可变得字符串字典,每一个键都是张量的名称,它的值是一个序列化的BundleEntryProto。 每个BundleEntryProto描述张量的元数据,所谓的元数据就是描述这个Variable 的一些信息的数据。 “数据”文件中的哪个文件包含张量的内容,该文件的偏移量,校验和,一些辅助数据等等。
Note: 以前的版本中tensorflow的model只保存一个文件中。
(4)checkpoint文件——文本文件
checkpoint是一个文本文件,记录了训练过程中在所有中间节点上保存的模型的名称,首行记录的是最后(最近)一次保存的模型名称。checkpoint是检查点文件,文件保存了一个目录下所有的模型文件列表;
比如我上面的模型保存了最后的5份checkpoint,这里打开checkpoint查看得到如下内容:
model_checkpoint_path: "keypoint_model.ckpt-9" # 最新的那一份
all_model_checkpoint_paths: "keypoint_model.ckpt-5"
all_model_checkpoint_paths: "keypoint_model.ckpt-6"
all_model_checkpoint_paths: "keypoint_model.ckpt-7"
all_model_checkpoint_paths: "keypoint_model.ckpt-8"
all_model_checkpoint_paths: "keypoint_model.ckpt-9"二、checkpoint信息的查看
前面说了,检查点checkpoint的本质是存储的每一个变量的数据,而在index文件中还存储着每一个Variable的名称以及它的元数据,我怎么查看checkpoint中的数据呢?
2.1 通过inspect_checkpoint工具进行查看——无需通过Session可以直接得到结果
from tensorflow.python.tools import inspect_checkpoint as chkp
# 查看模型中所有的Tensor的数据,这里的默认的all_tensor=True
print(chkp.print_tensors_in_checkpoint_file("./ckpt_model/keypoint_model.ckpt", tensor_name='', all_tensors=True))
#print("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++")
''' 输出的格式如下:
tensor_name: tensor1
... ...
tensor_name: tensor2
... ...
tensor_name: tensor3
... ...
'''如果我只想查看一个tensor的信息呢,当然,我需要这个tensor的名称我才能找得到,我可以像下面这样:
# 获取最后保存的一个checkpoint,返回的是最后一个checkpoint的文件路径
model_file = tf.train.latest_checkpoint("./ckpt_model")
print(model_file) # ./ckpt_model/keypoint_model.ckpt-9
# 查看其中的某一个张量,此时的all_tensors=False
print(chkp.print_tensors_in_checkpoint_file(model_file, tensor_name="dense4_weights", all_tensors=False))
# 当然这里我也可以自己直接传递进去最新的一个checkpoint文件路径
# print(chkp.print_tensors_in_checkpoint_file("./ckpt_model/keypoint_model.ckpt-9" tensor_name="dense4_weights", all_tensors=False))
'''
tensor_name: dense4_weights
[[ 4.58419085e-01 8.78509760e-01 2.11921871e-01 -5.90530671e-02
-6.23271286e-01 -1.86214507e-01 -3.88072550e-01 1.38646924e+00
8.91906798e-01 4.05663669e-01]
... ...中间是我自己省略了,应该是一个(32,10)的矩阵
[-1.12723565e+00 -1.26929128e+00 -2.32065111e-01 -6.23432040e-01
-3.33134890e-01 -9.74284112e-01 -6.22953475e-02 -5.75510025e-01
-8.32203925e-01 1.12205319e-01]]
'''2.2 加载graph之后进行查看——通过gragh.as_graph_def().node
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
# 通过meta文件,加载模型结构,返回的是一个saver对象
saver = tf.train.import_meta_graph('./ckpt_model/keypoint_model.ckpt-9.meta')
# 载入模型参数
saver.restore(sess,'./ckpt_model/keypoint_model.ckpt-9')
gragh = tf.get_default_graph() # 获取当前图,为了后续训练时恢复变量
tensor_name_list = [tensor.name for tensor in gragh.as_graph_def().node]# 得到当前图中所有变量的名称
for k in tensor_name_list:
print(k)
''' 结果有很多
...
...
radients/dense1_output_grad/tuple/control_dependency_1
gradients/MatMul_grad/MatMul
gradients/MatMul_grad/MatMul_1
...
...
...
dense4_weights/Adam_1/read
dense4_bias/Adam/Initializer/zeros
...
...
'''注意:什么是Graph和GraphDef
- Graph 就不说了
- GraphDef实际上是一个Graph的定义描述,记这个图中定义了哪一些节点等,
Graph对象有一个as_graph_def()方法,即它返回一个序列化的GraphDef来代表整个Graph(Returns a serialized GraphDef representation of this graph.)
而GraphDef有下面几个属性:
library
node # 就是我们使用的node属性
version
versions
三、如何恢复模型,并且进行测试
前面说过,使用低层API中实际上本质上没有层,模型这两个概念,实际上有的仅仅是operation,tensor,graph这几个概念,所谓的通过meta文件恢复模型,也只不过是恢复整个graph的结构,而没有真正的模型,所以要恢复一个模型,必须要知道这个graph的两个信息,即graph的输入是什么,输出是什么?
为了非常清楚的知道模型的“输入”与“输出”,所以,在使用tensorflow1.x的低层API的时候,需要给输入和输出指定比较明确名称,这样才能够在恢复模型的时候选择输入与输出的节点,比如下面的代码:
输入通过指定的placeholder来指定
X=tf.placeholder(dtype=tf.float32,shape=[None,img_size,img_size,1],name='input')
Y=tf.placeholder(dtype=tf.float32,shape=[None,num_class])
# 第一个卷积层
with tf.name_scope('cnn_layer_01') as cnn_01:
w1=tf.Variable(tf.random_normal(shape=[3,3,1,32],stddev=0.01))
conv1=tf.nn.conv2d(X,w1,strides=[1,1,1,1],padding="SAME")
conv_y1=tf.nn.relu(conv1)
#第一个池化层
#第二个卷积层
#第二个池化层
... ...
... ...
#全连接层
# 最后的输出层,model_Y则为神经网络的预测输出
with tf.name_scope('output_layer') as output_layer:
w5=tf.Variable(tf.random_normal(shape=[625,num_class]))
model_Y=tf.matmul(FC_y7,w5,name='output') # 输出其实就是对应最后一步的运算,这里需要取一个好的名字
当然构建网络的方式非常多,我们只需要把握两个点:
- (1)第一:输入在tensorflow1.x版本中都是通过预先设定placeholder来实现的,所以对于输入的placeholder需要取一个好记的名称;
- (2)第二:输出是整个计算图graph最后一的运算结果,需要给最后一步运算也起一个好的名称
当然对于多输入、多输出模型,道理是一样的。
比如在我上面的模型中,会有下面的模型加载代码以及测试结果:
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
# 通过meta文件,加载模型结构,返回的是一个saver对象
saver = tf.train.import_meta_graph('./ckpt_model/keypoint_model.ckpt-9.meta')
# 载入模型参数
saver.restore(sess,'./ckpt_model/keypoint_model.ckpt-9')
graph = tf.get_default_graph() # 获取当前图,为了后续训练时恢复变量
# 获取模型的输入名称
X = graph.get_tensor_by_name('model_input:0') #从模型中获取输入的那个节点
# 获取模型的输出名称
model_y = graph.get_tensor_by_name('dense4_output:0')
# 测试模型
result=sess.run(model_y,feed_dict={X:test_x}) # 需要的就是模型预测值model_Y,这里存为result3.1 从checkpoint恢复模型的一般步骤——三步走
(1)第一步:加载graph结构与保存的各个Variable
new_saver=tf.train.import_meta_graph('mnist_cnn_model/medel.ckpt.meta') # 导入模型的图结构
new_saver.restore(sess,'mnist_cnn_model/medel.ckpt') # 载入graph中的各个Variable
也等价于下面的代码
model_path = tf.train.latest_checkpoint('model_filefolder') # 获取最新的模型,注意这里的是文件夹哦
new_saver.restore(sess,model_path) (2)第二步:取得整个graph中的输入与输出
graph = tf.get_default_graph() # 获取当前图,为了后续训练时恢复变量
# 根据定义graph的时候设置的输入tensor的名称
X = graph.get_tensor_by_name('model_input:0') #从模型中获取输入的那个节点
# 根据定义graph的时候设置的模型最后一步的输出
model_y = graph.get_tensor_by_name('dense4_output:0')其中上面也可以简写为:
# 即直接使用sess.graph
X=sess.graph.get_tensor_by_name('input:0')
model_y=sess.graph.get_tensor_by_name('output_layer/output:0')
(3)第三步:测试模型,得到预测输出值
result=sess.run(model_y,feed_dict={X:test_x}) #需要的就是模型预测值model_Y,这里存为result注意:
我们发现输入与输出的tensor_name上的名称都是这样的格式:
":"
如上面出现的:
'model_input:0'
'dense4_output:0'
'input:0'
'output_layer/output:0' 为什么是这样呢?实际上需要真正理解TensorFlow中关于operation、tensor的本质
可以参考我前面的一篇文章:
以线性回归为例,深入理解tensorflow的Operation、Tensor、Node的区别
3.2 恢复模型并且进行测试的关键所在
关键所在——要能够正确找准模型的输入的tensor_name与输出的tensor_name,所以自己在编写网络结构的时候要自己起一个
易于辨识的名称,一般情况下:
- 模型输入张量名称tensor_name指的是预先输入的X=tf.placeholder()中指定的名称
- 模型输出张量名称tensor_name指的是预先输入的模型最后一步运算操作operation中指定的名称
另外,关于使用tensorflow低层函数自己搭建神经网络有一些一般的模板,将会在我的下面一篇文章中说到,请参考:
使用低层API来构建网络的方法
https://blog.csdn.net/weixin_42008209/article/details/82715202
四、再谈export_meta_graph和Import_meta_graph
前面说过了在保存这个模型的检查点的时候会默认保存一个 xxx.meta 文件,如果我们不想保存检查点,仅仅想保存一个graph的结构可以使用下面的方法:
(1)tf.train.export_meta_graph()——保存graph结构
with tf.Session() as sess:
pred = model_network(X)
loss=tf.reduce_mean(…,pred, …)
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
Meta_graph_def = tf.train.export_meta_graph(tf.get_default_graph(), 'my_graph.meta')(2)tf.train.import_meta_graph()——载入graph结构
同上面的方法一样,直接使用下面的方法加载整个graph结构
# 仅仅载入模型结构
saver = tf.train.import_meta_graph('./quant_ckpt_model/quant_keypoint_model.ckpt-99.meta')
# 载入模型参数
saver.restore(sess,'./quant_ckpt_model/quant_keypoint_model.ckpt-99')
# 获取载入的graph
graph = tf.get_default_graph() # 获取当前图,为了后续训练时恢复变量