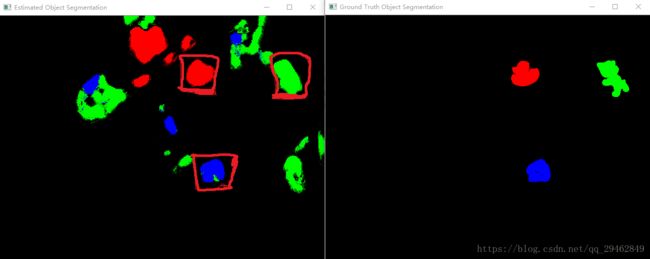
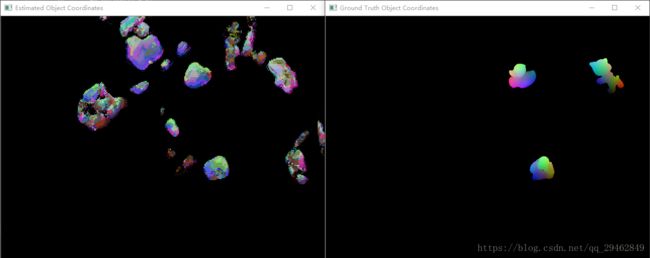
基于随机森林的姿态识别算法
本博客主要是对“Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image”
论文的解读。
论文地址:https://www.computer.org/csdl/proceedings/cvpr/2016/8851/00/8851d364-abs.html
1.训练数据的采集
由于是基于像素级的训练,所以需要每个像素都需要标签,这个标签包括每个像素所属的类别以及对应的三维空间坐标。
a.标签如何获取呢?
可以首先利用传统的设备计算出某类物体和相机的真实姿态,计算出真实姿态就可以通过物体的二维图像计算出相对应的三维坐标。然而在实际计算三维坐标时需要把训练的物体分割开来,这样可以避免背景等一些不相关物体的干扰,通过对分割后的图像进行姿态运算,可以得出分割图像中每个像素的三维坐标。
由于是在像素级进行训练与预测,通常一幅图像中的某个物体由大量像素组成,所以在实际训练的时候不需要太大的样本(样本过多的话需要在训练数据上花费很长时间),不过要尽量包含各个姿态下的数据,这样模型才能尽可能的准确,一般100张图像(对每类物体来说)即可。
b.每个像素的features?

在这里δ代表一个二维的偏移(u,v),这里的偏移没有在参考文献中找到具体介绍,在代码里max offset=20,且δ≥0,所以0≤u≤20,0≤v≤20,δ_1和δ_2范围大致相同(这里u,v的量纲是px.m, px代表像素)。D(p)代表像素p的深度值,这里D(p)是用来深度归一化,单位是m。因此,如果在标准设置中的偏移量δ为20 px.m,像素深度D(p)为1 m,则该公式计算的δ/D(p)为20 px;如果深度为2米,则公式评估为10 px。即像素越远,真正偏移就越小,这也即是深度归一化。I(p,c)代表在图像中c通道中p像素对应的像素值,通常把这两种特征结合(拼接)起来一起用。
其实在这里每个像素的features是该像素周围一些像素的像素值的差或者深度值的差。Features的选择很重要,建立好特征才能进行训练,才能更好区分不同标签。
注意:在这里对训练图像中每类物体随机采样1000个像素,每个像素采样1000个features。(当然这里的像素数量以及features数量是可以改变的,这取决于自己,1000是作者推荐的数值,有比较好的结果)。
2.训练数据
Auto-context:
这篇paper中的分类器是Auto-context随机森林,给定图像中的某个像素,通过该随机森林预测,可以得出其对应的三维坐标以及所属物体类别两种信息。
在得到每个像素的特征后,就可以通过这些特征来训练随机森林。Auto-context随机森林结构如下图所示,Auto-context随机森林由多个随机森林组成(在这篇paper里由三个随机森林构成,每个随机森林由三棵决策树构成)。上一个随机森林的输出是下一个随机森林的输入,相邻的随机森林互相关联。
具体训练过程如下:
第一个随机森林以每个像素的features作为输入,最终输出每个像素对应的三维坐标以及类别[x,y,z,a](每个像素的三维坐标和类别在训练集中均有给出,这里只是用来训练随机森林)。
第二个随机森林对每个像素再次进行训练,只是在这里,每个像素的特征由上面的features和其周围8个像素标签值构成(这个标签值是由第一个随机森林产生的[x,y,z,a]。其实这里的neighbor可以不止8个,而且neighbor排列位置也可以有所不同,不一定就是像素的八邻域。Auto-context允许使用像素的小范围或者大范围相邻像素[比如也可以是24个]标签值作为像素的features,取决于自己算法的选择)。这样第二个随机森林对每个像素再一次进行预测,可以得出新的[x,y,z,a],每个像素的标签值进行更新。
注意:在这里由于随机森林是由多个决策树组成的,这篇paper采用三棵决策树,所以每棵树都会预测出一个标签值,对类别标签a来说可以通过投票方式进行处理,但是对于[x,y,z]三维坐标点,则需要进行几何均值处理,这样作为最终的标签坐标。
当第一个随机森林构建完成后,会预测产生相应的标签图和三维坐标图,在训练第二个随机森林之前,需要对产生的标签图进行中值滤波处理,对产生的三维坐标图中的每个值以一定大小的模板(比如3x3)进行几何平均数,把最终的几何平均数结果作为新的坐标标签值。
第三个随机森林和第二个随机森林训练方式相同,同样每个像素的特征由features和其周围16个像素标签值构成(这里的像素数量16要根据具体算法确定,不是一成不变的,当然也可以是10或其它数字),只是这里的标签值是由第二个随机森林预测出的而不是第一个。通过这种方式进行多次迭代,最终可以得到较为准确的结果。

在构建随机森林时,作者采用L1正则化的方式来防止随机森林中的决策树过拟合。根据决策树的结构这里的L1正则化其实就是对决策树的剪枝,剪枝操作可以剔除一些不重要的特征,在预测新数据的时候会比较准确。
3.利用决策树进行像素的三维坐标预测
通过上述训练好的Auto-context随机森林,对输入图像中每个像素进行预测,可以得出对应像素在三维空间下的坐标以及所属类别。
4.计算初始姿态采样
上一步可以预测输入图像中每个像素的三维坐标和其物体所属类别,这样就可以得到基于特定类别下的2D-3D对应点对。Pnp问题求解至少需要3个对应点对,这篇paper采集了四对对应点对。
采样方法:
在这里paper提出了一种采样方法,首先随机选取指定物体类别下的一个像素,然后基于这个像素为中心,画一个正方形(比如说3x3),剩下的三个像素则是在这个正方形内寻找。我的思考:是否可以随机选取一个像素,然后以这个像素为左上角第一个像素,画2x2正方形,剩下的三个像素则是从2x2正方形中采集(也就是正方形中剩下的三个位置所对应的像素)。
注意:在这里需要做个判断,如果选的四个像素不都是同一种类物体的像素,那么需要重新选择。直到所选的四个像素都属于同一类物体。
Multi-RANSAC
一幅图像中通常不止包含一种物体,往往含有几种物体,因此这篇paper提出了一种multi-RANSAC方法。
对一幅图像中只有一个物体来说,通过对该物体进行一定次数的采样(采集二维点和对应的三维点),可以得到许多副2D-3D对应点对(每副对应点对有四个对应点对,负责求解一个姿态),基于这些点对进行姿态计算,可以得到一定数量的初始姿态[R,T]。3D点通过初始姿态运算,可以投影到二维图像坐标上,这个投影点和3D点对应的2D点做距离运算,因为图像坐标系中的单位为px(像素),当投影点和2D点之间的距离不大于3px,则视为该点为内点,否则为外点。
重投影误差:
注意:在采样时,比如采样四个像素,当利用这四个像素计算初始姿态后,如果经过这个姿态运算后的重投影误差过大(大于一定的阈值),则抛弃该姿态,进行重新采样,这样就避免了RANSAC在不良数据上迭代,从而节省了时间。
这样每个姿态都会计算出一定数量的内点,基于内点的数量对初始姿态进行优劣排序,并在这些姿态中保留内点数量多的一半,舍弃另一半。然后对保留下的一半姿态,根据其内点继续对姿态进行优化,得出新的姿态(在这里,对内点采样一次,只得出一个新的姿态),和以上步骤相同,对这些新的姿态根据内点的数量进行排序,保留靠前的一半,舍弃后面的一半。这样一直循环,直到内点数量基本保持不变,而且可以通过这种方式过滤出唯一的最佳姿态,这个姿态就是最终姿态。
注意:和单个物体RANSAC算法相比,多个物体的RANSAC算法有所不同。许多方法都尝试把多个对象合并到同一坐标空间中,但这有一定的缺点。这篇文章,由于通过随机森林可以预测出每个像素的标签,这样就可以把不同对象分成独立不同的坐标空间。对于每个对象来说,只在自己的空间进行姿态估计。
5.姿态优化
在得到全局最优姿态后,基于该姿态下的内点可以通过Kabsch algorithm(matlab有相对应的函数,GitHub上有相对应的C++源代码)进一步对姿态进行优化,从而得到最终的姿态。
Kabsch algorithm只优化旋转矩阵,不优化平移矩阵,因为在实际运行中,旋转矩阵对精度影响更为大。
Kabsch algorithm具体算法见附录
6.该算法的优缺点
算法的优点:
Auto-context随机森林方法,通过多层森林预测(上一层森林的输出值作为该层的输入值),并通过引进L1正则化可来减少预测的不确定性,这对处理遮挡以及无纹理物体比较有优势。除此之外,这篇paper采用multi-RANSAC算法,该算法可以同时处理多个不同物体的姿态识别,速度比较快;不过对多个同种物体则需要相应的改进(这篇paper提出的算法针对不同物体的检测,包括后续的姿态计算也是分别在不同坐标系下计算得出,对多个同种物体的检测则首先需要确定物体的个数)。
算法的缺点:
由于是像素级的密集预测,在实验过程中会有相当一部分的背景像素被预测为某类物体像素,也就是当图像中出现和检测物体相近的颜色特征时,该算法会出错,也是因为这个原因,对姿态估计会产生很大影响,往往误差会很大。除此之外,在某些视角下(比如正视图)往往会忽略物体在其它视角下(比如左视图)的形状,不能够很好的估计出正确姿态,在旋转向量上误差较大。