CNN卷积方式总结
本篇文章内容侧重于卷积方式的变形,如空洞卷积、可分离卷积等,水平所限,见解可能有所偏差,请大牛指正。
1.原始版本
最早的卷积方式还没有任何骚套路,那就也没什么好说的了。
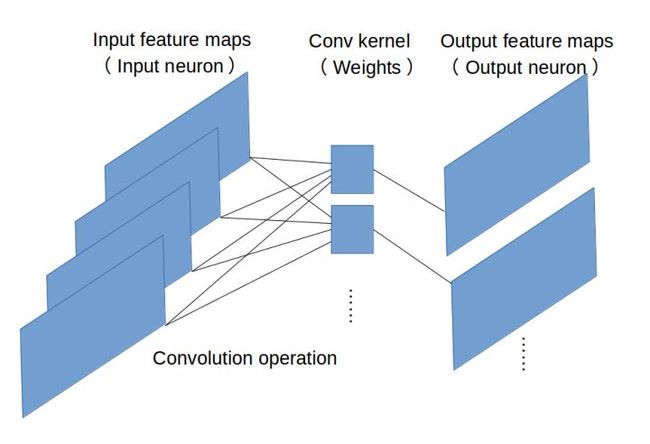
代表模型:
LeNet:最早使用stack单卷积+单池化结构的方式,卷积层来做特征提取,池化来做空间下采样
AlexNet:后来发现单卷积提取到的特征不是很丰富,于是开始stack多卷积+单池化的结构
VGG([1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition):结构没怎么变,只是更深了
2.多隐层非线性版本
这个版本是一个较大的改进,融合了Network In Network的增加隐层提升非线性表达的思想,于是有了这种先用1*1的卷积映射到隐空间,再在隐空间做卷积的结构。同时考虑了多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,再把结果concat起来。
这一结构,被称之为“Inception”,关于inception家族可以去看从Inception v1到Inception-ResNet,一文概览Inception家族的「奋斗史」

其实通俗理解就是先把input feature map通过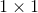 卷积把channel数降下来,然后进行或者
卷积把channel数降下来,然后进行或者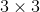 等小卷积核进行卷积处理,然后再过融合把channel数升回去。
等小卷积核进行卷积处理,然后再过融合把channel数升回去。
代表模型:
Inception-v1([1409.4842] Going Deeper with Convolutions):stack以上这种Inception结构
Inception-v2(Accelerating Deep Network Training by Reducing Internal Covariate Shift):加了BatchNormalization正则,去除5*5卷积,用两个3*3代替
Inception-v3([1512.00567] Rethinking the Inception Architecture for Computer Vision):7*7卷积又拆成7*1+1*7
Inception-v4([1602.07261] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning):加入了残差结构
3.空洞卷积(Dilated convolution)
标准的3×3卷积核只能看到对应区域3×3的大小,但是为了能让卷积核看到更大的范围,dilated conv使其成为了可能。dilated conv原论文中的结构如图所示:
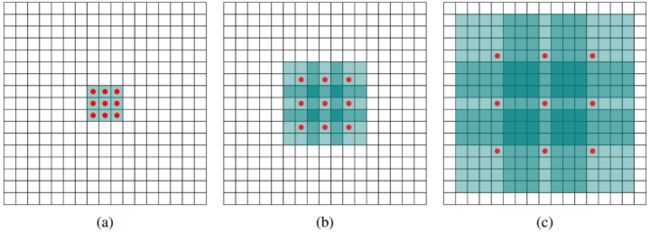
上图b可以理解为卷积核大小依然是3×3,但是每个卷积点之间有1个空洞,也就是在绿色7×7区域里面,只有9个红色点位置作了卷积处理,其余点权重为0。这样即使卷积核大小不变,但它看到的区域变得更大了。
这里详细解释一下吧:
(a)图对应3x3的1-dilated conv,和普通的卷积操作一样,(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv),(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
可以回顾一下上篇感受野的计算公式
(a) RF_a = 1 + (3 - 1) x 1 x 1 = 3 kernel_size = 3, stride = 1 dilate rate = 1
(b) RF_b = 3 + (3 -1) x 1 x 2 = 7 kernel_size = 3, stride = 1, dilate_rate = 2
(c) RF_c = 7+ (3 -1) x 1 x 4 = 15 kernel_size = 3, stride = 1, dilate_rate = 4
详细解释可以看这个回答:如何理解空洞卷积(dilated convolution)?
4.深度可分离卷积
Depthwise Separable Convolution,目前已被CVPR2017收录,这个工作可以说是Inception的延续,它是Inception结构的极限版本。
为了更好的解释,让我们重新回顾一下Inception结构(简化版本):

上面的简化版本,我们又可以看做,把一整个输入做1*1卷积,然后切成三段,分别3*3卷积后相连,如下图,这两个形式是等价的,即Inception的简化版本又可以用如下形式表达:
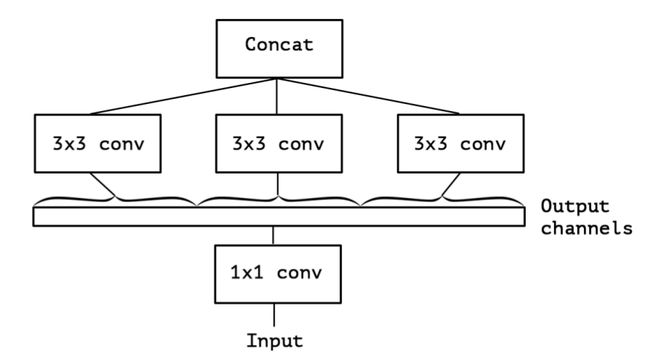
OK,现在我们想,如果不是分成三段,而是分成5段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,切到不能再切了,正好是Output channels的数量(极限版本):

于是,就有了深度卷积(depthwise convolution),深度卷积是对输入的每一个channel独立的用对应channel的所有卷积核去卷积,假设卷积核的shape是[filter_height, filter_width, in_channels, channel_multiplier],那么每个in_channel会输出channel_multiplier那么多个通道,最后的feature map就会有in_channels * channel_multiplier个通道了。反观普通的卷积,输出的feature map一般就只有channel_multiplier那么多个通道。
既然叫深度可分离卷积,光做depthwise convolution肯定是不够的,原文在深度卷积后面又加了pointwise convolution,这个pointwise convolution就是1*1的卷积,可以看做是对那么多分离的通道做了个融合。
这两个过程合起来,就称为Depthwise Separable Convolution了:
代表模型:Xception(Xception: Deep Learning with Depthwise Separable Convolutions)
5.特征重标定卷积
这是ImageNet 2017 竞赛 Image Classification 任务的冠军模型SENet的核心模块,原文叫做”Squeeze-and-Excitation“,我结合我的理解暂且把这个卷积称作”特征重标定卷积“。
和前面不同的是,这个卷积是对特征维度作改进的。一个卷积层中往往有数以千计的卷积核,而且我们知道卷积核对应了特征,于是乎那么多特征要怎么区分?这个方法就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照计算出来的重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
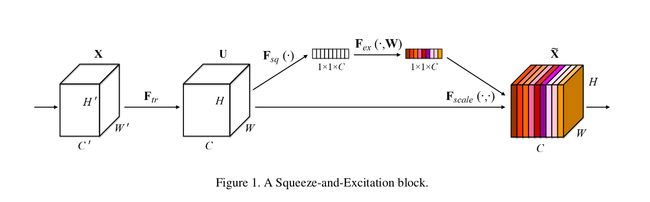
这个想法的实现异常的简单,简单到你难以置信。
首先做普通的卷积,得到了一个的output feature map,它的shape为[C,H,W],根据paper的观点,这个feature map的特征很混乱。然后为了获得重要性的评价指标,直接对这个feature map做一个Global Average Pooling,然后我们就得到了长度为C的向量。(这里还涉及到一个额外的东西,如果你了解卷积,你就会发现一旦某一特征经常被激活,那么Global Average Pooling计算出来的值会比较大,说明它对结果的影响也比较大,反之越小的值,对结果的影响就越小)
然后我们对这个向量加两个FC层,做非线性映射,这俩FC层的参数,也就是网络需要额外学习的参数。
最后输出的向量,我们可以看做特征的重要性程度,然后与feature map对应channel相乘就得到特征有序的feature map了。
虽然各大框架现在都还没有扩展这个卷积的api,但是我们实现它也就几行代码的事,可谓是简单且实用了。
另外它还可以和几个主流网络结构结合起来一起用,比如Inception和Res:

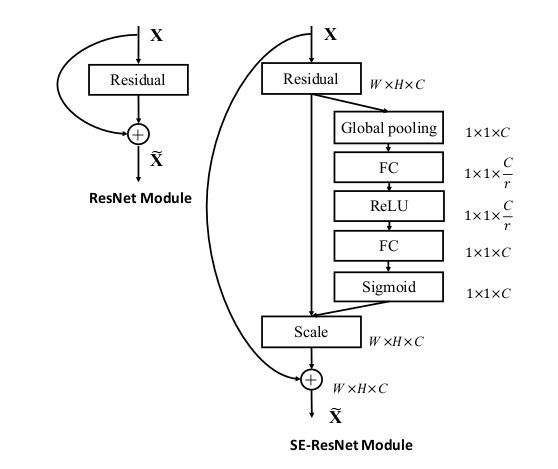
代表模型:Squeeze-and-Excitation Networks(Squeeze-and-Excitation Networks)
原文链接:CNN中千奇百怪的卷积方式大汇总