ml-agent学习笔记(二),unity建立新场景训练个人AI的基础代码操作
在前面配置好开发环境和Unity项目后,我们开始训练自己的个人AI,分为以下步骤,没有看过前面章节的推荐看完后在继续往下看
前一章节博客的链接如下:https://blog.csdn.net/qq_31157943/article/details/104163182
一,首先你需要把从Github上下载下来的ml-agents的文件包中的UnitySDK/Assets下的ML-Agents文件夹拖入unity项目的Assets文件下,这个文件下有有些官方的例子,感兴趣的可以看看,然后设置好unity支持.Net4.x,然后再把下载下来的ml-agents文件包中的config文件下的trainer_config.yaml文件导入unity的Assets根目录,这些都做完后,unity项目的文件列表应该像这样。

二.上面都做完后且没有问题后我们继续,我们先来搭建一个简单的场景 ,思路我们训练一个简单的小球自动寻找方块的AI
1.首先建一个Plane的GameObject,改名叫Floor,坐标,旋转清零,缩放为1
2.建一个Cube的GameObejct,改名叫Target,坐标(3,0.5,3),旋转清零,缩放为1
3.建一个Sphere的GameObject,改名叫RollerAgent,坐标(0,0.5,0),旋转清零,缩放为1,这个游戏物体作为挂载我们AI脚本的游戏物体,并挂载Rigidbody
4.建一个空物体,名字叫TrainingArea,坐标,旋转清零,缩放为1,作为以上3个物体的服务体,把三面3个物体拖到它下面
三,基本环境搭建完成,下面我们开始讲代码部分。
1.新建一个叫RollerAgent的脚本,挂在RollerAgent的GameObject上。
2.编辑脚本
(1)在编辑器中,添加using MLAgents;语句,然后将基类从更改MonoBehaviour为Agent。
(2)删除该Update()方法,但是我们将使用该Start()函数,因此暂时不要使用它。如图所示

(3) 初始化和重置代理,思路为当Agent达到其目标时,它将标记为已完成,并且其Agent重置功能会将目标移动到随机位 置。此外,如果Agent从平台上滑落,重置功能会将其放回地板上。代码如下
using System.Collections.Generic;
using MLAgents;
using UnityEngine;
///
/// 个人AI训练测试1
///
public class RollerAgent : Agent {
Rigidbody rigidbody;
void Start () {
rigidbody = transform.GetComponent();
}
public Transform target;
///
///重构AI重置训练时的方法
///
public override void AgentReset()
{
//重置AI的位置和刚体的速度
if(transform.localPosition.y < 0)
{
rigidbody.angularVelocity = Vector3.zero;
rigidbody.velocity = Vector3.zero;
transform.localPosition = new Vector3(0f,0.5f,0f);
}
//随机设置AI目标的位置
target.localPosition = new Vector3(Random.value * 8 - 4,0.5f,Random.value * 8 -4);
}
} (4)接下来,让我们实现该Agent.CollectObservations()方法。重构这个方法的意义在于收集我们需要的数据来辅助AI训练。在我们训练的这个模型中需要收集以下重要信息:1.AI自己的位置 2.目标的位置,3.AI自己在XZ平面上的速度(x轴上的速度,z轴上的速度),代码如下
///
/// 收集AI训练时的数据,用作训练参考的数据
///
public override void CollectObservations()
{
/*需收集以下参考量(基本)
1.目标的位置
2.自己的位置
3.自己的刚体的角速度和速度
*/
AddVectorObs(target.localPosition);
AddVectorObs(transform.localPosition);
AddVectorObs(rigidbody.velocity.x);
AddVectorObs(rigidbody.velocity.z);
} (5)最后一部分是实现AI的具体动作和获得的相关奖励,1.实现Agent.AgentAction()方法,该方法从AI接收决策并分配奖励。 传递给AgentAction()函数的数组的形式出现 ,此数组中元素的数量由Vector Action Space Type和Space Size设置确定,等下再具体讲述,而我们要训练的这个AI只需要两个控制信号,所以Space Size = 2,第一个元素action[0]确定沿x轴施加的力;第二个元素确定沿z轴施加的力。action[1]确定沿z轴施加的力。(如果我们允许Agent在三个维度上移动,则需要设置Vector Action Size到3。),注意的是AI确实不知道数组中的值是什么意思。训练过程只是根据观察输入调整动作值,然后查看其结果是什么样的奖励。2.实现奖励,强化学习需要奖励。在AgentAction() 功能中分配奖励。学习算法使用在模拟和学习过程中分配给Agent的奖励来确定它是否正在为Agent提供最佳行动。奖励完成分配的任务。在这种情况下,代理达到目标多维数据集可获得1.0的奖励。我们的AI计算距离以检测到达目标的距离。完成后,代码将调用Agent.SetReward()方法以分配1.0的报酬,并通过Done()在代理上调用方法将代理标记为完成。代码如下
//设置给AI完成目标时的奖励分配
public float speed = 10f;
public override void AgentAction(float[] vectorAction)
{
Vector3 controlSingal = Vector3.zero;
controlSingal.x = vectorAction[0];
controlSingal.z = vectorAction[1];
rigidbody.AddForce(controlSingal * speed);
//奖励
float distanceToTarget =
Vector3.Distance(transform.localPosition,target.localPosition);
//到达目标
if(distanceToTarget < 1.42f)
{
//设置奖励,标记方法完成
SetReward(1.0f);
Done();
}
//自己落下平台,重置
if(transform.localPosition.y < 0)
{
Done();
}
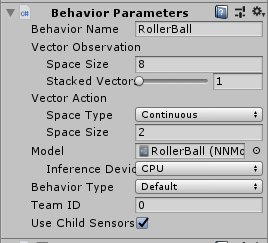
}四,代码部分已经完成,那么接下来先回到unity,我们需要在挂载AI脚本的GameObject上挂载 BehaviorParameters 脚本,搜索添加即可。然后按照如图所示配置
五,环境测试,可以重载Heuristic方法来实现手动控制,代码如下
public override float[] Heuristic()
{
var action = new float[2];
action[0] = Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}好了,现在我们已经完成基本代码配置,全部代码如下
using System.Collections.Generic;
using MLAgents;
using UnityEngine;
///
/// 个人AI训练测试1
///
public class RollerAgent : Agent {
Rigidbody rigidbody;
void Start () {
rigidbody = transform.GetComponent();
}
public Transform target;
///
///重构AI重置训练时的方法
///
public override void AgentReset()
{
//重置AI的位置和刚体的速度
if(transform.localPosition.y < 0)
{
rigidbody.angularVelocity = Vector3.zero;
rigidbody.velocity = Vector3.zero;
transform.localPosition = new Vector3(0f,0.5f,0f);
}
//随机设置AI目标的位置
target.localPosition = new Vector3(Random.value * 8 - 4,0.5f,Random.value * 8 -4);
}
///
/// 收集AI训练时的数据,用作训练参考的数据
///
public override void CollectObservations()
{
/*需收集以下参考量(基本)
1.目标的位置
2.自己的位置
3.自己的刚体的角速度和速度
*/
AddVectorObs(target.localPosition);
AddVectorObs(transform.localPosition);
AddVectorObs(rigidbody.velocity.x);
AddVectorObs(rigidbody.velocity.z);
}
//设置给AI完成目标时的奖励分配
public float speed = 10f;
public override void AgentAction(float[] vectorAction)
{
Vector3 controlSingal = Vector3.zero;
controlSingal.x = vectorAction[0];
controlSingal.z = vectorAction[1];
rigidbody.AddForce(controlSingal * speed);
//奖励
float distanceToTarget = Vector3.Distance(transform.localPosition,target.localPosition);
//到达目标
if(distanceToTarget < 1.42f)
{
//设置奖励,标记方法完成
SetReward(1.0f);
Done();
}
//自己落下平台,重置
if(transform.localPosition.y < 0)
{
Done();
}
}
// 手动操作方法
public override float[] Heuristic()
{
var action = new float[2];
action[0] = Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}
} 六,现在修改trainer_config.yaml配置文件里的训练的配置信息,你可以使用里面原有的配置,复制下来修改下就行,不过需要注意以下
用于训练的超参数在传递给mlagents-learn程序的配置文件中指定。使用原始ml-agents/config/trainer_config.yaml文件中指定的默认设置,RollerAgent大约需要进行300,000步训练。但是,您可以更改以下超参数以显着加快训练速度(达到20,000步以下):
batch_size:10
buffer_size:100
由于此示例创建了一个非常简单的训练环境,仅包含少量输入和输出,因此使用较小的批处理和缓冲区大小可大大加快训练速度。但是,如果您增加了环境的复杂性或更改了奖励或观察功能,则可能还会发现使用不同的超参数值可以更好地进行训练。
配置如下
RollerBallBrain:
normalize: true
batch_size: 10
buffer_size: 100现在在控制台里输入mlagents-learn trainer_config.yaml --run-id=RollerBall-1 --train,即可开始训练,看到控制台中的提示启动unity的Play按钮就可,当训练完成时,控制台中出现Saved Model的提示,表示模型训练完成,你按Ctrl + C就可以中断训练,模型保存在models文件下,把自己的模型拖入脚本中就可以看到训练的结果,如图

七.批量训练,先把前面的TrainingArea游戏物体拖成预制体,然后复制多个后,控制台输入训练命令后,再根据提示启动unity就行了。
好了,以上就是目前的进度,后面会训练更加复杂的AI,敬请期待!!!