PyTorch TripletMarginLoss(三元损失)
文章目录
- triplet loss
- triplet hard loss
triplet loss
官方文档:
torch.nn — PyTorch master documentation
关于三元损失,出自论文:
FaceNet: A Unified Embedding for Face Recognition and Clustering
FaceNet: A Unified Embedding for Face Recognition and Clustering(论文阅读笔记)
三元损失的介绍很多,本站上搜一下就可以找到,比如:
Triplet Loss 和 Center Loss详解和pytorch实现
Triplet-Loss原理及其实现、应用
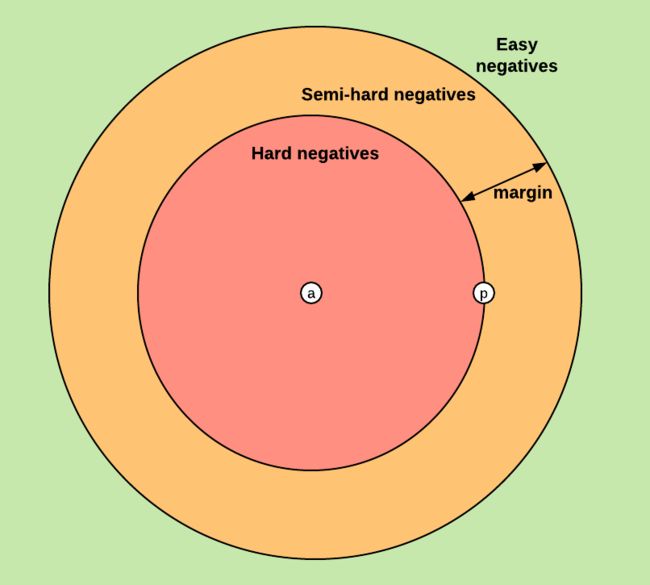
看下图:
- 训练集中随机选取一个样本:Anchor(a)
- 再随机选取一个和Anchor属于同一类的样本:Positive(p)
- 再随机选取一个和Anchor属于不同类的样本:Negative(n)
这样

学习目标是让Positive和Anchor之间的距离 D ( a , p ) D(a,p) D(a,p) 尽可能的小,Negative和Anchor之间的距离 D ( a , n ) D(a,n) D(a,n) 尽可能的大:
∥ f ( x i a ) − f ( x i p ) ∥ 2 2 + α < ∥ f ( x i a ) − f ( x i n ) ∥ 2 2 (1) \left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}+\alpha<\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} \tag{1} ∥f(xia)−f(xip)∥22+α<∥f(xia)−f(xin)∥22(1)
∀ ( f ( x i a ) , f ( x i p ) , f ( x i n ) ) ∈ T \forall\left(f\left(x_{i}^{a}\right), f\left(x_{i}^{p}\right), f\left(x_{i}^{n}\right)\right) \in \mathcal{T} ∀(f(xia),f(xip),f(xin))∈T
优化目标:
L = ∑ i N [ ∥ f ( x i a ) − f ( x i p ) ∥ 2 2 − ∥ f ( x i a ) − f ( x i n ) ∥ 2 2 + α ] + (2) L = \sum_{i}^{N}\left[\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}-\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2}+\alpha\right]_{+} \tag{2} L=i∑N[∥f(xia)−f(xip)∥22−∥f(xia)−f(xin)∥22+α]+(2)
距离用欧式距离度量, + + +表示[ ∗ ∗ ∗ *** ∗∗∗ ]内的值大于零的时候,取该值为损失值,而[ ∗ ∗ ∗ *** ∗∗∗ ]内的值小于零的时候,损失值则为零。也可以这么表示:
L = max ( D ( a , p ) − D ( a , n ) + α , 0 ) (3) L=\max (D(a, p)-D(a, n)+\alpha, 0) \tag{3} L=max(D(a,p)−D(a,n)+α,0)(3)
其中 α 迫使positive pairs (a, p) 和 negative pairs (a, n) 之间有一个margin(α)。 T \mathcal{T} T是训练集中所有可能的三元组的集合。
关于三元组,可以分为:
easy triplets: L = 0 L = 0 L=0 的情况(不产生loss), D ( a , p ) + α < D ( a , n ) D(a, p)+\alphahard triplets: D ( a , n ) < D ( a , p ) D(a, n)semi-hard triplets: D ( a , p ) < D ( a , n ) < D ( a , p ) + α D(a, p)margin(α),比较容易优化。
更多内容可以看这儿Triplet-Loss原理及其实现、应用
PyTorch中的Triplet-Loss接口:
CLASS torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None,
reduce=None, reduction='mean')
参数:
margin(float) – 默认为1p(int) – norm degree,默认为2swap(bool) – The distance swap is described in detail in the paperLearning shallow convolutional feature descriptors with triplet lossesby V. Balntas, E. Riba et al. 默认为Falsesize_average(bool) – Deprecatedreduce(bool) – Deprecatedreduction(string) – 指定返回各损失值(none),批损失均值(mean),批损失和(sum),默认返回批损失均值(mean)
使用示例:
输入tensor的尺寸:(N, D),N为批量大小,D为张量维度
输出:为标量, 如果reduction为 ‘none’,则shape为(N),即N个标量;否则为1个标量
anchor = torch.randn(20, 20, requires_grad=True)
positive = torch.randn(20, 20, requires_grad=True)
negative = torch.randn(20, 20, requires_grad=True)
torch.nn.functional.triplet_margin_loss(anchor, positive, negative,reduction='none')
>>>
tensor([1.0158, 0.0975, 2.1613, 1.4658, 0.7332, 1.5604, 1.0034, 0.3777, 0.1616,
0.7618, 0.9989, 0.0000, 3.4407, 1.0938, 0.3333, 0.0000, 0.0000, 0.4422,
1.1857, 1.7083], grad_fn=)
torch.nn.functional.triplet_margin_loss(anchor, positive, negative,reduction='mean')
>>>
tensor(0.9271, grad_fn=)
# 官方例子
triplet_loss = torch.nn.TripletMarginLoss(margin=1.0, p=2)
anchor = torch.randn(20, 20, requires_grad=True)
positive = torch.randn(20, 20, requires_grad=True)
negative = torch.randn(20, 20, requires_grad=True)
output = triplet_loss(anchor, positive, negative)
output.backward()
triplet hard loss
我们再回过头来看(1)式的优化函数:
∥ f ( x i a ) − f ( x i p ) ∥ 2 2 + α < ∥ f ( x i a ) − f ( x i n ) ∥ 2 2 \left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}+\alpha<\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} ∥f(xia)−f(xip)∥22+α<∥f(xia)−f(xin)∥22
∀ ( f ( x i a ) , f ( x i p ) , f ( x i n ) ) ∈ T \forall\left(f\left(x_{i}^{a}\right), f\left(x_{i}^{p}\right), f\left(x_{i}^{n}\right)\right) \in \mathcal{T} ∀(f(xia),f(xip),f(xin))∈T
这个约束条件需要在所有的三元组上面都成立,但是如果严格按照这个约束,那么三元组集合 T \mathcal{T} T可能会相当大,需要穷举所有的三元组:
【深度学习论文笔记】FaceNet: A Unified Embedding for Face Recognition and Clustering
在1000个人,每人有20张图片的情况下, T = 1000 ∗ 20 ∗ 20 ∗ 999 \mathcal{T} = 1000*20*20*999 T=1000∗20∗20∗999,也即 O ( T ) = N 2 O(T) = N^2 O(T)=N2,显然穷举不太现实,所以常用的办法就是选取部分进行训练,也就是选取困难样本对(hard triplets)进行训练。
(可以这么想, T \mathcal{T} T包含许多easy triplets(满足(1)式的约束),这些easy triplets对训练helpless,而且会使收敛更慢,因为它们仍然需要前向计算。所以需要选择hard triplets)
那么hard triplets怎么选?
给定一张人脸图片(Anchor):
- 挑选一个hard positive:另外19张图像中,跟它最不相似的图片
argmax x i p ∥ f ( x i a ) − f ( x i p ) ∥ 2 2 \operatorname{argmax}_{x_{i}^{p}}\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2} argmaxxip∥f(xia)−f(xip)∥22 - 挑选一个hard negative:另外20*999张图像中,跟它最为相似的图片
argmin x i n ∥ f ( x i a ) − f ( x i n ) ∥ 2 2 \operatorname{argmin}_{x_{i}^{n}}\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} argminxin∥f(xia)−f(xin)∥22
而挑选方法也有两种:offline和online
这儿介绍实际采用的online方法:通过在一个mini-batch中选择hard positive/negative 样本来实现。具体的解释可以参照论文以及参考文档。
下面贴一个PyTorch的triplet hard loss实现():
关于代码的解析可以看pytorch triphard代码理解
class TripletLoss(nn.Module):
"""Triplet loss with hard positive/negative mining.
Reference:
Hermans et al. In Defense of the Triplet Loss for Person Re-Identification. arXiv:1703.07737.
Imported from ``_.
Args:
margin (float, optional): margin for triplet. Default is 0.3.
"""
def __init__(self, margin=0.3,global_feat, labels):
super(TripletLoss, self).__init__()
self.margin = margin
self.ranking_loss = nn.MarginRankingLoss(margin=margin)
def forward(self, inputs, targets):
"""
Args:
inputs (torch.Tensor): feature matrix with shape (batch_size, feat_dim).
targets (torch.LongTensor): ground truth labels with shape (num_classes).
"""
n = inputs.size(0) # batch_size
# Compute pairwise distance, replace by the official when merged
dist = torch.pow(inputs, 2).sum(dim=1, keepdim=True).expand(n, n)
dist = dist + dist.t()
dist.addmm_(1, -2, inputs, inputs.t())
dist = dist.clamp(min=1e-12).sqrt() # for numerical stability
# For each anchor, find the hardest positive and negative
mask = targets.expand(n, n).eq(targets.expand(n, n).t())
dist_ap, dist_an = [], []
for i in range(n):
dist_ap.append(dist[i][mask[i]].max().unsqueeze(0))
dist_an.append(dist[i][mask[i] == 0].min().unsqueeze(0))
dist_ap = torch.cat(dist_ap)
dist_an = torch.cat(dist_an)
# Compute ranking hinge loss
y = torch.ones_like(dist_an)
loss = self.ranking_loss(dist_an, dist_ap, y)
return loss