前言
此为本人学习《百面机器学习——算法工程师带你去面试》的学习笔记
第一章 特征工程
特征工程,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据的杂质和冗余,设计更高效的特征以刻画求解的问题和预测模型之间的关系。
两种常用的数据类型
1、结构化数据。可以看做关系型数据库的一张表,每列都有清晰的定义,包含了数值型、类别型两种基本类型,每一行数据表示一个样本的信息。
2、非结构化数据。主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
01 特征归一化
1、目的:消除数据特征之间的量纲影响,使得不同指标之间具有可比性
2、常用的两种归一化方法
a. 线性函数归一化(Min-Max Scaling)。对原始数据映射到[0, 1]的范围。
b. 零均值归一化(Z-Score Normalization)。将原始数据映射到均值为0、标准差为1的分布上。
3、在使用梯度下降进行求解的过程中,数据归一化主要对梯度下降收敛速度产生的影响,将各个特征映射到同一区间内,使得各个特征的更新速度一样,可以更快地通过梯度下降找到最优解
4、实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型并不适用,如C4.5在结点分裂时主要依据数据集D光宇特征x的信息增益比,而信息增益比和特征是否归一化无关。
02 类别型特征
1、类别型特征指的是例如性别(男、女)等只在有限选项内取值的特征。通常是字符串形式,除了决策树等少数模型可以直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型,类别型特征必须转换为数值型特征才能正确工作。
2、处理类别型特征方法:
a. 序号编码:通常用于处理类别间具有大小关系的数据。如成绩可分为低、中、高三挡,分别用1、2、3表示,转换后依然保留大小关系
b. 独热编码:通常用于处理类别间不具有大小关系的特征。如血型,一共有4个取值(A型 B型 AB型 O型),one-hot编码会将其变成一个4位的稀疏向量,A型(1,0,0,0) B型(0,1,0,0)...
one-hot编码注意点:当类别取值较多时,用one-hot就会非常稀疏,可以使用稀疏向量节省空间。高维度特征会带来几方面的问题,(1)k近邻算法中,高维空间下两点之间的距离很难得到有效的衡量.(2)逻辑回归中参数的数量会随维度的增高而增高,容易引起过拟合问题。(3) 通常只有部分维度对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。
c. 二进制编码:和one-hot编码思想类似,本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且比one-hot编码节省空间。
03 高维组合特征的处理
1、目的:提高复杂关系的拟合能力。
2、高阶组合特征是指把一阶离散特征两两组合,构成高阶特和特征。
例如将语言(中文、英文);剧集类型(电影、电视剧)两个一阶离散特征组合为二阶特征,则有中文电影、中文电视剧、英文电影、英文电视剧四种类型。假设数据的特征向量X = (x1, x2, x3 ,..., xk),则有
则w的维度是2X2=4
3、当引入ID类型的特征时,通常需要降维。如推荐问题,通常有如下特征:
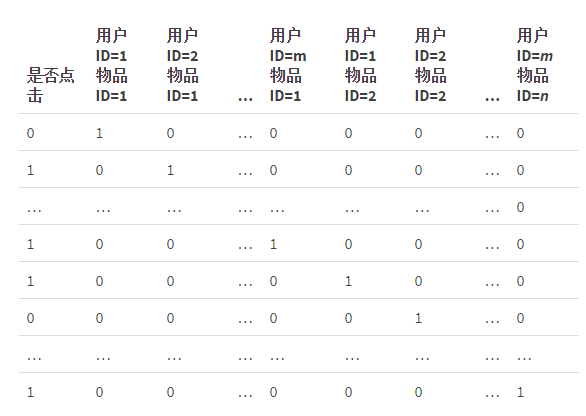
如上表所示,则要学习的参数规模使m x n,参数规模太大,一种行之有效的方法是经用户和物品分别用k维的低维向量表示(k远小于m和n),则参数的规模变为m x k+n x k。实际是矩阵分解
04 组合特征
实际问题中,简单的两两组合容易存在参数过多、过拟合等问题。本节提供一种基于决策树的特征组合寻找方法。
以点击预测为例,假设原始输入特征包含年龄、性别、用户类型(试用期、付费)、物品类型(护肤、食品等)4个方面的信息,并且根据原始输入和标签(点击/未点击)构造了决策树,如图1.2
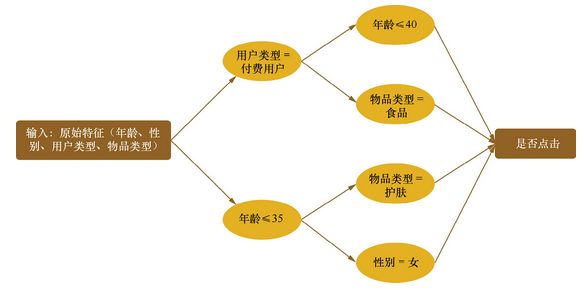
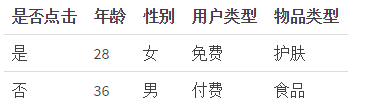
每一条从根节点到叶节点的路径都可以看成一种特征组合的方式。根据上述决策树可有4条路径,针对表1.2 可得到以下组合方式,第一个样本的组合特征可以编码为(1, 1, 0, 0),第二个为(0, 0, 1, 1)
05 文本表示模型
1、词袋模型和N-gram模型
词袋模型是最基础的文本表示模型。将每篇文章看成一袋子词,忽略每个次出现的顺序。具体来说,就是将整段文本以词为单位切分开,每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重反映了这个词在原文章的重要程度。常用 TF-IDF 来计算权重,公式为
TF-IDF(t,d)=TF(t,d)×IDF(t) ;
TF(t,d) 为单词 t 在文档 d 中出现的频率,IDF(t) 是逆文档频率,用来衡量单词 t 对表达语义所起的重要性,表示为
(1.6)
N-gram模型是指某些单词组不能拆开,可以将连续出现的n个词组成词组(N-gram)作为一个单独的特征放入向量表示,构成N-gram模型
注意:同一个词可能有多种词性变化,却具有相似的含义。在实际应用中,一般会对单词进行词干抽取(Word Stemming)处理,即将不同词性的单词统一成为同一词干的形式。
2、主题模型
词袋模型和N-gram模型无法识别两个不同的词或词组具有相同的主题,主题模型可以将具有相同主题的词或词组映射到同一维度上,映射到的这一维度表示某个主题。主题模型是一种特殊的概率图模型,后面第六章第五节会讲。
3、词嵌入
词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间(通常 K=50~300 维)上的一个稠密向量(Dense Vector)。K 维空间的每一维也可以看作一个隐含的主题,只不过不像主题模型中的主题那样直观。
06 Word2Vec
1、谷歌 2013 年提出的 Word2Vec 是目前最常用的词嵌入模型之一。Word2Vec 实际是一种浅层的神经网络模型,它有两种网络结构,分别是 CBOW(Continues Bag of Words)和 Skip-gram。CBOW 的目标是根据上下文出现的词语来预测当前词的生成概率, Skip-gram 是根据当前词来预测上下文中各词的生成概率。网络结构如下:

其中 w(t) 是当前所关注的词,w(t−2)、w(t−1)、w(t+1)、w(t+2) 是上下文中出现的词。这里前后滑动窗口大小均设为 2。
2、CBOW和Skip-gram均可表示成由 输入层、映射层和输出层组成的神经网络
输入层由one-hot编码表示,即当词汇表中的单词总数是N,则输入层的one-hot编码维度也是N
映射层(隐藏层)中有K个隐藏单元,其取值由N为输入向量以及连接输入和隐藏单元之间的NxK维权重矩阵计算得到。
注意:CBOW中还需要将各个输入词所计算出的隐含单元求和
输出层向量的值可以通过隐藏层向量(K维),以及隐藏层和输出层之间的KxN维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的一个单词对应。但是这里的输出量并不能保证所有维度加起来为1(one-hot编码加起来就为1),要通过Softmax激活函数归一化。Softmax激活函数的定义为
(1.7)
训练目标是使得语料库中所有单词的整体生成概率最大化。学习权重可以用反向传播算法实现,每次迭代时将权重沿梯度方向进一步更新。但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要需要对词汇表中所有单词进行遍历,使得每次迭代过程非常缓慢,可使用 Hierarchical Softmax 和 Negative Sampling 两种方法改进。
得到训练出来的歌词对应的向量:训练得到维度为NxK和KxN的两个权重矩阵,可以选择其中任意一个作为N个词的K维向量表示
3、Word2Vec和LDA的区别和联系
LDA利用文档中单词的共现关系对单词按主题聚类,可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。但Word2Vec其实是对“上下文-单词”矩阵进行学习,其中上下文由周围的几个单词组成,更多的融入了上下文共现特性。
主题模型通过一定的结构调整可以基于“上下文-单词”矩阵进行主题推理。词嵌入方法也可以根据“文档-单词”矩阵学习出词的隐含向量表示。
主题模型和词嵌入两类方法的最大不同在于模型本身。主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘,其中包括需要推测的隐含变量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
07 图像数据不足时的处理方式
1、一个模型的信息来源一般来自两个方面:一是训练数据中蕴含的信息;二是在模型的形成过程中(包括构造、学习、推理等),人们提供的先验信息。
2、训练数据不足时,为了保证模型效果则需要更多先验信息。先验信息可以作用在模型上,如让模型采用特定的内在结构、条件假设或添加其他一些约束条件;先验信息也可以直接作用在数据集上,即更具特定的先验假设去调整、变换或扩展训练数据,让其展现更多的、更有用的信息。
3、图像分类任务中,驯良数据不足带来的问题主要表现在过拟合方面,即模型在训练样本上的效果可能不错,但是在测试集上的泛化效果不佳。对应的处理方法大致可分为两类:
基于模型的方法,主要采用降低过拟合风险的措施,包括简化模型(如将非线性模型假话为线性模型)、添加约束项以缩小假设空间(如L1/L2正则)、集成学习、Droupout超参数等
基于数据的方法,主要通过数据扩充(Data Augmentation),即根据一些先验知识,在保持特定信息的前提下,对原始数据进行适当变换以达到扩充数据集的效果
具体到图像分类任务中,在保持图像类别不变的前提下,可以对训练集中每幅图像进行以下变换 (1) 随机旋转、平移、缩放、裁剪、填充、左右翻转等,对应着同一个目标在不同角度的观察结果;(2) 对图像中的像素添加噪声扰动,比如椒盐噪声、高斯白噪声等;(3) 颜色变换;(4) 改变图像的亮度、其吸毒、对比度、锐度等。

4、除了之间在图像空间进行变换,还可以对图像进行特征提取,然后在图像的特征空间内进行变换,利用一些通用的数据扩充或上采样技术,如SMOTE(Synthetic Minority Over-sampling Technique)之类的启发式的变换方法。此外还可以通过如GAN等生成模型合成新样本,或者借助已有的其他模型或数据进行迁移学习。
例如,对于大部分图像分类任务,并不需要从头开始训练模型,而是借用一个在大规模数据集上预训练好的通用模型,并在针对目标任务的小数据集上进行微调(fine-tune),这种微调操作就可以看成是一种简单的迁移学习。