正式部署前请详细阅读基础环境这三篇,非常重要!!!
硬件环境详解
操作系统环境详解
软件环境详解
一、安装前的准备
请参考第三章的基本环境注意事项,准备基础环境,这个很重要
二、软件下载
1.请从HDP官方下载 HDP与HDP-UTILS
http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.5.0.0/HDP-2.5.0.0-centos6-rpm.tar.gz
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos6/HDP-UTILS-1.1.0.21-centos6.tar.gz
http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.4.1.0/ambari-2.4.1.0-centos6.tar.gz
2.请准备好系统安装盘.iso文件或者系统yum源
配置示例
mkdir -p /opt/ydbsoftware/centosyum
mount -o loop /opt/ydbsoftware/CentOS-6.6-x86_64-bin-DVD1.iso /opt/ydbsoftware/centosyum
3.从http://ycloud.net.cn/download获取延云软件
1)下载延云YDB
2)延云YDB提供的Spark (注意不要使用HDP提供的spark)
3)JDK1.8

三、软件上传
1.JDK安装
将安装包中的JDK安装到/opt/ydbsoftware/jdk1.8.0_60
分发到每台机器上,且路径统一为
/opt/ydbsoftware/jdk1.8.0_60
2.选定一台机器安装YDB的机器,上传软件
将全部软件上传到/opt/ydbsoftware目录下,并解压,注意是/opt/ydbsoftware,千万别写错了,且不能随意更改路径。
3.配置HTTP服务(在解压后的目录执行)
cd /opt/ydbsoftware
nohup python -m SimpleHTTPServer &
4.YUM源配置
1)备份旧的YUM源
cd /etc/yum.repos.d
mkdir -p bak
mv *.repo bak/
2)配置ambari源与本地系统源
每台机器都要配置
ambari.repo文件名不得更改
本地系统源很重要,一定要配置
配置示例如下
cat << EOF >/etc/yum.repos.d/ambari.repo
[centoslocal]
name=centoslocal
baseurl=http://ydbmaster:8000/centosyum
gpgcheck=0
[AMBARI]
name=AMBARI
baseurl=http://ydbmaster:8000/AMBARI-2.4.1.0/centos6/2.4.1.0-22
gpgcheck=0
[HDP]
name=HDP
baseurl=http://ydbmaster:8000/HDP/centos6
gpgcheck=0
[HDP-UTILS]
name=HDP-UTILS
baseurl=http://ydbmaster:8000/HDP-UTILS-1.1.0.21/repos/centos6
gpgcheck=0
EOF
5.安装与配置ambari-server(只需要在一台机器安装)
yum clean all
yum makecache
yum repolist
yum install ambari-server
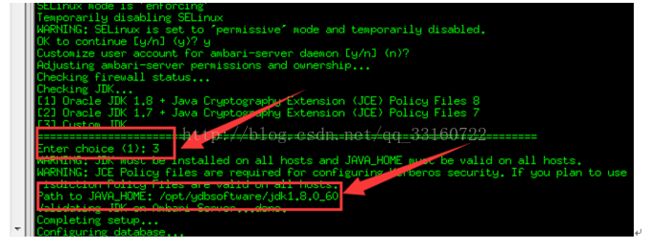
6.设置ambari
ambari-server setup
中间除jdk单独指定外,都默认
7.启动ambari-server
ambari-server start
然后就可以打开 http://xx.xx.xx.xx:8080 安装hadoop了 默认用户名与密码均为 admin
四、HDP页面设置
1.开始创建集群
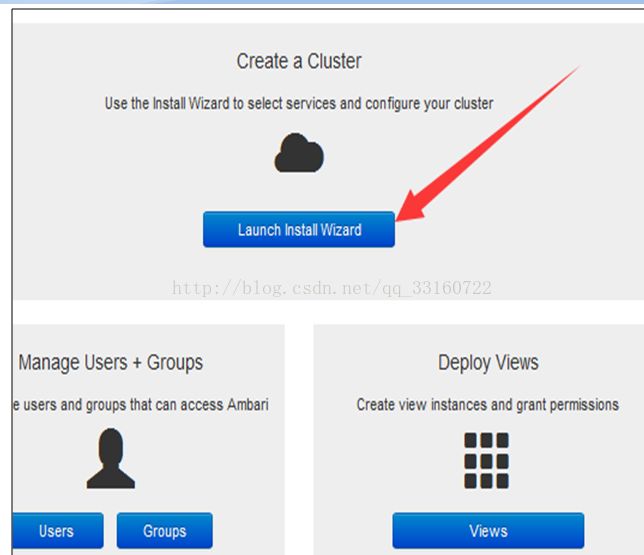

2.配置HDP源
选择Hdp版本为hdp2.5
 、
、

3.部署的机器列表与登录私钥配置

4.部署Ambari-Agent
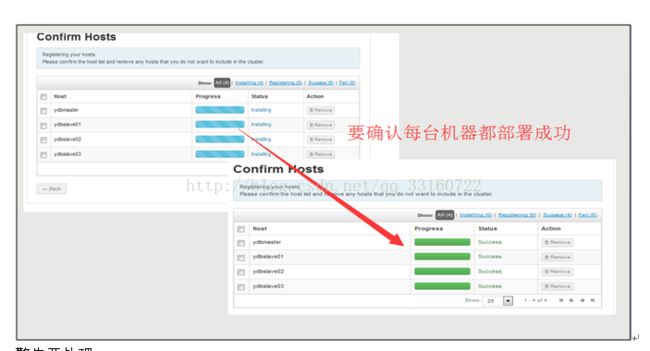
警告要处理

5.选择安装部署服务
切记,不需要选择Hive与Spark

6.服务分配


7.HDFS配置



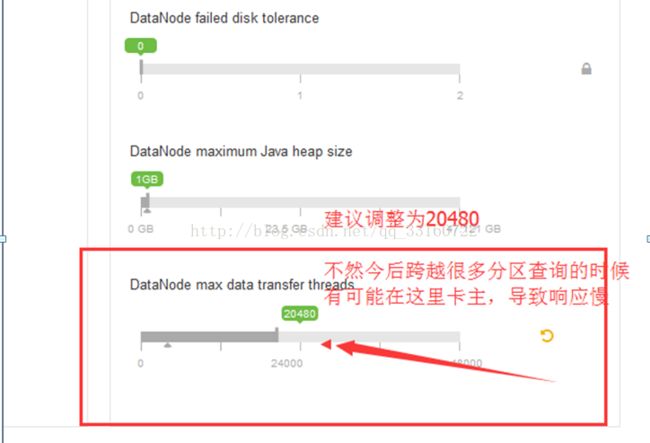

8.YARN配置

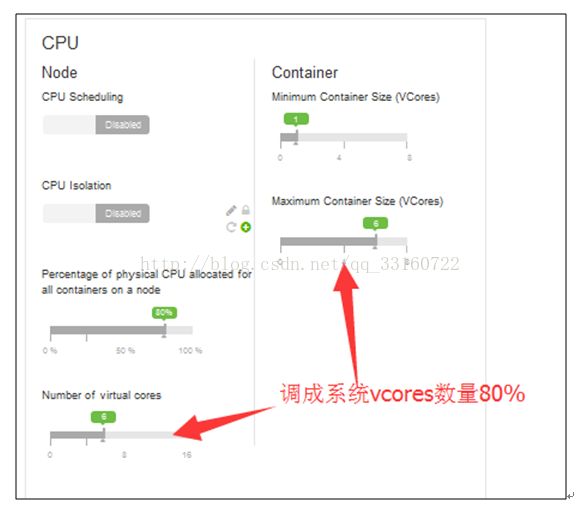



9.MapReduce配置

10.ZooKeeper配置

11.AmbariMetrics配置

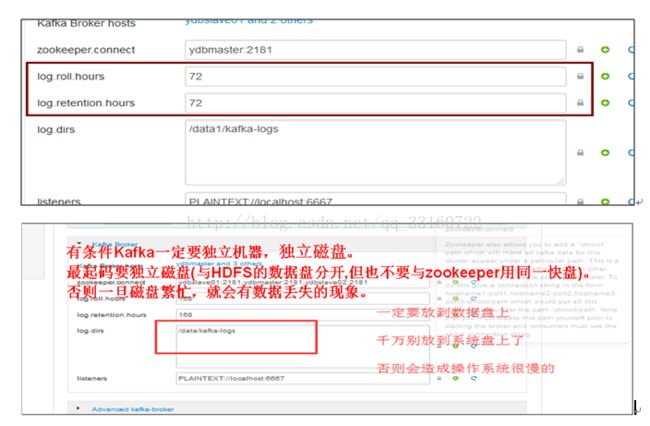
12.KAFKA配置


13.HDP部署完成

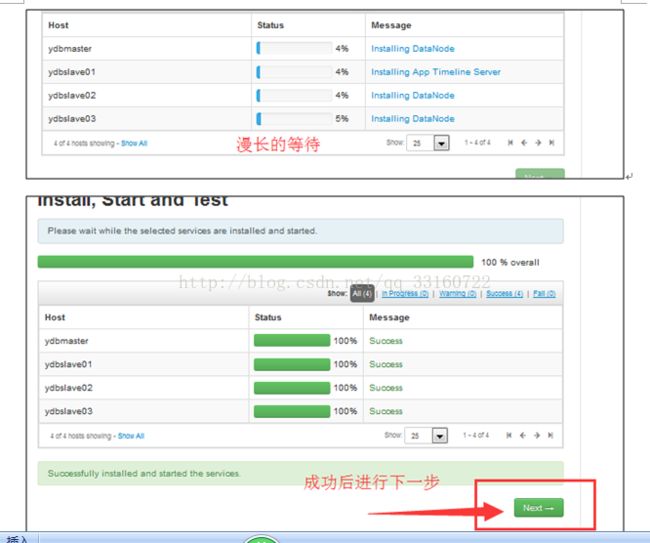

五、部署YDB
1.软件解压
解压开随机附带的spark1.6.3_hadoop2.7.3.tar.gz,里面是我们改过bug的Spark
解压开随机附带的ya100.1.x.x.zip,里面是YDB
解压后一定要放在/opt/ydbsoftware目录下
2.注意观察,如下三个目录是否存在
/opt/ydbsoftware/spark1.6.3_hadoop2.7.3
/opt/ydbsoftware/jdk1.8.0_60
/opt/ydbsoftware/ya100/bin
3.安装ydb
ln -s /opt/ydbsoftware/spark1.6.3_hadoop2.7.3 /opt/ydbsoftware/spark
cd /opt/ydbsoftware/ya100/bin
sh ./hdp_install.sh
4.YDB的ambari配置
1)添加服务



2)A组配置:基本配置

3)B组配置:环境路径配置

4)C组配置:存储相关路径配置

5)D组配置:Kafka相关配置

6)开始安装

7)安装完毕

8)服务检查
如果服务异常,可以看这个日志
tail -f /opt/ydbsoftware/ya100/logs/ya100.log 看是否有报错,当出现如下的日志,表示启动成功
打开yarn的8088页面,看启动的container数量以及内存的时候是否正确

UI监控

YDB的监控UI
1.可以查看每台机器的负载、处理数据、内存等情况。
2.可以了解每个表的运行情况,每个分区的数据条数,数据量大小。
默认启动的端口号为1210,如果在 ydb_site.yaml里配置了ydb.httpserver.port,则以配置的端口号为准。

了解延云ya100、ydb的用法、进行测试、生成演示demo
通过随机附带示例了解用法
打开ya100/example目录
第一: ydb_example.sql
包含了YDB的表的创建,ya100与YDB表的连接,查询的使用,数据的导入等
第二:如何通过kafka实时导入数据.txt
阐述了YDB如何通过Kafka实时的进行数据导入
第三:”演示demo搭建.txt”
如何快速的使用YDB生成延云官方提供的演示demo
基本的监控页面

YDB的Spark UI
在spark ui里可以看到 每个用户查询SQL的执行进度,响应时间等,也可以杀掉有异常的一些任务。
进入方法如下
1.首先打开您的yarn调度页面(默认端口是8088端口),并在里面找到ya100 on spark的任务,如下图所示

2.点击Application Master进入
如果点击后,发现域名解析不了,请在您机器本地配置好相关host,或者直接改成对应的IP。
3.点开后会看到如下的页面
