基于Scrapy的爬虫爬取京东商品信息与评论
从京东搜索框搜索进入手机进入页面,爬取内容分成两类,一类是手机的基本信息(标题、价格、链接),另一类是评论信息(用户名、评论内容、评论总数等),将信息爬取下来之后,进行数据处理,以方便显示和查看的格式保存下来。
(1)爬虫
爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,是一种按照一定的规则自动地抓取万维网信息的程序或者脚本,它的原理简单来讲就是通过选定入口URL,模拟HTTP请求,找到页面上想要获取的数据,然后保存下来。
(2)Scrapy框架
Scrapy是Python开发的一个快速、高层次的屏幕抓取和WEB抓取框架,用于抓取web站点并从页面中提取结构化数据。用途比较广泛,可用于数据挖掘、监测和自动化测试。
Scrapy是一个自定义程度很高的框架,任何人都可以根据自己的需求很方便填写或者重写里边的函数。它页提供了多种类型的爬虫基类。
(3)XPath
XPath即为XML路径语言,是一种用来确定文档中某部分位置的语言,XPath基于XML的树状结构,提供在数据结构中寻找节点的能力,也可用于HTML页面。
通过浏览器查看页面源码,找到我们想要的信息的节点位置,然后通过XPath的路径表达式,对节点进行遍历,从而获得数据。
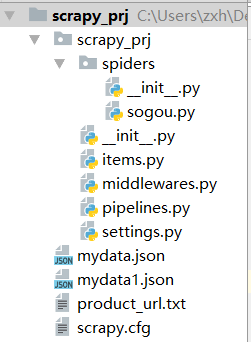
工程文件结构
通过命令行创建一个Scrapy工程文件,文件结构如下图,在这个项目中,主要编写items.py、pipelines.py、setting.py以及sogou.py(爬虫文件)这四个文件。并将手机基本信息储存在mydata.json文件中,评论信息储存在mydata1.json文件中,product_url.txt储存每个商品的链接,这个文件的主要作用是抓取评论时方便读取每个商品额url。
①items.py
因为写了两个爬虫,一个爬取手机信息,一个爬取评论信息,所以我们定义了两个类JdphoneItem和CommentItem
import scrapy
class JdPhoneItem(scrapy.Item):
url = scrapy.Field() #商品链接
title = scrapy.Field() #商品标题
price = scrapy.Field() # 商品价格
class CommentItem(scrapy.Item):
user_name = scrapy.Field() # 用户名
comment_num = scrapy.Field #评论总数
content = scrapy.Field() # 评论内容
phone_name = scrapy.Field() #手机名称②sogou.py
首先,获取入口链接,由于搜索页面的翻页规则是page=1开始,1,3,5,7…..这样以奇数递增,所以用一个循环将前十页加入入口链接。
![]()
![]()
![]()
然后在解析函数里通过XPath表达式爬取信息,并将手机URL单独存一份,方便后续读取。
得到每个手机的URL之后,从URL中提取商品ID,抓取评论总数,然后求出评论页数,然后构造评论页链接,链接的基本结构是前缀+商品ID+评论页序号+后缀,然后加入到入口链接。然后通过Xpath表达式爬取。
# coding: utf-8
import scrapy
from scrapy_prj.items import JdPhoneItem
from scrapy_prj.items import CommentItem
import re
import urllib.request
class PhoneSpider(scrapy.Spider):
name = "jd"
allowed_domains = ["jd.com"]
start_urls = []
#获取前十页的链接
for i in range(1, 11):
url = "https://search.jd.com/Search?keyword=手机&enc=utf-8&page=" + str(2 * i - 1)
start_urls.append(url)
#获取商品的链接,标题,价格
def parse(self, response):
item = JdPhoneItem()
# 获取标题
item["title"]=response.xpath("//div[@class='p-name p-name-type-2']/a[@target='_blank']/@title").extract()
#得到价格
item["price"] = response.xpath("//div[@class='p-price']/strong/@data-price").extract()
#得到链接
item["url"] = response.xpath('//div[@class="p-name p-name-type-2"]/a[@target="_blank"]/@href').extract()
#将链接存入txt文件中,方便抓取评论,
for i in range(0,len(item["url"])):
#过滤无用链接
pattern = 'https'
bool=re.match(pattern, item["url"][i])
if (bool):
continue
else:
with open('product_url.txt', 'a') as f:
f.write(item["url"][i]+'\n')
return item
class CommentSpider(scrapy.Spider):
name = "comment"
#打开存放链接得txt文件
links = open("product_url.txt")
link = links.readlines()
#从商品链接中提取商品id,并构造评论页url
for i in range(1,2):
pattern = r'(\d+)\.html$'
#这里我们读取的评论是单个手机的评论
#可以改变link[]的下标索引来读取不同的手机的评论
id = re.findall(pattern, link[0])
# 得到评论数
commentUrl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds=" + str(id[0])
commentData = urllib.request.urlopen(commentUrl).read().decode("utf-8", "ignore")
patt1 = r'"CommentCount":(\d+),'
comment_num = re.findall(patt1, commentData)
#得到评论页数
if int(comment_num[0]) % 30 == 0:
comment_page_num= int(int(comment_num[0])/30)
else :
comment_page_num = int(int(comment_num[0])/30)+1
start_urls = []
for i in range(1,comment_page_num+1):
url = "http://club.jd.com/review/" + str(id[0]) + "-1-"+str(i)+"-0.html"
start_urls.append(url)
def parse(self, response):
item = CommentItem()
#用户名
item["user_name"] = response.xpath("//div[@class='i-item']/@data-nickname").extract()
#评论内容
item["content"] = response.xpath("//div[@class='comment-content']/dl/dd/text()").extract()
#手机名称
item["phone_name"] = response.xpath("//div[@class='mc']/ul/li[@class='p-name']/a/text()").extract()
return item① pipelines.py
将数据爬取下来之后,在这里进行筛选、过滤、储存。将第j个商品的标题、价格、链接拿出来重新组合成一个字典,再将字典写入JSON文件中,这样一行显示一个商品的信息,并且是一一对应的。
import codecs
import json
import re
class JdphonePipeline(object):
def __init__(self):
#以写入的方式创建或者打开一个文件
self.file = codecs.open("mydata.json","wb",encoding="utf-8")
def process_item(self,item,spider):
for j in range(0,len(item["price"])):
price=item["price"][j]
pattern = 'https'
bool = re.match(pattern, item["url"][j])
if (bool):
continue
else:
url=item["url"][j]
name=item["title"][j]
goods={"price":price,"name":name,"url":url}
i=json.dumps(dict(goods),ensure_ascii=False)
line=i+'\n'
self.file.write(line)
return item
def close_spider(self,spider):
self.file.close()
class CommentPipeline(object):
def __init__(self):
self.file = codecs.open("mydata1.json","wb",encoding="utf-8")
def process_item(self, item, spider):
count = 0
# 去掉换行符与回车符
for i in range(0, len(item["content"])):
pattern = re.match('(\r\n)+', item["content"][i])
if (not pattern):
item["content"][count] = item["content"][i]
count += 1
else:
continue
for j in range(0, len(item["user_name"])):
user_name = item["user_name"][j]
content = item["content"][j]
phone_name = item["phone_name"][int(j/30)]
goods1 = {"phone":phone_name,"user_name": user_name, "content": content}
i = json.dumps(dict(goods1), ensure_ascii=False)
line = i + '\n'
self.file.write(line)
return item
def close_spider(self, spider):
self.file.close()① setting.py
爬虫的相关设置
BOT_NAME = 'scrapy_prj'
SPIDER_MODULES = ['scrapy_prj.spiders']
NEWSPIDER_MODULE = 'scrapy_prj.spiders'
ITEM_PIPELINES = {
#爬手机信息时,用手机通道,将评论通道注释
#爬评论信息时,用评论通道,将手机通道注释
#'scrapy_prj.pipelines.JdphonePipeline': 300,#手机通道
'scrapy_prj.pipelines.CommentPipeline': 300,#评论通道
}
#关闭cookie信息
COOKIES_ENABLED = False
#不遵循爬虫协议
ROBOTSTXT_OBEY =False
#下载延迟
DOWNLOAD_DELAY = 0.5