论文笔记--deeplabv3--Rethinking Atrous Convolution for Semantic Image Segmentation
论文笔记–deeplabv3–Rethinking Atrous Convolution for Semantic Image Segmentation
文章地址:https://arxiv.org/abs/1706.05587
项目地址:https://github.com/NanqingD/DeepLabV3-Tensorflow
本篇文章作为使用空洞卷积解决语义分割全局context信息与局部spatial信息矛盾的经典,提出Atrous Spatial Pyramid Pooling兼顾局部特征与global context,相较于之前的deeplab(v1、v2),deeplabv3不使用DenseCRF作为后处理操作。
主要贡献:
1、本文重新讨论了空洞卷积的使用,这让我们在级联模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息。
2、改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,我们尝试以级联或并行的方式布局模块。
3、讨论了一个重要问题:使用大采样率的3×3的空洞卷积,因为图像边界响应无法捕捉远距离信息,会退化为1×1的卷积, 我们建议将图像级特征融合到ASPP模块中。
4、阐述了训练细节并分享了训练经验,论文提出的"DeepLabv3"改进了以前的工作,获得了很好的结果
Abstract
In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter’s field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentation. To handle the problem of segmenting objects at multiple scales, we design modules which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. Furthermore, we propose to augment our previously proposed Atrous Spatial Pyramid Pooling module, which probes convolutional features at multiple scales, with image-level features encoding global context and further boost performance. We also elaborate on implementation details and share our experience on training our system. The proposed ‘DeepLabv3’ system significantly improves over our previous DeepLab versions without DenseCRF post-processing and attains comparable performance with other state-of-art models on the PASCAL VOC 2012 semantic image segmentation benchmark.
首先用很简短却精炼的表述描述了暗黑卷积(就是空洞卷积)的功能:在控制特征分辨率的同时调整滤波器的感受野(adjust filter’s field-of-view as well as control the resolution of feature)。
然后讲到文章工作,即提出一个级联、平行的暗黑卷积去捕捉多尺度的context信息通过使用多个atrous rates,这一结构被设计为Atrous Spatial Pyramid Pooling模型。摘要中提出,文章详细写到实施细则,并且DeepLabv3在PASCAL VOC 2012数据集上有着非常不错的表现。
Introduction
深度卷积神经网络的两个挑战:
1、由于连续的池运算或卷积步长导致输出特征图分辨率降低,这使得DCNN能够学习到更多抽象的特征,并且具有更大的感受野,然而,这种对局部图像变换的不变性可能会阻碍需要详细空间信息的密集预测任务,即导致空间细节信息的丢失;
解决办法:暗黑卷积
 2、图像中存在多尺度的目标物体
2、图像中存在多尺度的目标物体

四种解决办法:
1)图像金字塔:输入不同尺度的图像,使得不同特征图对多尺度目标有更大的相应;
2)编解码结构:从编码部分提取不同尺度特征,然后在解码部分恢复分辨率;
3)级联空洞卷积
4)空间金字塔池化:特征图应用不同的rates进行空洞卷积,得到不同感受野,因而捕捉到不同尺度的目标物体
Method
使用Atrous Convolution使网络更深且保持小的output_stride,即保持特征图分辨率


对于在DeepLabv2中提出的ASPP模块,其在特征顶部映射图并行使用了四种不同采样率的空洞卷积。这表明以不同尺度采样是有效的,我们在DeepLabv3中向ASPP中添加了BN层。不同采样率的空洞卷积可以有效的捕获多尺度信息,但是,发现随着rate的增加,有效的卷积核参数下降了,即3x3的卷积退化为1x1的卷积,只有中心的权重有效。为此,采用了全局平均 池化,在最后的特征图上,并采用1x1卷积和双线性插值保留空间维度(得到下图中的b),所有filter的个数都是256。
 Deeplabv3 把在 ImagNet 上预训练得到的 ResNet 作为它的主要特征提取网络。但是,它为多尺度的特征学习添加了一个新的残差块。最后一个 ResNet 块使用了空洞卷积(atrous convolution),而不是常规的卷积。此外,这个残差块内的每个卷积都使用了不同的扩张率来捕捉多尺度的语境信息。
Deeplabv3 把在 ImagNet 上预训练得到的 ResNet 作为它的主要特征提取网络。但是,它为多尺度的特征学习添加了一个新的残差块。最后一个 ResNet 块使用了空洞卷积(atrous convolution),而不是常规的卷积。此外,这个残差块内的每个卷积都使用了不同的扩张率来捕捉多尺度的语境信息。
另外,这个残差块的顶部使用了空洞空间金字塔池化 (ASPP,Atrous Spatial Pyramid Pooling)。ASPP 使用了不同扩张率的卷积来对任意尺度的区域进行分类。
Experimental Evaluation
 (转自https://blog.csdn.net/u011974639/article/details/79144773)
(转自https://blog.csdn.net/u011974639/article/details/79144773)
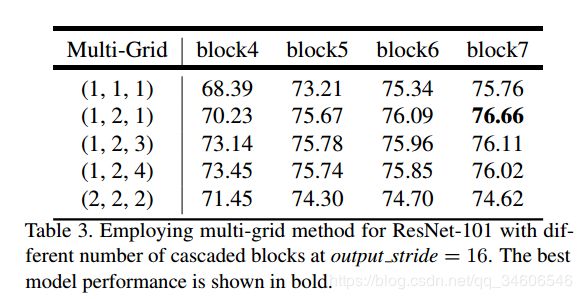
更深的atrous convolution效果更好
 应用不同策略通常比单倍数(r1,r2,r3)=(1,1,1)(r1,r2,r3)=(1,1,1)效果要好
应用不同策略通常比单倍数(r1,r2,r3)=(1,1,1)(r1,r2,r3)=(1,1,1)效果要好
简单的提升倍数是无效的(r1,r2,r3)=(2,2,2)(r1,r2,r3)=(2,2,2)
最好的随着网络的深入提升性能.即block7下(r1,r2,r3)=(1,2,1)(r1,r2,r3)=(1,2,1)
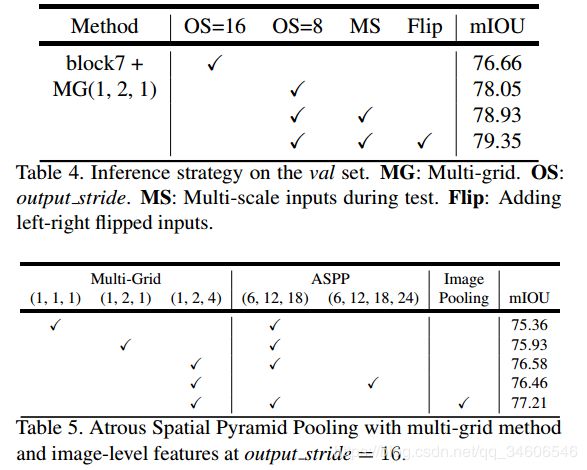
!
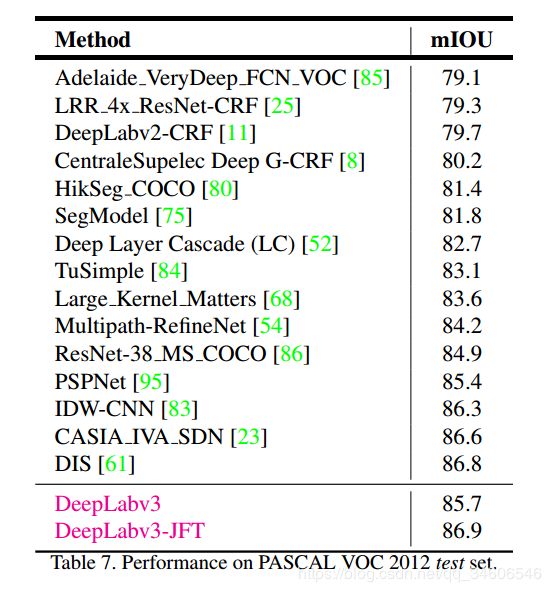
 VOC2012不同方法的比较:
VOC2012不同方法的比较:
 Cityscapes数据集上的比较:
Cityscapes数据集上的比较:



