StyleGAN阅读笔记和源码阅读
StyleGAN以Style为名,有两个含义:1. 借鉴在风格迁移中常用到的adain操作。2. 通过adain 把不同层次的样式(style)embed到不同分辨率的特征图上,能够影响不同层次(level)的生成图像的样式。高级层次有人脸的姿态,脸型,发型等宏观的样式,低级点的有细小的细节风格(脸的细节,像源A还是源B,),眼镜。
StyleGAN以渐进式GAN为baseline,通过改进了一些方面,来生成高清(1024*1024)逼真的人脸图像。
这些改进主要有:
- 改进渐进GAN的上采样层和超参数
- 添加了maping学习W空间,用于产生样式
- 移除其他GAN的输入方式
- 添加noise input
- 采用mixing regularization
其中后四项(黑体)是比较重要的改进。我就按照这几个部分分别讲述。
独立的mapping network
传统的GAN,把噪声Z送到generator中,一步一步上采样得到生成图像。然后Z的不同控制生成图像的多样性。同时如果想控制生成图像,就在中间卷积层或者输入层上concat一个属性的编码。作者认为这种结构没有让latent space之间的不同属性解纠缠(解耦)。意思就是如果一个人是否是长发,和这个人是否是女性无关,但因为数据集的关系,传统的gan,生成女性的人脸图,基本是长发的。但stylegan,可以做到精准打击,可控生成图像的每个样式。
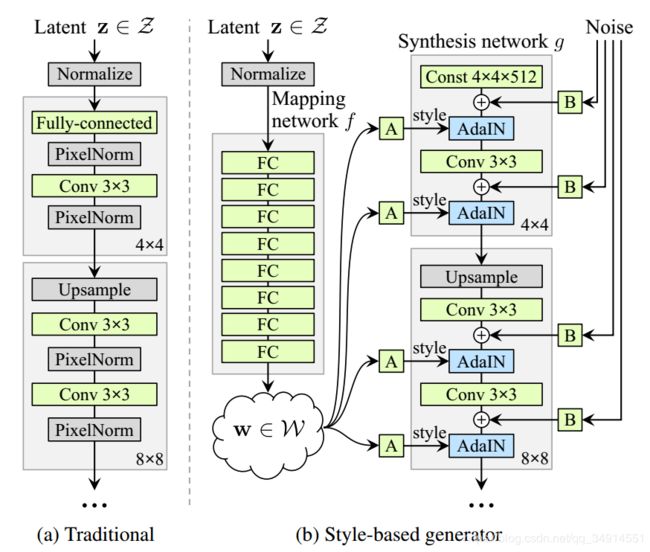
左图是传统的生成器结构,右边是stylegan的生成器。具体来说,stylegan把z输入到一个maping结构中,得到另一个隐空间W,是一个512维向量。而mapping网络是一个8层的MLP。z要经过L2 norm才能送到这个MLP中。
然后W空间的特征向量,经过一个A(affine transform,另一个FC层)得到样式(gamma, beta)。把该样式用adain,embed到卷积特征图中(用gamma作为新的均值,用beta作为方差)
**adain最开始应该是ECCV18那篇任意风格迁移的论文提出的,之前看过。**然后Adain还在AdaptIS(实例分割)中采用过。AdaptIS我也介绍过。
移除传统GAN的输入层
Z一般是均值分布的噪声输入,传统的gan是把z送到生成器中。而styleGAN发现,当已经把z独立出来之后,生成器的输入不在依赖于噪声输入,故换成一个constant tensor会更加好。 在论文的附加材料中, 写到他们用了一个learned constant tensor,初始化为1,参与训练。
添加噪声
作者在Adain之前,引入了输入噪声。这个噪声是每个通道上都有一个噪声,然后在空间维度上expand。但噪声加到特征图之间,要先经过一个训练参数scale。
采用mixing regularization
为了让styleGAN更进一步解耦样式之间的联系,作者还使用了混合正则化。具体来说,先送入z1,z2进入mapping,得到w1, w2。 然后交叉使用w1和w2,依次送入不同的adain中。这样的话避免了一个问题,即,只用w1提供的样式,会不会网络认为相邻的adain所控制的风格是有关系的。
何为样式的层次性(层级)

作者用了10个z得到10张生成图像,然后其中5个组成源A, 剩下5个组成源B。 然后用源B对应的w,输入到低分辨率的特征图上使用的admin中。发现生成的图像,发型这些高级风格采用的是来自B的样式。 如果只在中等大小的特征图上用源B的样式,用adain嵌入到特征图中,则改变的是是否带眼睛,鼻子,嘴型,等较细的样式,同时发现高级样式已经保留下来了(采用的还是源A),比如脸的姿态,性别等。如果再更高的特征图上采用源B的样式,则改变的仅仅是细节的东西。比附肤色,头发的颜色(发型没有被改变)
其他部分
作者还有一系列更加详细的实验和分析,同时给出了一个新的人像数据集FFHQ。这里就不多介绍。
源码剖析
我阅读的是第三方实现,基于Pytorch的,源作者在readme里面给出了训练结果,是比较接近官方实现的,反响也比较好,应该是目前最好的pytorch实现了吧
pytorch实现
mapping网络结构, 8层MLP
layers = [PixelNorm()]
for i in range(n_mlp):
layers.append(EqualLinear(code_dim, code_dim))
layers.append(nn.LeakyReLU(0.2))
self.style = nn.Sequential(*layers)
AdaIN
class AdaptiveInstanceNorm(nn.Module):
def __init__(self, in_channel, style_dim):
super().__init__()
self.norm = nn.InstanceNorm2d(in_channel) # affine 默认为False
self.style = EqualLinear(style_dim, in_channel * 2) # 论文中的Affine
self.style.linear.bias.data[:in_channel] = 1 #分两半
self.style.linear.bias.data[in_channel:] = 0
def forward(self, input, style):
style = self.style(style).unsqueeze(2).unsqueeze(3) # W的特征向量经过Affine
gamma, beta = style.chunk(2, 1) # 方差,均值 split
out = self.norm(input) # 归一化
out = gamma * out + beta # 反归一化
return out
class NoiseInjection(nn.Module):
def __init__(self, channel):
super().__init__()
# 论文中的scale,初始化为0
self.weight = nn.Parameter(torch.zeros(1, channel, 1, 1))
def forward(self, image, noise):
return image + self.weight * noise
输入层
class ConstantInput(nn.Module):
def __init__(self, channel, size=4):
super().__init__()
# 我记得论文中是初始化为1 是一个learned constant input 所以用parameter封装,是要参与训练的。
self.input = nn.Parameter(torch.randn(1, channel, size, size))
def forward(self, input):
batch = input.shape[0] # 只需要batchsize这个信息
out = self.input.repeat(batch, 1, 1, 1)
return out
还有一些细节我也没看懂,等用的时候在细究一下。比如还有训练方式,GAN的训练过程需要非常细心,所以训练代码有空也要好好读一下。