ClouderaManager问题解决方案
1、集群中出现多个重复机器
解除所有机器授权,remove from cloudera-manager,再将集群cluster和管理删除。在首页点击添加集群。依次执行安装步骤
2、安装失败,无法接受agent发出的检测信号

1、首先检查hostname和hosts文件配置是否正确
2、如果正确,查看/var/log/cloudera-scm-agent/下的agent的日志,发现:Failed to connect to previous supervisor。
3、删除/var/lib/cloudera-scm-agent 目录下 的uuid 和response.avro文件。
4、重启agent,点击重试按钮。
3、安装agent时出现连接不上的问题
查看http服务启动了没有。如果一直请求的是阿里云的镜像,只需把本机的ip配成阿里云就好了。等安装完成后,再把配置删掉即可。
4、Error:JAVA_HOME is not set and cound not bu found
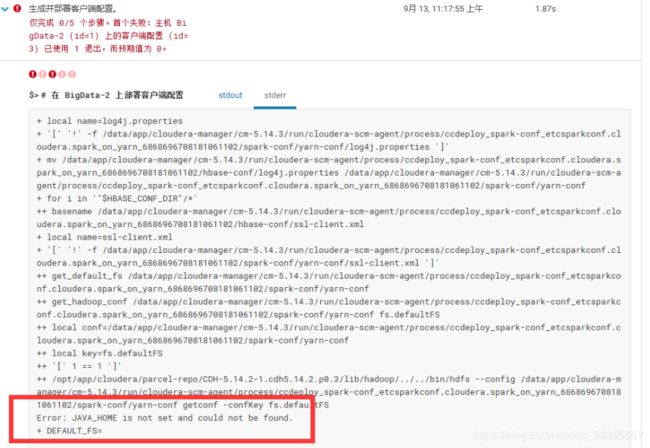
打开cloudera-manager主界面,配置每一台主机的java_home。
5、安装hdfs时出现问题

如果在安装hdfs时出现问题 ,一般都是namenode或datanode目录不为空造成的。删除相应的目录下的所有文件即可。
6、 Failed to load driver
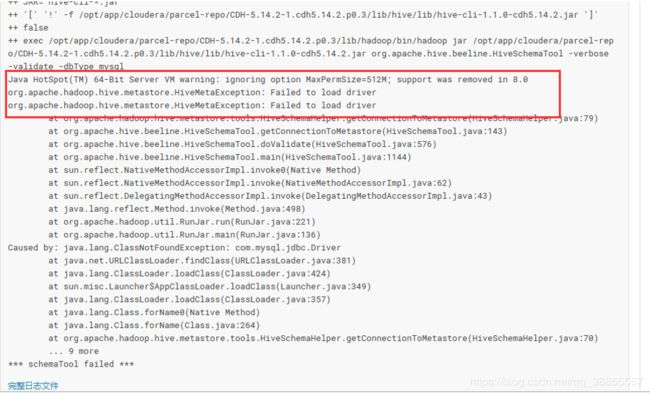
在/opt/cloudera/parcels/CDH-5.4.7-1.cdh5.4.7p0.36/lib/hive/lib(不同版本和安装方式的目录不一样)目录下将MySQL的驱动包拷贝过去。
如果遇到其他组件的问题相似的,解决方法相同。
实在是找不到mysql驱动的,把驱动所在的/usr/share/java目录配到环境变量上
7、Yarn集群的一个nodemanager报错:org.fusesource.leveldbjni.internal.NativeDB$DBException:Corruption:1 missing files;e.g:/var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/001193.sst
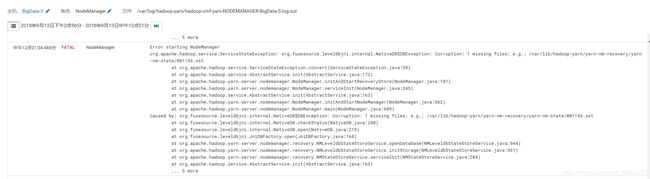
删除该机器/var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state下的所有文件,重启节点即可。
8、Failed to open or create partition
com.cloudera.cmon.tstore.leveldb.LDBPartitionManager$LDBPartitionException: Unable to open DB in directory /var/lib/cloudera-service-monitor/ts/stream/partitions/stream_2018-12-09T11:17:37.845Z for partition LDBPartitionMetadataWrapper{tableName=stream, partitionName=stream_2018-12-09T11:17:37.845Z, startTime=2018-12-09T11:17:37.845Z, endTime=null, version=2, state=CLOSED}

进入master的/var/lib/文件夹下,将
cloudera-service-monitor文件夹重命名,之后重启Cloudera Management Service
9、ClassNotFoundException HiveHBaseTableInputFormat
java.lang.ClassNotFoundException: org.apache.hadoop.hive.hbase.HiveHBaseTableInputFormat

export SPARK_DIST_CLASSPATH=$SPARK_DIST_CLASSPATH:/opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/lib/hive/lib/*:/opt/hnreport/mysql_jar/mysql-connector-java-5.1.24.jar
10、check your cluster UI to ensure that workers are registered and have sufficient resources
(1)内存不够,增大内存
(2)检查ip与主机名是否映射,没有的话修改然后重启。
vi /etc/hosts
192.168.235.128 localhost.localdomain localhost
reboot
11、Required executor memory (1024+384 MB) is above the max threshold (1046 MB) of this cluster!
Exception in thread "main" java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the max threshold (1046 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
修改yarn的容器内存和最大容器内存
12、ERROR CoarseGrainedExecutorBackend: Driver 192.168.230.135:45970 disassociated! Shutting down.
加大excutor-memory的值,减少executor-cores的数量,问题可以解决。
13、 KeeperErrorCode = ConnectionLoss for /hbase/hbaseid
连接Hbase时,配置如下:
hbase.rootdir=hdfs://host:9000/hbase
hbase.zookeeper.quorum=host01,host02,host03
hbase.client.scanner.timeout.period=120000
hbase.rpc.timeout=60000
报错:
ERROR zookeeper.ZooKeeperWatcher:hconnection-0x5c7bd3cb0x0,quorum=xxx:2181,xxx:2181,xxx:2181,xxx:2181,xxx:2181,baseZNode=/hbase Received unexpected KeeperException, re-throwing exception
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase/hbaseid
查看Hbase配置:
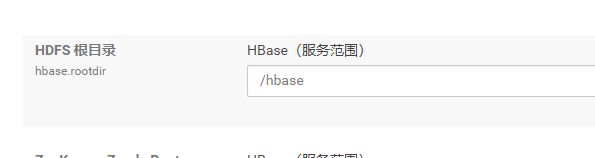
检查zookeeper- quorum