Python数据分析入门笔记——实战房价分析
Python数据分析学习入门四——房价分析
- 房价预测
- 导入数据,查看数据结构和类型
- 倒入项目所需的包
- 将划分好的数据导入分析
- 简单查看训练集数据
- 查看每列的数据类型
- 查看因变量y的分布,处理极值
- 查看数据基本情况
- 画出直方图,直观查看数据
- 对y值进行优化
- 查看特征值x的情况,处理缺失值
- 查看特征值
- 处理缺失值
- 查看特征x与因变量y的关系
- 分析'GrLivArea'对y的影响:
- 分析TotalBsmtSF对y的影响:
- 分析OverallQual对y的影响
- 分析YearBuilt对y的影响
- 训练模型,判断优劣
- 引入线性回归模型,训练模型
- 传入特征集,训练模型
- 查看回归系数对y的影响
- 训练值和真实值对比
- 引入测试集,测试y值
- 总结
房价预测
导入数据,查看数据结构和类型
倒入项目所需的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。 它也可以和图形工具包一起使用,如 PyQt 和 wxPython。
将划分好的数据导入分析
首先导入项目所需的包,以及训练集和数据集两个文件。
df_train = pd.read_csv("train.csv")
df_test = pd.read_csv("test.csv")
print(df_train.shape)
print(df_test.shape)
(1460, 81)
(1459, 80)
测试集比训练集少一列,因为测试集的的因变量y是需要我们通过训练集算出来的.
我们在测试集中删去了 y 这一列的数据,因为在整个机器学习的过程中,测试集相当于是未来的信息, 而我们需要通过现在有的数据(也就是训练集)来训练一个模型, 使它可以更为准确地预测未来的结果。因此,我们在做分析的时 候,不能把测试集的数据流入进训练集中。
简单查看训练集数据
df_train.head()
输出结果:

结果输出前五列.
查看每列的数据类型
df_train.dtypes
输出结果:

其中OverallQual的数据的数据类型是int64,但实际上它只是一个表示房子登记的数据由一道十,所以并没有实际的量化意义,所以将它改为object类型的.
df_train['OverallQual'].dtype
dtype('int64')
............................................
df_train['OverallQual'] = df_train['OverallQual'].astype('object')
df_train['OverallQual'].dtype
dtype('O')
最后输出了’O’就代表以及改为object类型了.
在数据处理的时候,要注意每一列的实际意义和它的数据类型是否符合.
查看因变量y的分布,处理极值
查看数据基本情况
可以用describe查看基本的数据情况
df_train['SalePrice'].describe()
count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
可以用hist()画出直方图,查看y的值,看是否有极大值或极小值,以及数据是否符合正态分布.
画出直方图,直观查看数据
plt.hist(df_train['SalePrice'], bins = 100, normed = 0, facecolor="steelblue",edgecolor="black", alpha = 0.7)
plt.xlabel("house price")
plt.ylabel("frequency")
plt.title("House Price Distribution")
plt.show()
输出结果:

对y值进行优化
虽然y不符合正态分布,但是基本是很少有极大值或者极小值,说明y的数据还是不错的,如果y有很多极大值或者极小值,那就需要设定一个极大值的限制和极小值的限制.
查看特征值x的情况,处理缺失值
查看特征值
可以简单查看一下一些列,将明显不是特征值的列去掉.
features.remove('Id')
features.remove('SalePrice')
len(features)
79
处理缺失值
先可以计算出每一列的缺失值,将缺失值比较多的列找出来,看一下,看是否是数据本身的问题,如果数据本身对y的影响大,那就必须得找到这些缺失值,如果对y的影响不大,就可以将这些值直接从特征值去掉.
features = df_train.columns.tolist()
total = df_train[features].isnull().sum().sort_values(ascending = False)
percent = (df_train[features].isnull().sum()/df_train[features].isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total,percent],axis=1,keys=['Total','Percent'])
missing_data[missing_data['Percent']>0.4]
输出结果:

查看特征x与因变量y的关系
最后找出四个对建立模型比较有用的特征:‘SalePrice’,‘GrLivArea’,‘OverallQual’,‘TotalBsmtSF’,‘YearBuilt’.
df_train = df_train[['SalePrice','GrLivArea','OverallQual','TotalBsmtSF','YearBuilt']]
分析’GrLivArea’对y的影响:
plt.scatter(df_train['GrLivArea'],df_train['SalePrice'])
plt.xlabel('GrLivArea')
plt.ylabel('SalePrice')
plt.show()
输出结果:
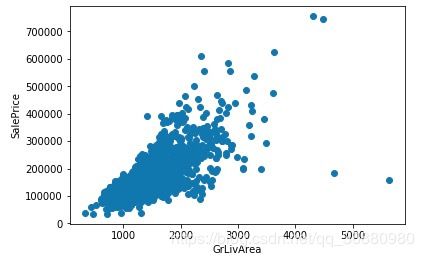
生活面积越大,房价越贵,是一个好的特征.
分析TotalBsmtSF对y的影响:
plt.scatter(df_train['TotalBsmtSF'], df_train['SalePrice'])
plt.xlabel('TotalBsmtSF')
plt.ylabel('SalePrice')
plt.show()
输出结果:

地下室面积越大,房价越贵,是符合认知的.
分析OverallQual对y的影响
import seaborn as sns
fig = sns.boxplot(x='OverallQual',y="SalePrice",data=df_train)
fig.axis(ymin=0,ymax=800000);
plt.show()
输出结果:

由于评分不是一个可以量化的数据,这里用到了箱形图来看总体的评分和价格的关系,基本上也是符合房子的评分越高,房价越贵的原则,是一个符合现实情况的数据.
这里在训练的时候需要处理一下OverallQual的数据:
我们要把分类变量改成哑变量(dummy variable)。dummy variable, 即虚拟变量,又称虚设变量、名义变量或哑变量,用以反映质的属性 的一个人工变量,是量化了的质变量,通常取值为 0 或 1。引入哑变 量会使线形回归模型变得更复杂,但对问题描述更简明,一个方程能 达到两个方程的作用,而且接近现实。例如,反映文凭程度的虚拟变 量可取为:1:本科学历;0:非本科学历。在回归模型中,哑变量的 前面也有一个系数,这代表哑变量取值 1 相对于 0,会对因变量产生 怎样的量化效应。
这里我们把OverallQual改成哑变量.
df_train = pd.concat([df_train,pd.get_dummies(df_train['OverallQual'],prefix='F_OverallQual')],axis=1)
df_train[df_train['OverallQual']==1]

分析YearBuilt对y的影响
fig = sns.boxplot(x='YearBuilt',y="SalePrice",data=df_train)
fig.axis(ymin=0,ymax=800000);
plt.savefig("yearbuilt.png",dpi = 180)
plt.show()
输出结果:

这里由于建造年份也不是可以量化的数据,这里也需要使用箱形图来描绘,当然,年份也需要转化为哑数据,但是这么多个年份全部转化为哑数据不太现实,这里有两种方法:
1.是根据年份重新分类,比如从 1980 开始,每 10 年为一组,再用新的分组来 建成哑变量;
2.是根据今年,计算房屋年龄,年龄这个数据是有量化 意义的,可以直接放进线性模型中。
这里我们运用第二种方法.
df_train["BuiltAge"] = 2019-df_train["YearBuilt"]
plt.scatter(df_train["BuiltAge"],df_train["SalePrice"])
plt.xlabel("BuiltAge")
plt.ylabel("SalePrice")
plt.show()
输出结果:

这里看到整体的趋势是往下的.
既然已经处理过年份以及房子质量的数据了,并且处理过的数据有效,就可以把原来列的数据去掉,使用新的列来表示df_train.
features = df_train.columns.tolist()
#features为特征集,为有效的数据列,所以saleprice不能留在特征集中
features.remove("OverallQual")
features.remove("YearBuilt")
features.remove("SalePrice")
len(features)
13
..................................
print(features)
['GrLivArea', 'TotalBsmtSF', 'F_OverallQual_1', 'F_OverallQual_2', 'F_OverallQual_3', 'F_OverallQual_4', 'F_OverallQual_5', 'F_OverallQual_6', 'F_OverallQual_7', 'F_OverallQual_8', 'F_OverallQual_9', 'F_OverallQual_10', 'BuiltAge']
训练模型,判断优劣
在处理好features以后确定了真正训练这个模型的数据,所以就可以把数据引入来训练模型了
引入线性回归模型,训练模型
from sklearn import linear_model
linreg = linear_model.LinearRegression()
传入特征集,训练模型
linreg.fit(df_train[features],df_train['SalePrice'])
#输出
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)
查看回归系数对y的影响
linreg.coef_
array([ 5.47466615e+01, 2.23642700e+01, -6.00057481e+04, -5.63928343e+04,
-5.42063862e+04, -4.44457017e+04, -3.41803083e+04, -2.51912630e+04,
-4.66414931e+03, 3.80432836e+04, 1.12705701e+05, 1.28337406e+05,
-4.73194671e+02])
引入决定系数(R square),第六节的提到,决定系数越接近于1,模型越好
linreg.score(df_train[features],df_train["SalePrice"])
#输出
0.795389742143301
训练值和真实值对比
y_pred = linreg.predict(df_train[features])#y在训练集中的预测值
y = df_train['SalePrice']#y在训练集中的真实值
plt.scatter(y,y_pred)
plt.plot([y.min(),y.max()],[y.min(),y.max()],'k--',lw=4)
plt.xlabel('Real')
plt.ylabel('Predict')
plt.show()
输出结果:
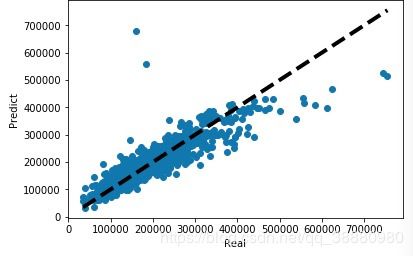
引入测试集,测试y值
#提交测试集
df_test["OverallQual"]=df_test['OverallQual'].astype('object')#改变overallqual的类型
df_test = df_test[['GrLivArea','TotalBsmtSF','YearBuilt','OverallQual',]]#过滤无用的的数据集只剩有用的几个
df_test['BuiltAge'] = 2019-df_test['YearBuilt']#处理yearbuilt,讲yearbuilt改成builtage
df_test = pd.concat([df_test,pd.get_dummies(df_test['OverallQual'],prefix='F_OverallQual')],axis = 1)#讲overallqual处理成哑变量
总结
1)数据类型一定要对;
2)要看数据的分布,对特征要有了解,如果分布不好要做极值处理;
3)不是每个特征都可以直接用原数据放入模型中,要对分类变量进 行一些处理;
4)如何判断哪个特征的修改比较有用 1从模型的表现 2特征的表现 3特征/模型的维护容易程度,比如房子年龄这个变量在今年做是这样,在明年分析就要重新计算一遍,这种情况下可能用第一种方法处 理会比较好;
5)特征表现和预期不符,不一定代表该特征不好,首先可以看是否处理错了这个特征,然后可以看是否和区域特性有关,也可能真的挖掘出了一些你想不到的东西,可以透过现象看到本质原因。